W AWS Deep Racer wytrenowałem ponad 80 modeli i w tym poście chciałbym ci pokazać moje doświadczenia. Budowałem różne modele samochodów z różnymi parametrami takimi jak architektura sieci neuronowej maksymalna prędkość czy też maksymalny kąt skrętu kierownicy. Dość daleko doszedłem na domyślnym pojeździe który ma ograniczenie prędkości maksymalnie 1 m/s. Najszybszy pojazd jaki można stworzyć może jechać 4 m/s natomiast prędkość jest ustalana przez model jest jako klasyfikacja (prędkość jest skwantowana) i tutaj maksymalnie możesz mieć 3 kategorie, także minimalna prędkość dla takiego modelu to 1.33 m/s. Trenowanie szybszych modeli wymaga modyfikacji funkcji nagrody, gdyż samochód przy wyższych prędkościach potrafi wpadać poślizgi i tutaj faktycznie trzeba się na starać by jechał on po trasie. W tych wszystkich moich próbach udało mi się również znaleźć błędy w symulatorze kiedy coś złego dzieje się z kołami pojazdu i symulacja cały czas się restartuje. Być może jest to związane z tym co próbuje zrobić pojazd natomiast wydaje mi się to dość nienaturalne.
W poprzednim poście pokazałem ci jak wytrenować podstawowy model tak aby nie być na ostatnim miejscu w wyścigu majowym. W tym poście pokażę Ci jak poprawić swoje wyniki budując własny pojazd.
Budowa własnego pojazdu
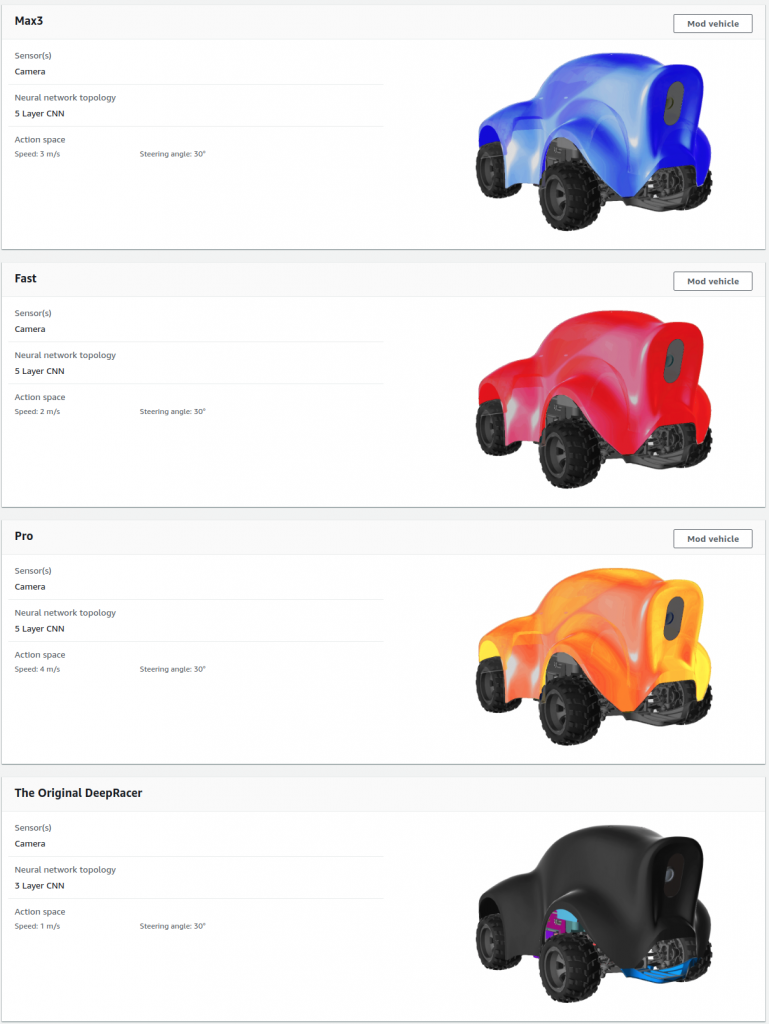
Budowa nowego pojazdu rozpoczyna się od wyboru sensorów. do wyboru mamy kamerę zwykłą bądź kamerę stereowizyjną i dodatkowo możemy dodać do pojazdu Lidar co mogłoby się przydać w zadaniach wykrywania obiektów na torze w celu omijania przeszkód. jako że skupiłem się na zadaniu Time Trial w każdym z moich modeli wybrałem tylko pojedynczą kamerę.Poniżej screenshot z wizualizacją tego wyboru.

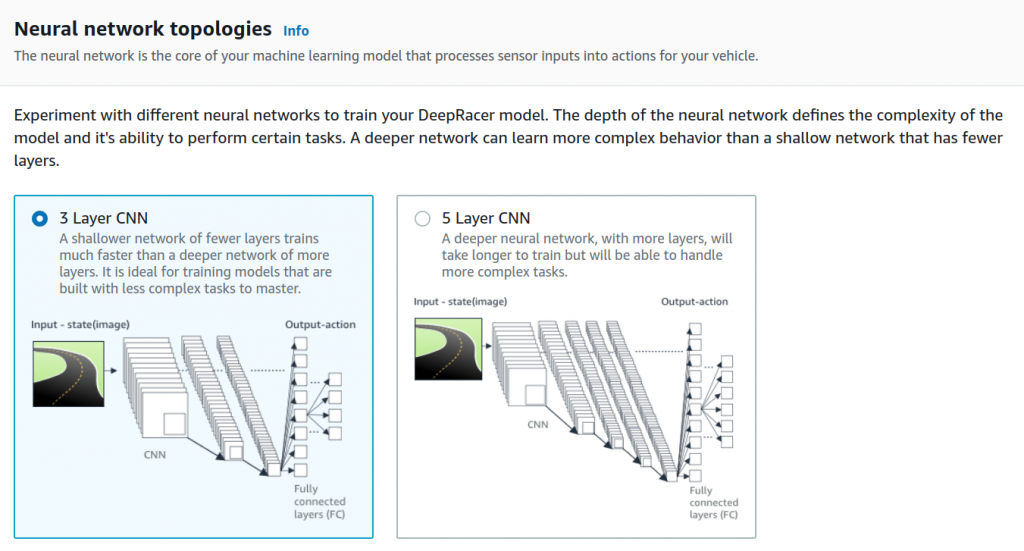
W drugim kroku możesz wybrać ile warstw będzie miała Twoja sieć neuronowa i tutaj są dwie opcje 3 albo 5. Początkowo próbowałem modeli z pięcioma warstwami natomiast nie byłem w stanie wytrenować żadnej sieci by kierowała pojazdem i była w stanie przyjechać chociaż jedno okrążenie. Dlatego też wszystkie moje modele obecnie zostały zmodyfikowane tak by mieć trzy warstwy. To co mogę polecić to nie zaczynaj od razu od sieci z pięcioma warstwami, dużo trudniej jest ją wytrenować. Spróbuj raczej uzyskać jak najlepsze wyniki używając trzech warstw i dopiero wtedy gdy będziesz mieć problemy spróbuj skorzystać z większej sieci. Sieć z pięcioma warstwami przyda się zdecydowanie w przypadku wykorzystania kamery stereo.
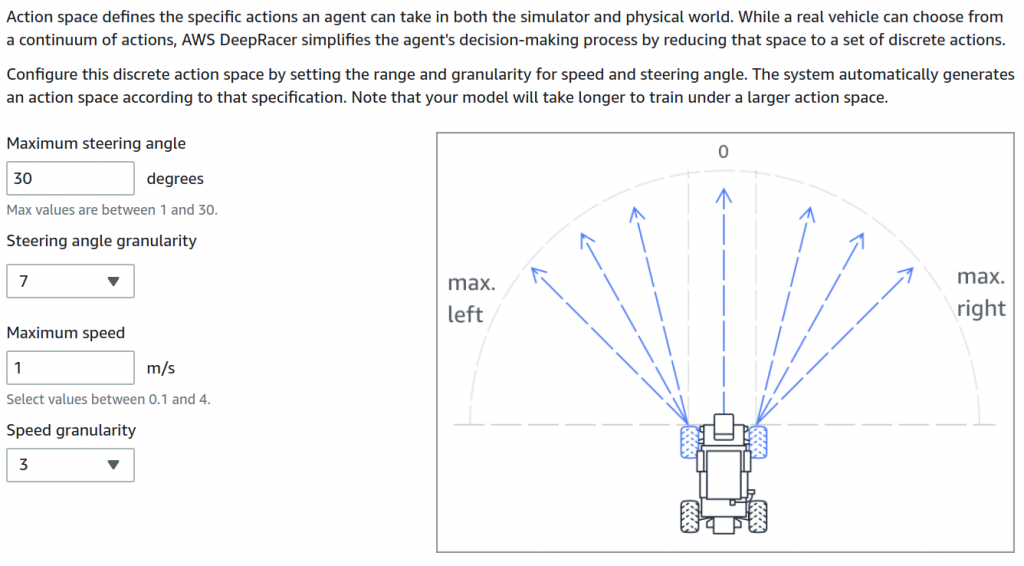
Przestrzeń akcji i pojazdu jest ograniczona zarówno jeśli chodzi o prędkość jak i o kąt skrętu w kierownicy. Obie wartości są skwantowane. w przypadku kąta skrętu możemy mieć 3, 5 bądź 7 wartości, a maksymalny kąt skrętu to +/- 30 stopni. Gdy wybierzemy 7 oraz 30 stopni uzyskamy 7 możliwych ustawień kierownicy od -30 do +30 co 10 stopni. Takie ustawienie stosuje w każdym moim modelu. Natomiast w przypadku maksymalnej prędkości możemy ją ustawiać od 0.1 do 4 m/s płynnie. Ja korzystałem z okrągłych wartości taki jak 2, 3, 4. Kwantyzacja prędkości to 1, 2 lub 3 poziomy. Wybierając 3 poziomy dla maksymalnej prędkości 3 m/s otrzymamy 1, 2, 3 m/s. Kombinacja siedmiu możliwych kątów skrętu kierownicy oraz trzech możliwych poziomów prędkości daje nam 21 możliwych akcji do wykonania przez pojazd w każdej chwili czasu.Oryginalny pojazd The Original DeepRacer korzysta ze zwykłej kamery maksymalna prędkość 1 m/s, maksymalny kąt skrętu kierownicy 30 stopni i przestrzeń stanu ograniczoną do 9 kombinacji czyli trzy poziomy dla skrętu oraz trzy poziomy prędkości. trzy poziomy kąta skrętu przy +/- 30 stopniach oznacza -30, 0, +30.
Ostatni krok przygotowania Twojego modelu to nadanie mu nazwy oraz wybór koloru. Wybrać Możesz jeden z siedmiu kolorów, mój faworyt to pomarańczowy, taki też kolor otrzymał mój najszybszy pojazd.

A tak oto wygląda mój garaż (jest jeszcze szary i biały; fioletowy miał być kolejny, ale się powstrzymałem gdy odkryłem, że to jednak 3 warstwy wystarczą)
Dotrenowywanie
Każdy z modeli które wytrenujemy (jeden trening trwa maksymalnie przez 24 godziny) możemy sklonować i dalej trenować. W ten sposób Nasz pojazd może zdobyć więcej niż 24 godziny doświadczenia. Aby to zrobić należy wybrać opcję Clone w wytrenowanym już modelu. Można to zrobić zarówno w przypadku gdy trening skończy się naturalnie, poprzez koniec czasu albo gdy trening zaczynamy ręcznie.

Dobre wyniki
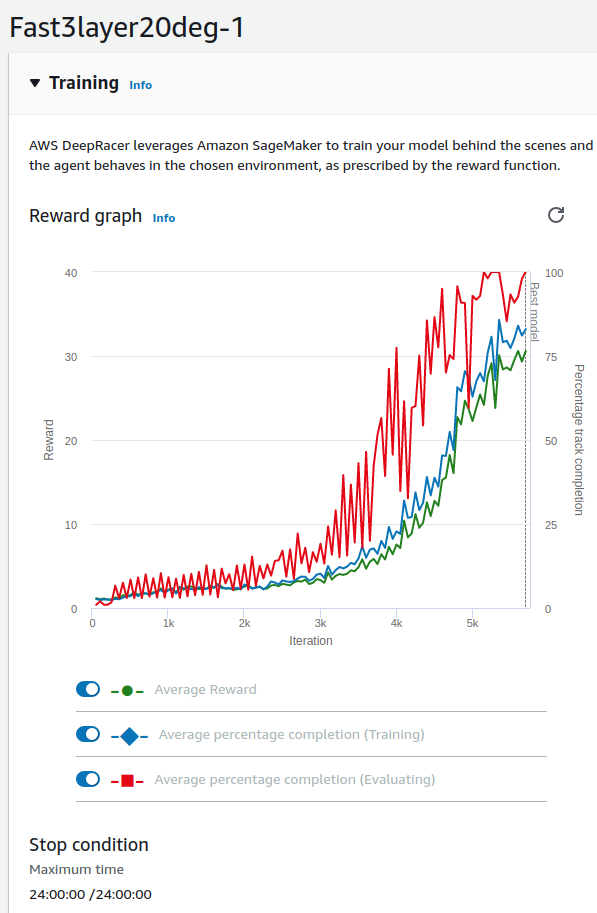
Sądziłem że uda mi się zaprezentować tutaj całą historię zmian modeli natomiast pokażę po prostu model który zadziałał i obecnie jest najlepszym z moich modeli. Problem w DeepRacerze jest taki, że nie wiadomo jaki model pojazdu został wybrany do trenowania sieci, tego nie widać. Nazwa mojego modelu sugeruje iż maksymalny kąt skrętu to było 20 stopni natomiast nie jestem tego taki pewien, gdyż przy próbie klonowania tego modelu wybiera się pojazd który ma max 30 stopni. Może to wynikać z modyfikacji, które nastąpiły w międzyczasie natomiast przestrzegam, że może się pojawić problem. Miałem pomysł by nazywać każdy z modeli trenowanych z nazwą pojazdu w nazwie modelu natomiast nie otrzymałem tej systematyczności. Jedno jest pewne – ten ma maksymalną prędkość 3 m/s!
| Action number | Steering | Speed |
|---|---|---|
| 0 | -30degrees | 1m/s |
| 1 | -30degrees | 2m/s |
| 2 | -30degrees | 3m/s |
| 3 | -20degrees | 1m/s |
| 4 | -20degrees | 2m/s |
| 5 | -20degrees | 3m/s |
| 6 | -10degrees | 1m/s |
| 7 | -10degrees | 2m/s |
| 8 | -10degrees | 3m/s |
| 9 | 0degrees | 1m/s |
| 10 | 0degrees | 2m/s |
| 11 | 0degrees | 3m/s |
| 12 | 10degrees | 1m/s |
| 13 | 10degrees | 2m/s |
| 14 | 10degrees | 3m/s |
| 15 | 20degrees | 1m/s |
| 16 | 20degrees | 2m/s |
| 17 | 20degrees | 3m/s |
| 18 | 30degrees | 1m/s |
| 19 | 30degrees | 2m/s |
| 20 | 30degrees | 3m/s |
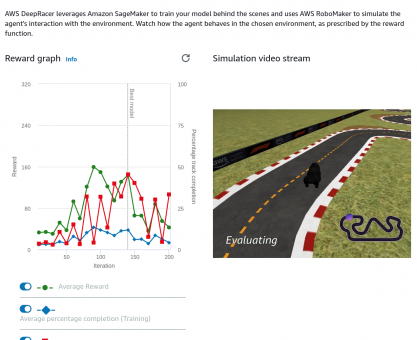
Poniżej jest obecnie najlepszy model. pokazując zarówno przebieg treningu, funkcję nagrody, jak i wybrane hiperparametry.
Funkcja nagrody tegoż modelu:
def reward_function(params):
'''
Example of rewarding the agent to follow center line
'''
import math
# Read input parameters
track_width = params['track_width']
distance_from_center = params['distance_from_center']
track_width = params['track_width']
steering = params['steering_angle'] # Only need the absolute steering angle
all_wheels_on_track = params['all_wheels_on_track']
progress=params['progress']/100.0
is_reversed=params['is_reversed']
is_offtrack = params['is_offtrack']
speed=params['speed']
steps=params['steps']
x=params['x']
y=params['y']
waypoints = params['waypoints']
closest_waypoints = params['closest_waypoints']
heading = params['heading']
# Calculate the direction of the center line based on the closest waypoints
next_point = waypoints[closest_waypoints[1]]
prev_point = waypoints[closest_waypoints[0]]
next_wp_id = closest_waypoints[1] + 1
if next_wp_id>=len(waypoints):
next_wp_id=0
next_point = waypoints[next_wp_id]
track_direction = math.atan2(next_point[1] - prev_point[1], next_point[0] - prev_point[0])
track_direction = math.degrees(track_direction)
direction_diff = abs(track_direction - heading)
if direction_diff > 180:
direction_diff = abs(360 - direction_diff)
dir_from_here_to_next = math.atan2(next_point[1] - y, next_point[0] - x)
dir_from_here_to_next = abs(math.degrees(dir_from_here_to_next) - heading)
if dir_from_here_to_next > 180:
dir_from_here_to_next = abs(360 - dir_from_here_to_next)
if is_reversed or is_offtrack or not all_wheels_on_track:
return 1e-4
reward = 1e-3 + speed *0.1
if distance_from_center<0.25*track_width:
reward+=0.1
if dir_from_here_to_next<1:
reward += 1
if direction_diff<1:
reward += 1
if abs(steering)>5:
reward *= 0.6
return float(max(1e-5,reward*0.1))
Pokrótce chciałbym Ci przybliżyć co się dzieje w moim kodzie funkcji nagrody. W pierwszym kroku przepisuje wszystkie parametry które otrzymuje z symulatora. Korzystam z kolejnego punktu na trasie natomiast wybieram jeszcze o 1 dalszy next_wp_id. W ten sposób chcę zaimplementować technikę Pure Pursuit. Dla tak wyznaczonego punktu na trasie obliczamy kierunek w jego stronę z pozycji w której znajduje się pojazd oraz wyznaczam kierunek drogi na podstawie poprzedniego punktu oraz tego mojego następnego. Liczę różnice kierynku w którym jedzie pojazd z tymi dwoma kierunkami. W mojej funkcji nagrody najpierw sprawdzam, czy pojazd nie jedzie do tyłu, nie jest poza trasą i czy ma wszystkie koła na trasie. Jeśli te warunki nie są spełnione zwracana jest wartość 1e-4. Nagroda zależy od prędkości z mnożnikiem 0.1. Do tego dodawana jest nagroda 0.1 za znajdowanie się w pobliżu linii środkowej drogi. Dodatkowo są dwie nagrody za małą wartość kąta pomiędzy naszym kierunkiem pojazdu a kierunkiem drogi oraz kierunkiem pojazdu a kierunkiem do następnego waypointa. Gdyby tego było mało, jest jeszcze kara za zbyt duży kąt skrętu kierownicy większy niż 5 stopni. Ta kara zmniejsza nagrodę o jedną trzecią wartości. Na koniec nagroda jest mnożona jeszcze przez 0.1. Upewniam się dodatkowo czy nagroda jest większa od zera czyli nie mniejsza niż 1e-5. Wynika to z wielu testów, które wykonywałem między innymi z odejmowania liczby kroków przemrożonej przez mnożnik, ale tego nie ma w tym modelu.
Hiperparametry treningu:
| Hyperparameter | Value |
|---|---|
| Gradient descent batch size | 512 |
| Entropy | 0.01 |
| Discount factor | 0.999 |
| Loss type | Huber |
| Learning rate | 0.0001 |
| Number of experience episodes between each policy-updating iteration | 50 |
| Number of epochs | 10 |
Poniżej widać ranking, na którym jest informacja, że najlepszy model to ten powyższy. Próbowałem go klonować i poprawić wynik natomiast ciągle wynik był gorszy.
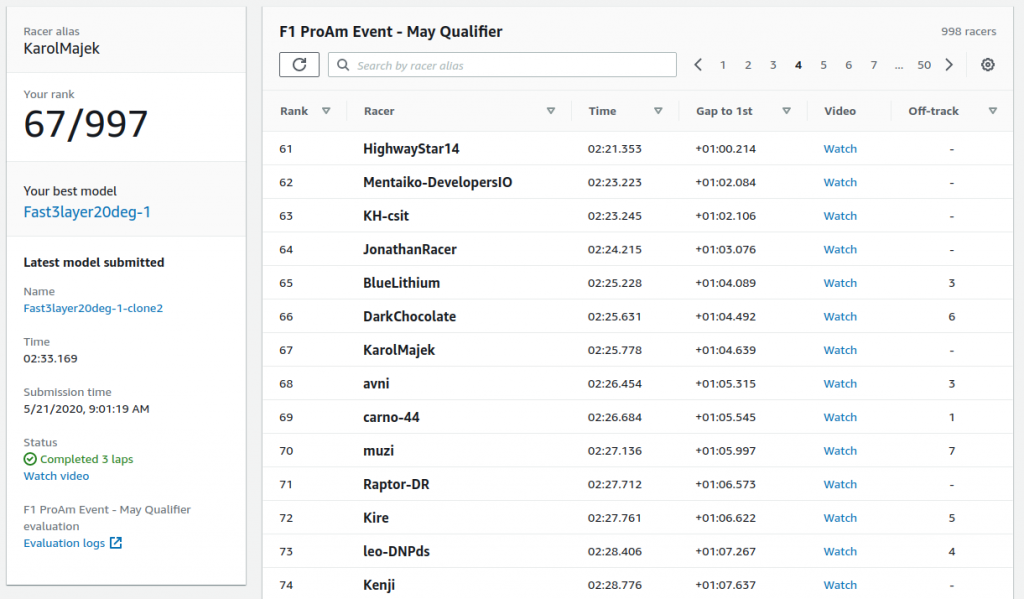
A poniżej możesz obejrzeć jak pojazd radzi sobie na torze. Jest o minutę wolniejszy niż pierwsze miejsce.
Dalsze próby
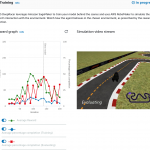
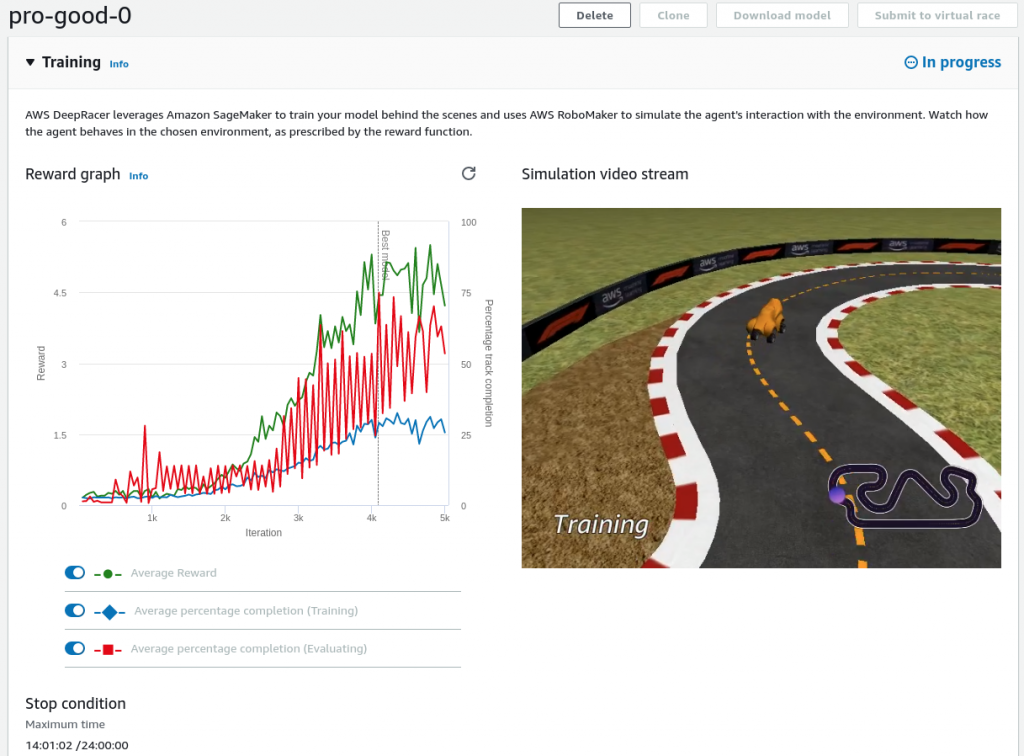
Obecnie wciąż walczę by trenować najszybszy pojazd, ten z maksymalną prędkością 4 m/s, tak by był w stanie przejechać całą trasę bez problemu i wystartować w zawodach. Od razu podzielę się parametrami z których skorzystałem bo wyniki wyglądają naprawdę obiecująco. Poniżej screenshot z jeszcze trwającego treningu widokiem z symulacji (zauważ, że pojazd jest pomarańczowy tak jak wspomniałem, to jest mój najlepszy, najszybszy).
Poniżej zamieszczam wykorzystywaną przeze mnie funkcje nagrody, ma ona kilka usprawnień. Do nagrody dodawany jest progress zależny od zaawansowania. Drugi dodatek to kara za zbyt duży kąt względem kierunku drogi lub zbyt duży kąt względem następnego punktu na drodze.
def reward_function(params):
'''
Example of rewarding the agent to follow center line
'''
import math
# Read input parameters
track_width = params['track_width']
distance_from_center = params['distance_from_center']
track_width = params['track_width']
steering = params['steering_angle'] # Only need the absolute steering angle
all_wheels_on_track = params['all_wheels_on_track']
progress=params['progress']/100.0
is_reversed=params['is_reversed']
is_offtrack = params['is_offtrack']
speed=params['speed']
steps=params['steps']
x=params['x']
y=params['y']
waypoints = params['waypoints']
closest_waypoints = params['closest_waypoints']
heading = params['heading']
# Calculate the direction of the center line based on the closest waypoints
next_point = waypoints[closest_waypoints[1]]
prev_point = waypoints[closest_waypoints[0]]
next_wp_id = closest_waypoints[1] + 1
if next_wp_id>=len(waypoints):
next_wp_id=0
next_point = waypoints[next_wp_id]
track_direction = math.atan2(next_point[1] - prev_point[1], next_point[0] - prev_point[0])
track_direction = math.degrees(track_direction)
direction_diff = abs(track_direction - heading)
if direction_diff > 180:
direction_diff = abs(360 - direction_diff)
dir_from_here_to_next = math.atan2(next_point[1] - y, next_point[0] - x)
dir_from_here_to_next = abs(math.degrees(dir_from_here_to_next) - heading)
if dir_from_here_to_next > 180:
dir_from_here_to_next = abs(360 - dir_from_here_to_next)
if is_reversed or is_offtrack or not all_wheels_on_track:
return 1e-4
reward = 1e-3 + speed *0.001 + progress*0.01
if distance_from_center<0.25*track_width:
reward+=0.1
if dir_from_here_to_next<1:
reward += 1
if direction_diff<1:
reward += 1
if abs(steering)>5:
reward *= 0.6
if direction_diff>60 or dir_from_here_to_next>60:
reward=1e-3
return float(max(1e-5,reward*0.1))
Hiperparametry treningu:
| Hyperparameter | Value |
|---|---|
| Gradient descent batch size | 512 |
| Entropy | 0.01 |
| Discount factor | 0.999 |
| Loss type | Huber |
| Learning rate | 0.00003 |
| Number of experience episodes between each policy-updating iteration | 50 |
| Number of epochs | 10 |