Ten post jest opisem doświadczeń, które nabyłam podczas uruchamiania inferencji z wykorzystaniem DETR (DEtection TRansformer). Krok po kroku omówię kod, który napisałam przy okazji swojej krótkiej przygody z tym modelem, przez co mam nadzieję przybliżyć go i Tobie oraz pokazać, że wykorzystanie go nie jest wcale trudne. W swojej pracy, oparłam się głównie na przykładzie, który udostępnił zespół facebook-research. Efekt możesz zobaczyć na filmie wrzuconym na YT.
Na początku warto wspomnieć, że w przypadku DETR maski do segmetacji powstają niejako jako skutek uboczny wykrywania obiektów (takiego zwykłego, z bounding-boxami). Generalnie jest to dość ciekawy model, bo jednym z głównych założeń jest określenie z góry, ile obiektów chcemy wykryć na zdjęciu, a przez specyficzną funkcję kosztu zniechęcamy go do tworzenia duplikatów. Jeśli ciekawi Cię, jak dokładnie działa DETR, zachęcam do przeczytania publikacji.
Zacznijmy od kwestii organizacyjnych. Jeśli chcesz, możesz na bieżąco pracować w notebooku udostępnionym na colabie.
Co robi nasz program?
Przede wszystkim wykonuje inferencję na pojedynczej klatce. Wynik z wyjścia DETR jest składany w jeden obraz razem z dwunastoma mapami aktywacji, które dają nam fajną informację, na co reaguje nasz model. Na takie zdjęcie wrzucam jeszcze kilka dodatkowych informacji: nazwę modelu, rozmiar wejścia, nazwę karty graficznej oraz czas pojedynczej predykcji.
Cała ta czynność wykonywana jest w pętli. Dlaczego? Ponieważ na wejściu mamy film. Wyniki ze wszystkich klatek zapisujemy do jednego katalogu, by potem łatwo złożyć je w video wykorzystując ffmpeg.
Import potrzebnych pakietów
W pierwszej kolejności importujemy niezbędne do przetwarzania naszych obrazów pakiety.
from copy import deepcopy
import io
import time
import os
import os.path
import cv2
import numpy as np
from tqdm import tqdm
from PIL import Image
import matplotlib.pyplot as plt
Dodatkowo doinstalowuję cmapy, które potem wykorzystam przy wizualizacji attention maps.
! pip install cmapy
import cmapy
Przyda się też pytorch i torchvision, koniecznie w wersjach 1.5 i 6.0 – inaczej pojawiają się problemy z innymi paczkami, które oczekują najnowszych wersji tych dwóch bibliotek.
! pip install torch==1.5.1+cu101 torchvision==0.6.1+cu101 -f https://download.pytorch.org/whl/torch_stable.html
import torch
from torch import nn
import torchvision.transforms as T
panopticapi pomoże nam nieco w inferencji.
! pip install git+https://github.com/cocodataset/panopticapi.git
import panopticapi
from panopticapi.utils import id2rgb, rgb2id
Potrzebujemy jeszcze pycocotools …
! pip install git+'https://github.com/cocodataset/cocoapi.git#subdirectory=PythonAPI&egg=pycocotools'
… detectron2 iii …
!pip install detectron2==0.1.3 -f https://dl.fbaipublicfiles.com/detectron2/wheels/cu101/torch1.5/index.html
from detectron2.config import get_cfg
from detectron2.utils.visualizer import Visualizer, ColorMode
from detectron2.data import MetadataCatalog
… i to już na tyle z instalacji i importów. Teraz możemy pobrać film, na którym będziemy testować model. Jeśli pracujesz w colabie, może to trochę potrwać, więc polecam urozmaicić sobie czas obejrzeniem, na czym będziemy działać.
! wget https://archive.org/download/0002201705192/0002-20170519-2.mp4
Przejdźmy w końcu do modelu
Poniżej definiuję przekształcenia, którym będą podlegały klatki z naszego filmu. Jeśli korzystasz ze swojej lokalnej maszyny, możliwe, że konieczna będzie zmiana wartości w T.Resize(1080) na mniejszą (w zależności od pamięci RAM Twojej karty graficznej).
# standard PyTorch mean-std input image normalization
transform = T.Compose([
T.Resize(1080),
T.ToTensor(),
T.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
Następnie, korzystając z torch.hub.list() możemy wyświetlić wszystkie modele dostępne w repozytorium facebookresearch/detr. W tym przypadku interesują nas wszystkie z dopiskiem panoptic.
torch.hub.list('facebookresearch/detr')
Jak widać, ja wybrałam model DETR z backbone ResNet50 (detr_resnet50_panoptic) – śmiało możesz go zmienić na detr_resnet101_panoptic lub detr_resnet50_dc5_panoptic. Polecam też uruchomienie inferencji na wszystkich trzech i sprawdzenie jak różnią się od siebie wyniki.
Po wyborze modelu, możemy go wczytać.
Zwróć uwagę, że zwracam także postprocessor – pomoże nam on przy postprocessingu.
model.cuda() sprawia, że model zostanie przeniesiony na kartę graficzną.
Jeśli usuniesz ; z końca linii, wyświetli Ci się architektura modelu.
detr_model_name = 'detr_resnet50_panoptic'
model, postprocessor = torch.hub.load('facebookresearch/detr', detr_model_name, pretrained=True, return_postprocessor=True, num_classes=250)
model.cuda();
Następnie definiuję funkcję, która na oryginalną klatkę z filmu nałoży maski segmentacji i słowne informacje o klasach. Poniższy kod w zasadzie w niezminionej postaci pochodzi z notebooka obublikowanego przez facebook-research.
def get_predictions_with_labels(input_image, result):
# We extract the segments info and the panoptic result from DETR's prediction
segments_info = deepcopy(result["segments_info"])
# Panoptic predictions are stored in a special format png
panoptic_seg = Image.open(io.BytesIO(result['png_string']))
final_w, final_h = panoptic_seg.size
# We convert the png into an segment id map
panoptic_seg = np.array(panoptic_seg, dtype=np.uint8)
panoptic_seg = torch.from_numpy(rgb2id(panoptic_seg))
# Detectron2 uses a different numbering of coco classes, here we convert the class ids accordingly
meta = MetadataCatalog.get("coco_2017_val_panoptic_separated")
for i in range(len(segments_info)):
c = segments_info[i]["category_id"]
segments_info[i]["category_id"] = meta.thing_dataset_id_to_contiguous_id[c] if segments_info[i]["isthing"] else meta.stuff_dataset_id_to_contiguous_id[c]
# Finally we visualize the prediction
v = Visualizer(cv2.resize(input_image.copy(), (final_w, final_h))[:, :, ::-1],
meta,
scale=1.0,
instance_mode=ColorMode.SEGMENTATION)
v._default_font_size = 10
v = v.draw_panoptic_seg_predictions(panoptic_seg, segments_info, area_threshold=0)
return v.get_image()
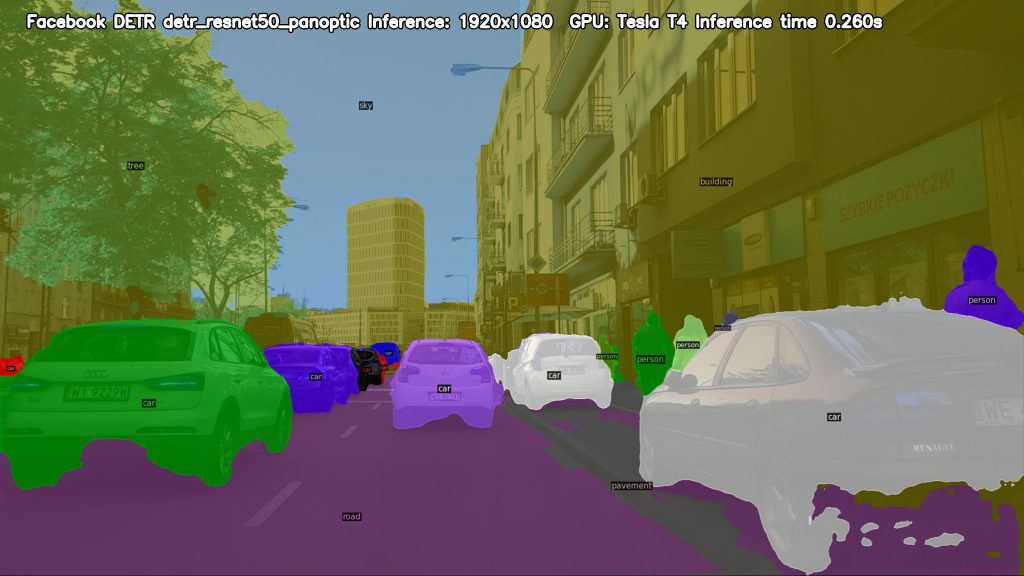
W końcu możemy przejść do głównej pętli, która odczyta nam film klatka po klatce, wykona inferencję, przekształci wynik do postaci z funkcji powyżej. Dodatkowo, składam w jeden obraz wynik oraz 12 map aktywacji. W ostatecznej wersji, każda z klatek przyjmuje postać jak na poniższym obrazie.

Jeszcze przed przejściem do pętli, w której odczytujemy film, tworzę obiekt cv2.VideoCapture, który jako argument przyjmuje ścieżkę do filmu. Możliwe jest też odczyt obrazu bezpośrednio z kamery w naszym komputerze, ale o tym później.
Tworzę też katalog o nazwie zgodnej z nazwą naszego modelu, w zapiszemy wyniki inferencji. Będziemy chcieli je indeksować. Fajnie by było też wiedzieć ile klatek już przetworzyliśmy i ile nam zostało – stąd dwie ostatnie linijki poniższego kodu.
cap = cv2.VideoCapture('0002-20170519-2.mp4')
if not os.path.exists(detr_model_name):
os.makedirs(detr_model_name)
idx = 0
pbar = tqdm(total=45913+1)
Główna pętla programu
To teraz kolej na pętlę, poniżej pełen kod, który zaraz rozbijemy na czynniki pierwsze. Wszystkie obliczenia wykonują się w pętli while().
while(cap.isOpened()):
ret, frame = cap.read()
if frame is None:
break
h, w, _ = frame.shape
# BGR to RGB
frame=frame[:,:,::-1]
# To PyTorch tensor on GPU
img = transform(Image.fromarray(frame)).unsqueeze(0).cuda()
# Inference
t0=time.time()
with torch.no_grad():
out = model(img)
t1=time.time()
result = postprocessor(out, torch.as_tensor(img.shape[-2:]).unsqueeze(0))[0]
print(result.keys())
result_with_labels = get_predictions_with_labels(frame, result)
result_with_labels = result_with_labels[:,:,::-1]
result_with_labels = cv2.resize(result_with_labels, (w, h))
inference_size = img.cpu().numpy().shape
txt="Facebook DETR %s Inference: %dx%d GPU: %s Inference time %.3fs" % (detr_model_name,inference_size[3],inference_size[2],torch.cuda.get_device_name(0),t1-t0)
cv2.putText(result_with_labels,txt, (100,100), cv2.FONT_HERSHEY_SIMPLEX, 2, (0,0,0),19)
cv2.putText(result_with_labels,txt, (100,100), cv2.FONT_HERSHEY_SIMPLEX, 2, (255,255,255),9)
# Get 12 activation maps
# compute the scores, excluding the "no-object" class (the last one)
scores = out["pred_logits"].softmax(-1)[..., :-1].max(-1)[0]
# get n outputs with highest confidence
scores = scores.cpu().numpy()
shape = scores.shape[1]
indices = (-np.squeeze(scores)).argsort()[:12]
keep = np.zeros(shape, dtype=bool)
keep[indices] = True
keep = torch.tensor(keep).unsqueeze(0)
# Get all the remaining masks
imgs = out["pred_masks"][keep]
maps = []
for i in range(0,12):
img = imgs[i].cpu().numpy()
img = cv2.resize(img, (int(w/2), int(h/2)))
img = (img - np.min(img))*(255/(np.max(img-np.min(img))))
img = cv2.applyColorMap(img.astype(np.uint8), cmapy.cmap('cividis'))
maps.append(img)
first_row = np.hstack(maps[:4])
second_row = np.hstack((maps[4], result_with_labels[:int(h/2), :, :], maps[5]))
third_row = np.hstack((maps[6], result_with_labels[int(h/2):, :, :], maps[7]))
fourth_row = np.hstack(maps[8:])
final_image = np.vstack((first_row, second_row, third_row, fourth_row))
cv2.imwrite(os.path.join(detr_model_name, 'img%08d.jpg' % idx), final_image)
idx+=1
pbar.update(1)
del frame
cap.release()
Główna pętla programu krok po kroku
Odczytujemy klatkę i upewniamy się, czy zostało to wykonane poprawnie. Zapamiętujemy jej oryginalny rozmiar – przyda się później.
ret, frame = cap.read()
if frame is None:
break
h, w, _ = frame.shape
Zamieniamy kolejność kanałów (w OpenCV jest BGR, a nie RGB! ), wykonujemy zdefiniowane wcześniej przekształcenia przenosząc jednocześnie zdjęcie (teraz już pod postacią tensora) na kartę graficzną i wykonujemy inferencję. Mierzę czas, żeby poźniej móc wrzucić te informację na wynikowe zdjęcie
# BGR to RGB
frame=frame[:,:,::-1]
# To PyTorch tensor on GPU
img = transform(Image.fromarray(frame)).unsqueeze(0).cuda())
# Inference
t0=time.time()
with torch.no_grad():
out = model(img)
t1=time.time()
No i teraz przyda nam się wczytany razem z modelem postprocessor. Ale zanim przejdziemy do tego, co on zwraca, sprawdźmy, czym tak na prawdę jest wyjście z modelu, czyli nasza zmienna out.
type(out) zwraca class 'dict’, możemy więc sprawdzić, jakie klucze znajdują się w naszym słowniku. Dzięki out.keys() wiemy, że są to: dict_keys([’pred_logits’, 'pred_boxes’, 'pred_masks’]). pred_logits wykorzystamy później do wyświetlenia map aktywacji.
result = postprocessor(out, torch.as_tensor(img.shape[-2:]).unsqueeze(0))[0]
result_with_labels = get_predictions_with_labels(frame, result)
Jeśli sięgniemy do dokumentacji, dowiemy się, że:PostProcessPanoptic: postprocessor(*input, **kwargs)
This class converts the output of the model to the final panoptic result, in the format expected by the coco panoptic API
Dokładnie taka postać jest nam potrzebna na wejściu funkcji get_predictions_with_labels, która dzięki wykorzystaniu detectron2 w zaledwie kilku linijkach kodu tworzy nam wyjściowe zdjęcie (środkowy obraz z finalnej wizualizacji).
result_with_labels = result_with_labels[:,:,::-1]
result_with_labels = cv2.resize(result_with_labels, (w, h))
inference_size = img.cpu().numpy().shape
txt="Facebook DETR %s Inference: %dx%d GPU: %s Inference time %.3fs"%(detr_model_name,inference_size[3],inference_size[2],torch.cuda.get_device_name(0),t1-t0)
cv2.putText(result_with_labels,txt,(100,100),cv2.FONT_HERSHEY_SIMPLEX,2,(0,0,0),19)
cv2.putText(result_with_labels,txt,(100,100),cv2.FONT_HERSHEY_SIMPLEX,2,(255,255,255),9)
Ponownie musimy odwrócić kanały (tym razem z RGB na BGR), ponieważ w dalszej kolejności będziemy korzystać z OpenCV do edycji i zapisu. Zmieniamy rozmiar wyniku do oryginalnej rozdzielczości (tutaj przydają nam się zapamiętane wcześniej wartości wysokości i szerokości).
Aby środkowe zdjęcie wyglądało dokładnie tak, jak na zamieszczonym wcześniej obrazie, musimy jeszcze wrzucić na nie informacje dotyczące inferencji: nazwę modelu, rozmiar obrazu na wejściu modelu, kartę graficzną oraz zmierzony przez nas wcześniej czas inferencji. Na tym etapie obraz result_with_labels ma postać jak na zdjęciu poniżej.
Jeśli mamy już gotową predykcję, to możemy spróbować uzyskać mapy aktywacji. Ja zdecydowałam się na znalezienie map dla 12 wyjść o najwyższych prawdopodobieństwach.
W jaki sposób uzyskać prawdopodobieństwa? Tu przyjdzie nam z pomocą out[’pred_logits’], czyli tensor zawierający nieznormalizowane wyniki dla każdego z obiektów. Aby przekształcić go na prawdopodobieństwa, które sumują się do 1 skorzystamy z funkcji softmax, następnie pozbędziemy się ostatniej klasy (w DETR jest to „no-object”) i użyjemy max by znaleźć najwyższą wartość dla każdego z pikseli.
scores = out["pred_logits"].softmax(-1)[..., :-1].max(-1)[0]
Następnie wykonuje pewien trik, który pozwala mi zlokalizować te 12 map aktywacji, które mają najwyższe wyniki. Zmienna keep zawiera ich współrzędne.
scores = scores.cpu().numpy()
shape = scores.shape[1]
indices = (-np.squeeze(scores)).argsort()[:12]
keep = np.zeros(shape, dtype=bool)
keep[indices] = True
keep = torch.tensor(keep).unsqueeze(0)
Dzięki współrzędnym, w łatwy sposób uzyskuję interesujące mnie mapy.
imgs = out["pred_masks"][keep]
Okazuje się jednak, że to nie wszystko – wartości, które kryją się pod out[’pred_masks’] nie są znormalizowane – znajdują się tam zarówno wartości dodatnie, jak i ujemne, więc normalizację musimy wykonać sami. Przy okazji zmieniam też ich rozmiar i wykorzystuję mapę kolorów, aby dało się je ładnie wyświetlić. Wykonuję to dla wszystkich 12 masek.
maps = []
for i in range(0,n):
img = imgs[i].cpu().numpy()
img = cv2.resize(img, (int(w/2), int(h/2)))
img = (img - np.min(img))*(255/(np.max(img-np.min(img))))
img = cv2.applyColorMap(img.astype(np.uint8), cmapy.cmap('cividis'))
maps.append(img)
Ostatnią czynnością, którą wykonuję jest sklejenie predykcji i map w jeden obraz, który następnie zapisuję do utworzonego wcześniej katalogu.
first_row = np.hstack(maps[:4])
second_row = np.hstack((maps[4], result_with_labels[:int(h/2), :, :], maps[5]))
third_row = np.hstack((maps[6], result_with_labels[int(h/2):, :, :], maps[7]))
fourth_row = np.hstack(maps[8:])
final_image = np.vstack((first_row, second_row, third_row, fourth_row))
cv2.imwrite(os.path.join(detr_model_name, 'img%08d.jpg' % idx), final_image)
Nie możemy też zapomnieć o zwiększeniu o 1 naszego licznika, usunięciu niepotrzebnych zmiennych. Musimy też wykonać update naszego paska postępu (tbar).
idx+=1
pbar.update(1)
del frame
Po zakończeniu wykonywania pętli konieczne jest zwolnienie zasobów.
cap.release()
A może tak wykorzystać kamerę?
Jak wspomniałam wcześniej, można też przechwycić obraz z kamery komputera. Wymaga to niewielkiej zmiany i kilku dodatkowych linijek kodu, które pozwolą nam na oglądanie wyników w czasie rzeczywistym. Jeśli pracujesz w Colabie, to to jest dobry moment na pobranie pliku i uruchomienie kodu lokalnie – będzie nam potrzebny dostęp do Twojej kamery.
cam = cv2.VideoCapture(0)
if not os.path.exists('%s-cam' % detr_model_name):
os.makedirs('%s-cam' % detr_model_name)
idx = 0
while(True):
ret, frame = cam.read()
if frame is None:
continue
h, w, _ = frame.shape
# BGR to RGB
frame=frame[:,:,::-1]
# To PyTorch tensor on GPU
img = transform(Image.fromarray(frame)).unsqueeze(0).cuda()
# Inference
t0=time.time()
with torch.no_grad():
out = model(img)
t1=time.time()
result = postprocessor(out, torch.as_tensor(img.shape[-2:]).unsqueeze(0))[0]
result_with_labels = get_predictions_with_labels(frame, result)
result_with_labels = result_with_labels[:,:,::-1]
result_with_labels = cv2.resize(result_with_labels, (w, h))
inference_size=img.cpu().numpy().shape
# Get 12 activation maps
# compute the scores, excluding the "no-object" class (the last one)
scores = out["pred_logits"].softmax(-1)[..., :-1].max(-1)[0]
# get n outputs with highest confidence
scores = scores.cpu().numpy()
shape = scores.shape[1]
indices = (-np.squeeze(scores)).argsort()[:12]
keep = np.zeros(shape, dtype=bool)
keep[indices] = True
keep = torch.tensor(keep).unsqueeze(0)
# Get all the remaining masks
imgs = out["pred_masks"][keep]
maps = []
for i in range(0,12):
img = imgs[i].cpu().numpy()
img = cv2.resize(img, (int(w/2), int(h/2)))
img = (img - np.min(img))*(255/(np.max(img-np.min(img))))
img = cv2.applyColorMap(img.astype(np.uint8), cmapy.cmap('cividis'))
maps.append(img)
first_row = np.hstack(maps[:4])
second_row = np.hstack((maps[4], result_with_labels[:int(h/2), :, :], maps[5]))
third_row = np.hstack((maps[6], result_with_labels[int(h/2):, :, :], maps[7]))
fourth_row = np.hstack(maps[8:])
final_image = np.vstack((first_row, second_row, third_row, fourth_row))
txt="Facebook DETR %s Inference: %dx%d GPU: %s Inference time %.3fs"%(detr_model_name,inference_size[3],inference_size[2],torch.cuda.get_device_name(0),t1-t0)
cv2.putText(final_image,txt, (50,50), cv2.FONT_HERSHEY_SIMPLEX, 0.65, (0,0,0),10)
cv2.putText(final_image,txt, (50,50), cv2.FONT_HERSHEY_SIMPLEX, 0.65, (255,255,255),2)
cv2.namedWindow("output", cv2.WINDOW_KEEPRATIO)
cv2.imshow("test", final_image)
key = cv2.waitKey(2)
if key%256 == 27:
# ESC pressed
print("Escape hit, closing...")
break
idx+=1
del frame
cam.release()
cv2.destroyAllWindows()
Prześledźmy, co się zmieniło względem wersji wykorzystującej film z pliku. Pierwsze, co możemy zauważyć, to fakt, że podajemy inny argument przy tworzeniu obiektu cv2.VideoCapture() – nazwę pliku zastąpiło 0.
cam = cv2.VideoCapture(0)
Pętla while() wykonuje się do czasu wciśnięcia przycisku ESC, stąd while(True).
Ostatnia zmiana, to kod obsługujący wyświetlanie wyników.
cv2.namedWindow("output", cv2.WINDOW_KEEPRATIO)
cv2.imshow("test", final_image)
key = cv2.waitKey(2)
if key%256 == 27:
# ESC pressed
print("Escape hit, closing...")
break
Jak uzyskać fim?
Z pomocą przyjdzie nam ffmpeg. Wystarczy, że przejdziesz do katalogu, w którym zapisywały się wyniki i wywołasz ponizsze polecenie.
ffmpeg -i img%08d.jpg movie.mp4
Po pewnym czasie otrzymasz gotowy film z wynikiem swojej pracy.
To wszystko, co chciałam Ci pokazać w temacie segmentacji instancji. Mam nadzieję, że udało mi się nieco rozjaśnić sposób inferencji z wykorzystaniem DETR i zainteresować Cię samym modelem. Jeśli chcesz dowiedzieć się więcej i zobaczyć jak poradziłam sobie z wykrywaniem obiektów, tutaj jest kolejny post, w którym omawiam właśnie wykrywanie.
Linki
Poniżej zebrałam też przydatne materiały.
- Notebook, na którym pracowaliśmy
- Notebook od facebook-research dotyczący segmentacji
- Notebook od facebook-research dotyczący wykrywania obiektów
- Repozytorium DETR na GitHubie
- Link do publikacji
- Wpis o wykorzystaniu DETR do wykrywania obiektów