W tym poście pokażę Ci jak uruchomić pierwszy kod na TPU. Zaczynam od utworzenia TPU oraz serwera w Google Cloud, przygotowuję go do wykrywania obiektów, a następnie rozpoczynam pierwszy trening na TPU.
Zakładam, że masz już konto w Google Cloud. Jeżeli dopiero zaczynasz z GCP to zajrzyj tu i utwórz konto https://cloud.google.com/.
Pierwsze TPU
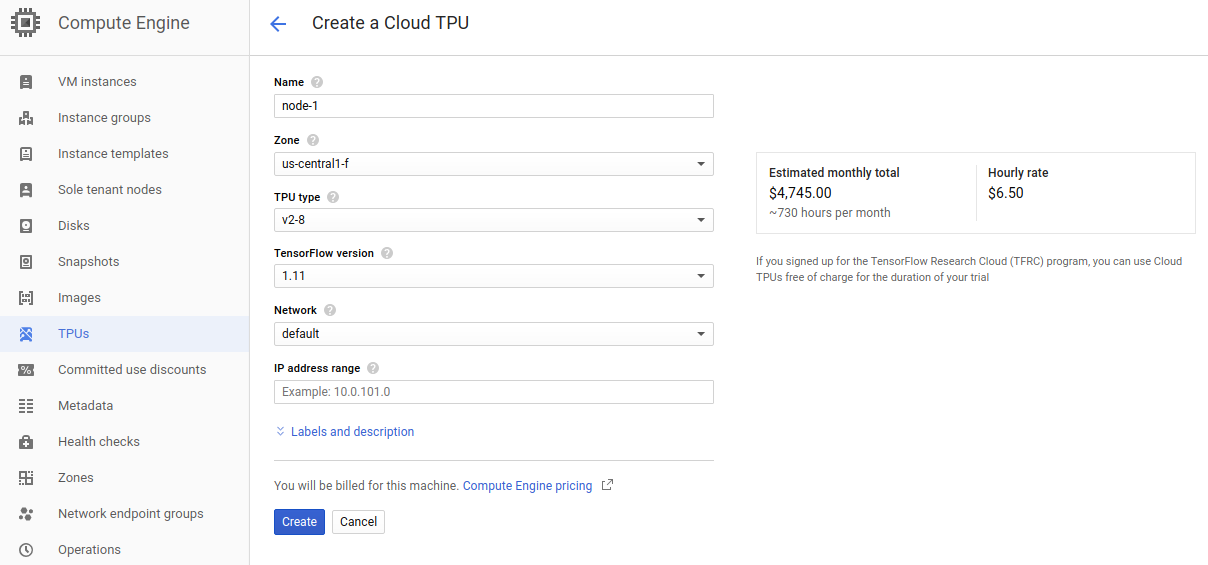
Aby utworzyć TPU musimy wejść w do Google Cloud do Compute Engine, tam znajdziemy TPUs: https://console.cloud.google.com/compute/tpus. Jeżeli dopiero zaczynasz z TPU, będzie trzeba włączyć TPU API. Aby utworzyć TPU potrzebujemy wpisać zakres adres IP – ja wpisałem 10.0.100.0 (podsieć jest automatycznie ustawiona na 29) co oznacza maksymalnie 6 adresów. Nie możemy wybrać już istniejącej podsieci, więc dla kolejnych TPU możemu użyć np. 10.0.101.0.
Uruchomienie Cloud TPU
Po uzupełnieniu adresu, wybrałem najnowszą wersję Tensorflow – 1.11. Z uwagi na to że wykorzystuję TPU z programu TensorFlow Research Cloud mam dostęp do TPU z regionu US Central1f – wszystkie TPU w tym regionie są przeznaczone na TFRC.
Moja pierwsza instancja TPU
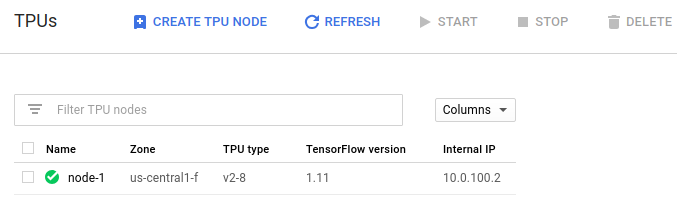
Po kliknięciu create i odczekaniu całkiem długiej chwili pojawi nam się nasz pierwszy węzeł TPU! Aby pracować z TPU potrzebujemy innego serwera w tej samej sieci, więc za chwilę stworzymy taką maszynę.
Maszyna do pracy z TPU
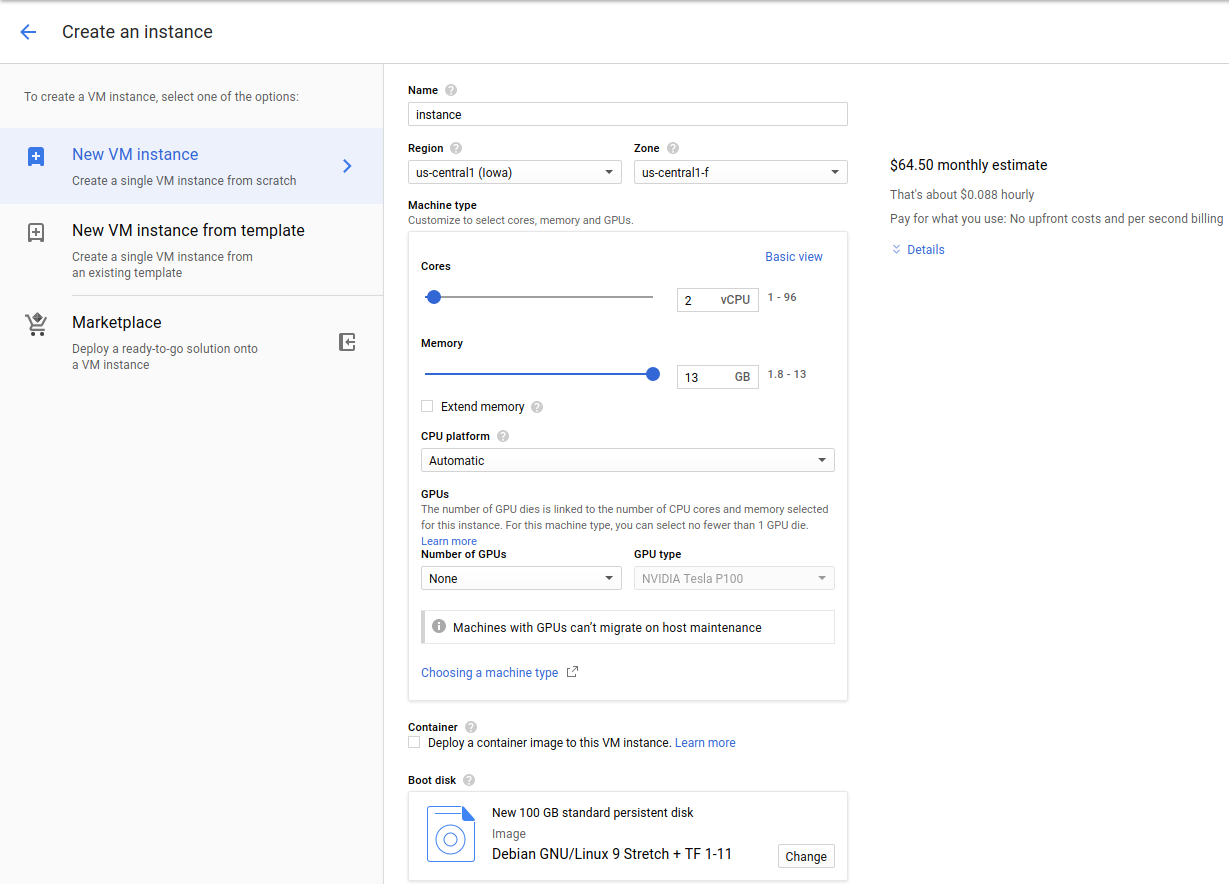
Aby korzystać z TPU potrzebujemy maszyny w Google Cloud Compute. Nową maszynę w Compute możemy dodać tutaj https://console.cloud.google.com/compute/instancesAdd. Stworzę maszynę z dwoma procesorami i 13GB RAMu. Jako dysk wybiorę Debiana przygotowanego pod Deep Learning z wykorzystaniem Tensorflow. Zwiększam pojemność dysku startowego z domyślnych 10GB do 100GB. Klikam create i po chwili maszyna się pojawia. Obecnie nie wiem jeszcze czy mi to wystarczy, najwyżej szybko zmienię typ lub stworzę inną.
Maszyna do pracy z Tensorflow i TPU
Dodatkowo musimy włączyć dostęp do Cumpute Engine API, by móc wykorzystywać TPU API z poziomu naszej maszyny.

Compute Engine API access
Sprawdźmy połączenie z TPU
Aby sprawdzić czy możemy się połączyć z TPU możemy skorzystać z prostego przykładu gdzie możemy wpisać nasze IP:
import os
import pprint
import tensorflow as tf
tpu_address = 'grpc://10.2.0.2:8470'
print ('TPU address is', tpu_address)
with tf.Session(tpu_address) as session:
devices = session.list_devices()
print('TPU devices:')
pprint.pprint(devices)
Ta metoda jest super pod względem ilości kodu, natomiast musimy znać adres IP naszego TPU. Jest też inna metoda, która znajdzie adres TPU na podstawie nazwy. Tę metodę znalazłem tutaj: https://cloud.google.com/tpu/docs/quickstart. W tym skrypcie nazwa jest pobierana ze zmiennej środowiskowej którą możemy ustawić wykonując:
export TPU_NAME=node-1
Następnie uruchamiamy python3 i możemy wkleić poniższy kod:
import os
import tensorflow as tf
from tensorflow.contrib import tpu
from tensorflow.contrib.cluster_resolver import TPUClusterResolver
def axy_computation(a, x, y):
return a * x + y
inputs = [
3.0,
tf.ones([3, 3], tf.float32),
tf.ones([3, 3], tf.float32),
]
tpu_computation = tpu.rewrite(axy_computation, inputs)
tpu_grpc_url = TPUClusterResolver(tpu=[os.environ['TPU_NAME']]).get_master()
with tf.Session(tpu_grpc_url) as sess:
sess.run(tpu.initialize_system())
sess.run(tf.global_variables_initializer())
output = sess.run(tpu_computation)
print(output)
sess.run(tpu.shutdown_system())
print('Done!')
I tu pojawia się problem – to nie działa z uwagi na problem z uwierzytelnieniem:
googleapiclient.errors.HttpError: <HttpError 403 when requesting https://tpu.googleapis.com/v1alpha1/projects/PROJECTNAME/locations/us-central1-f/nodes/node-1?alt=json returned "Request had insufficient authentication scopes.">
Podejrzewam, że to wynikło z powodu niestandardowego sposobu utworzenia maszyny i TPU. Jest inny sposób – CTPU – narzędzie do zarządzania TPU wraz z VM automatycznie. Natomiast postanowiłem posiadać jedną maszynę wirtualną i do niej chcę podpiąć 105 TPU. Inaczej koszty mogłyby mnie nieco zaskoczyć
Narzędzie CTPU
O nim nie będę więcej pisać póki co. Więcej znajdziesz tutaj: https://cloud.google.com/tpu/docs/quickstart
VM i TPU prostu z polecenia gcloud
Możemy tworzyć wszystko wykorzystując gcloud, póki co opisuję jak to robić z interfejsu graficznego. Później możliwe jest że przejdę na polecenia konsolowe, szczególni przy skali 105 TPU.
Więcej tutaj: https://cloud.google.com/tpu/docs/custom-setup
Wykrywanie obiektów
Aby rozpocząć wykrywanie obiektów potrzebowalibyśmy odpowiednio przygotować maszynę, według mojego poprzedniego wpisu. Natomiast skoro mamy już instancję z zainstalowanym Tensorflow, nie potrzebujemy już konfigurować ręcznie jak poniżej:
Retinanet
W celu przetestowania Retinanet korzystam z tutoriala https://cloud.google.com/tpu/docs/tutorials/retinanet. Na instancji mamy dostępny oficjalny model Retinanet. Sprawdźmy katalog:
ls /usr/share/tpu/models/official/retinanet/
Logujemy się do GCP
Na naszej maszynie wirtualnej musimy się zalogować do GCP wykorzystując poniższe polecenie. Polecenie wyświetli nam link który musimy wkleić do przeglądarki. Uzyskamy klucz który kopiujemy z powrotem do konsoli.
gcloud auth login gcloud auth application-default login
Storage bucket
Tworzę storage bucket, w którym będę przechowywał dane. Przypuśćmy że nazwiemy go storage_bucket (co nie jest możliwe, bo nazwy muszą być unikatowe).
export STORAGE_BUCKET=gs://storage_bucket
Pobieramy zbiór danych
Wykorzystamy kod do pobierania dostępny w repozytorium TensorFlow TPU:
git clone https://github.com/tensorflow/tpu/ cd tpu/tools/datasets screen -S download bash download_and_preprocess_coco.sh data/dir/coco
Pobieranie trwa jakieś dobre 10-15 minut. Następnie dane są konwertowane do farmatu TF record. To też trwa dłuższą chwilę. Tak z dobrą godzinę… Dwa następne polecenia kompiują dane do naszego storage bucketa.
gsutil -m cp ./data/dir/coco/*.tfrecord ${STORAGE_BUCKET}/coco
gsutil cp ./data/dir/coco/raw-data/annotations/*.json ${STORAGE_BUCKET}/coco
Następnie zainstalujemy niezbędne biblioteki do pracy ze zbiorem danych COCO
sudo apt-get install -y python3-tk pip3 install Cython matplotlib pip3 install 'git+https://github.com/cocodataset/cocoapi#egg=pycocotools&subdirectory=PythonAPI'
Trening Retinanet
Tutorial poleca przetestowanie treningu na jednej epoce, zróbmy to!
RESNET_CHECKPOINT=gs://cloud-tpu-artifacts/resnet/resnet-nhwc-2018-02-07/model.ckpt-112603
MODEL_DIR=${STORAGE_BUCKET}/retinanet-model
python3 ${HOME}/tpu/models/official/retinanet/retinanet_main.py \
--tpu=$TPU_NAME \
--train_batch_size=64 \
--training_file_pattern=${STORAGE_BUCKET}/coco/train-* \
--resnet_checkpoint=${RESNET_CHECKPOINT} \
--model_dir=${MODEL_DIR} \
--hparams=image_size=640 \
--num_examples_per_epoch=6400 \
--num_epochs=1
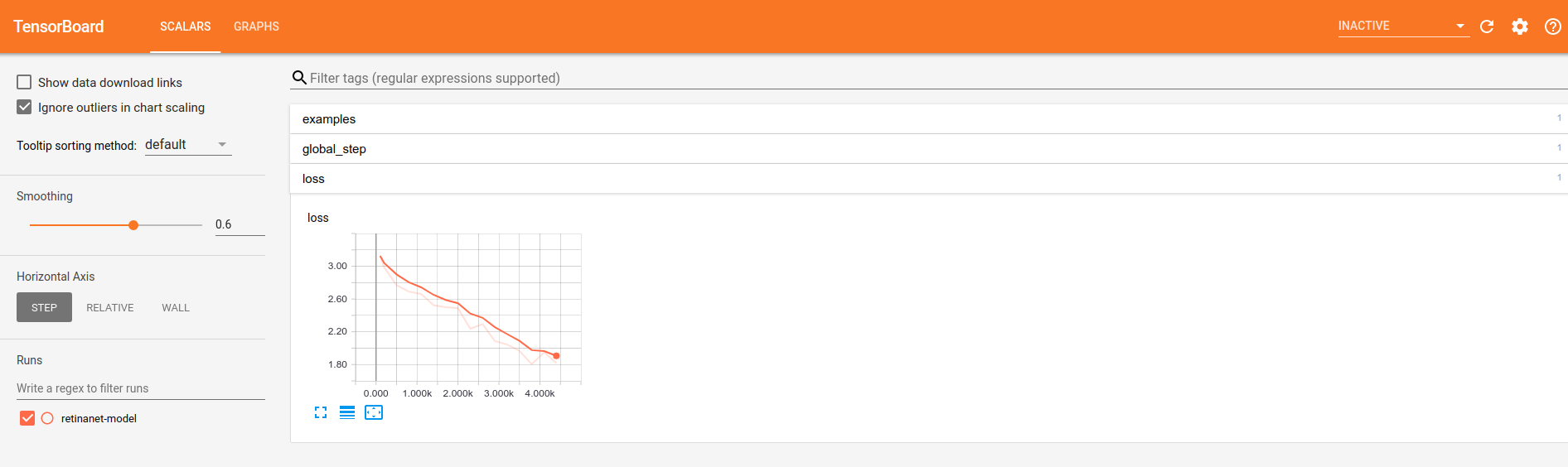
Trening działa! Możemy uruchomić go na więcej epok!
python3 tpu/models/official/retinanet/retinanet_main.py \ --tpu=$TPU_NAME \ --train_batch_size=64 \ --training_file_pattern=${STORAGE_BUCKET}/coco/train-* \ --resnet_checkpoint=${RESNET_CHECKPOINT} \ --model_dir=${MODEL_DIR} \ --hparams=image_size=640 \ --num_examples_per_epoch=6400 \ --num_epochs=100