Stwórz zapierające dech w piersiach, magiczne awatary przedstawiające Ciebie w różnych epokach, stylach, nastrojach. To technologia, której nigdy jeszcze nie widziałeś!
Te i wiele innych haseł przeczytać można w opisach wszechobecnych ostatnio stron i aplikacji oferujących generowane przez sztuczną inteligencję portrety. Postanowiłam skorzystać z jednej z takich usług, LensaAI i po wgraniu około 20 zdjęć mojej twarzy, w różnych warunkach oświetleniowych i z różnych kątów, zapłaceniu 11 złotych i odczekaniu 20 minut, byłam zaskoczona wynikiem. Pozytywnie zaskoczona, bo każdy z 50 wynikowych obrazów przedstawiał osobę z cechami mojej twarzy, żaden nie był zdeformowany, zbyt dziwny (w klasyfikacji mojej doliny niesamowitości) ani nie przypominał wklejonych elementów, a zupełnie nowe, spójne dzieło. Takie właśnie kryteria wyznaczyłam sobie dla mojego generatora, biorąc poprawkę na to że twórcy Lensy, Prisma Labs, zajmują się różnymi sposobami upiększania zdjęć już od kilku lat.
Podstawą dla mojej pracy był tekst z bloga Benny’s Mind Hack, ale zaciekawiona procesem poszerzyłam swoją wiedzę o inne źródła.

Jak działa Stable Diffusion
Stable diffusion to jeden z wielu modeli generujących obraz na podstawie wejścia tekstowego (prompt). Jest szczególnie godny uwagi ze względu na dostępność open source i znaną bazę obrazów, na których został wytrenowany (dla wersji 2.1 jest to LAION-5B, obecnie największa ogólnodostępna baza obrazów opisanych słowami kluczowymi).
W uproszczeniu taki model generujący obrazy to kilka programów sekwencyjnie wykonujących podzadania. W czasie treningu do obrazów ze zbioru uczącego stopniowo dodawany jest szum (noise) i model zapamiętuje zależności między grafiką wejściową, grafiką zaszumioną i tekstem wejściowym. Kiedy generujemy obraz, pierwszym krokiem jest losowy szum. W kolejnych krokach algorytm odejmuje małą część szumu i zapełnia te piksele swoimi przewidywaniami jak wyglądał obraz wejściowy. Wynik jest oceniany przez kolejny program – sieć neuronową CLIP, która zna ogromną ilość wizualnych konceptów (np. cechy wyglądu powiązane z konceptem banan) i potrafi oceniać obrazy, jak bardzo są do tych wizualnych konceptów podobne. Na podstawie tego podobieństwa dostosowywane są wagi modelu.

Nowe zdjęcie ma pewne cechy zdjęcia wejściowego, ale nigdy nie będzie identyczne
Wymagania sprzętowe i instalacja
Dużym ułatwieniem w generowaniu własnych obrazów jest Stable Diffusion Web UI, przeglądarkowy interfejs umożliwiający używanie i konfigurację modelu bez kodowania.
Web UI ma wbudowane kilka parametrów, które pozwalają na mniejsze zużycie zasobów przy generowaniu obrazów, jednak żeby wytrenować model na swoich zdjęciach potrzebna jest karta graficzna z minimum 8 GB vramu.
Wielu problemów przy instalacji pomogło mi uniknąć uprzednie ręczne zainstalowanie bibliotek torch i xformers (opcjonalny pakiet znacznie przyspieszający generację i trening, czasem pomaga też poradzić sobie z błędami generacji) za pomocą Anacondy (szczególnie ważne przy tej drugiej, ponieważ najnowsza wersja xformers dostępna poprzez pip, 0.0.13, nie jest kompatybilna z SD Web UI). Dobrze sprawdzić też, czy torch ma dostęp do zasobów karty graficznej i CUDA (zestawu narzędzi do zrównoleglania zadań na jednostkach GPU), poprzez uruchomienie w konsoli pythonowej polecenia
import torch; torch.cuda.is_available()
Ostatnim etapem przygotowań przed pierwszym uruchomieniem jest pobranie checkpointu modelu Stable Diffusion. Znajdziemy go np. poprzez wyszukiwarkę Hugging Face i pobraniu pliku w formacie .ckpt z odpowiedniego repozytorium. Checkpoint należy umieścić w folderze stable-diffusion-web-ui/models/Stable-diffusion. Aby załadować do SD Web UI modele >2.0 potrzebny jest specjalny plik konfiguracyjny o rozszerzeniu .yaml. Możemy pobrać go z oficjalnego repozytorium Stable Diffusion, a następnie zapisać w folderze z modelami pod taką samą nazwą, jak nazwa wag (plik .ckpt). Video z instrukcją krok po kroku. W folderze moze znajdować się kilka różnych modeli, konkretny wybieramy później z dropdownu na górze interfejsu.
Instalacja i używanie SD Web UI polega na uruchomieniu przygotowanego skryptu – webui.sh dla systemów Linux, webui-user.bat dla Windowsa. Oficjalna instrukcja instalacji w README projektu sugeruje, by pobrać i uruchomić ten plik bezpośrednio z githuba, jednak ja polecam ściągnięcie repozytorium i uruchomienie lokalne – jest możliwa łatwiejsza zmiana parametrów.
Pierwsze uruchomienie
Po uruchomieniu skryptu i dobrej chwili czekania na pobranie wszystkich wymaganych komponentów, załadowanie wag modelu i postawienie webservera, w domyślnym ustawieniu pod adresem sieciowym http://127.0.0.1:7860 ujrzymy prosty interfejs z polami tekstowymi i dużą ilością przełączników. To za jego pomocą motyw wygenerować swój własny obraz z wpisanego tekstu.
Czarne obrazy lub szum
Może się zdarzyć, że pierwsze wygenerowane obrazy po załadowaniu nowego modelu będą nieudane – całe czarne, lub będzie to bezsensowny szum/plamy barwne. U mnie działo się tak, kiedy pominęłam opcjonalną bibliotekę xformers (żeby działała trzeba mieć ją zainstalowaną w systemie i uruchomić web ui z parametrem – bash ./webui.sh – -xformers).
Drugim sposobem na ten błąd jest zmiana Sampling method. Więcej o samplerach, razem z wizualną reprezentacją poszczególnych metod i ilości kroków, można przeczytać w tym wątku twitterowym.

Prompty
Obrazki generują się bez szumów, ale daleko im do poziomu prac publikowanych w internecie z tagami #stablediffusion #aiart? Użycie odpowiedniego tekstowego promptu jest tak ważne, że powstały darmowe (np. Lexica, PublicPrompts) i płatne (np. PromptBase) bazy danych zapytań, a nawet programy generujące optymalne prompty. StabilityAI i OpenArt udostępnili też swoje własne poradniki tworzenia tekstowych zapytań dla Stable Diffusion.
W redditowym wpisie How to get images that don’t suck polecaną metodą jest łączenie słów kluczowych w rozbudowane zapytania, pamiętając o tym, że te, które znajdują się na początku promptu i te, które zostaną powtórzone w kilku formach będą miały większy wpływ na wynik. Możemy wpisać nawet 75 różnych słów! Każde powinno mieć jednak sens, np. słowa takie jak gorgeous, pretty – wydają się niewinne, a mogą nadać wygenerowanemu obrazowi specyficznego stylu. Bardzo ciekawym materiałem pokazującym wizualnie jak zmienia się wynik w zależnosci od promptu jest jedenastominutowe wideo Stable Diffusion Prompt Guide.
W negative prompt wpisujemy obiekty i cechy, których nie chcemy zobaczyć na wygenerowanym obrazku, np. blur, haze, deformed. W Stable Diffusion Web UI możemy też użyć specjalnych modyfikatorów – nawiasów okrągłych jeśli chcemy zwiększyć ważność danego słowa kluczowego, nawiasów kwadratowych jeśli chcemy ją zmniejszyć czy znaku | żeby połączyć dwa hasła np. pół człowiek, pół dinozaur.
Post-processing steps
W UI, pod wyborem samplera, zobaczymy jeszcze checkboxy z dodatkowymi opcjami – Restore faces, Tiling, Highres fix. Są to opcje post-processingu wygenerowanego już obrazka jak poprawienie twarzy, rozdzielczości czy utworzenie powtarzalnego wzoru (pattern). Użycie tych opcji znacznie wydłuża czas generacji, najlepiej używać ich, kiedy mamy już obraz, który nas satysfakcjonuje, a chcemy jedynie popracować nad szczegółami.

Dataset
Tak samo jak do Lensy, przygotowałam zbiór 20 moich zdjęć – z różnych perspektyw, w różnym świetle, zarówno sama twarz jak i zdjęcia sylwetki, w makijażu i bez, itp. Dodałam również zdjęcia bez okularów po tym, jak w pierwszych wygenerowanych portretach model miał wyraźny problem z oczami – w ich miejsca często pojawiały się artefakty i obiekty przypominające odblaski światła.
Każde z wybranych zdjęć przycięłam do rozmiaru 516x516px (dokładna wielkość zależy od parametrów modelu i proporcji obrazu wyjściowego).

Trenowanie własnego embeddingu
Najprostszym sposobem na wygenerowanie awataru z własną twarzą przy użyciu Stable Diffusion jest utworzenie embeddingu. Podczas treningu na zbiorze zdjęć mojej twarzy, został utworzony specjalny zbiór wektorów opisujących nowy koncept (takich jak wspomniany wcześniej koncept banana w sieci CLIP). Reprezentacja tego jak wyglądam jest teraz keywordem, który mogę dopisać do promptu generując obrazek. Model pozostaje niezmieniony. Więcej o tym jak dokładnie działa textual inversion, czyli technologia umożliwiająca tworzenie embeddingów, można przeczytać na stable diffusion wiki.
Aby zrobić to samemu, w zakładce Train i podzakładce Create embedding wpisujemy unikalne słowo kluczowe opisujący dany embedding. Możemy wprowadzić Initialization text, krótkie frazy opisujące koncept, który chcemy odzwierciedlić np. face, person. Number of vectors per token dla zbioru 20 obrazów uczących najlepiej ustawić na 1 lub 2 (przy 2 zauważyłam poprawę generacji oczu pod okularami; większa liczba wektorów lepiej działa przy większych zbiorach).
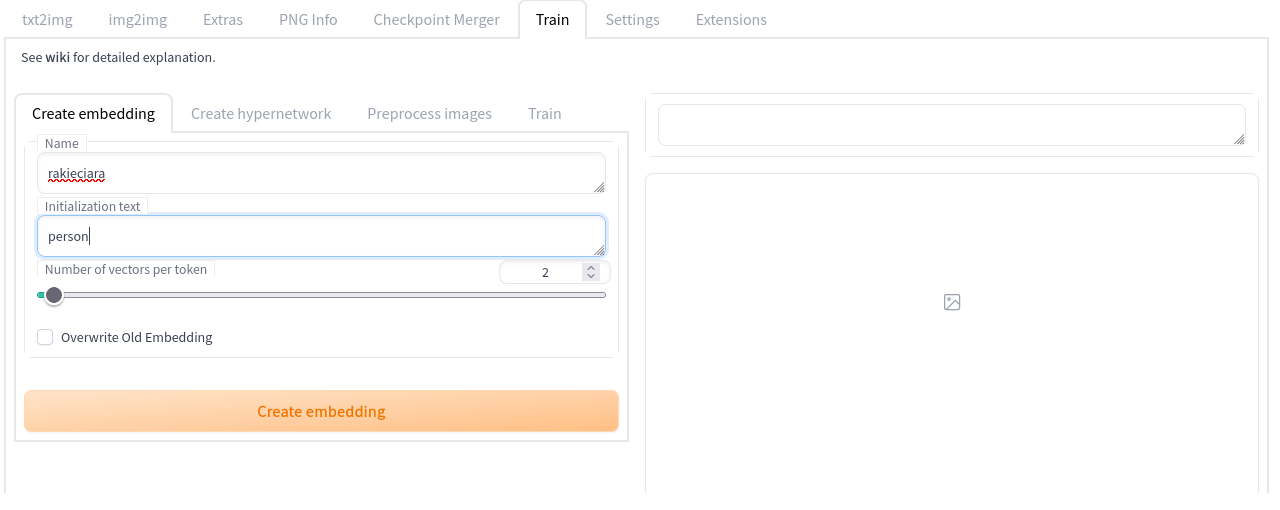
W podzakładce Train wybieramy utworzony embedding i konfigurujemy trening. Obowiązkowo musimy wypełnić pole Dataset directory ścieżką do folderu z wcześniej przygotowanymi obrazkami. Warto zwrócić też uwagę na Prompt template file – twórcy SD Web UI przygotowali dwa pliki tekstowe z promptami dotyczącymi stylów artystycznych (style_filewords.txt, np. a painting, art by [name], a rendering, art by [name]) i dotyczącymi tematu/obiektu (subject_filewords.txt, np. a cropped photo of a [name], a photo of the [name]).
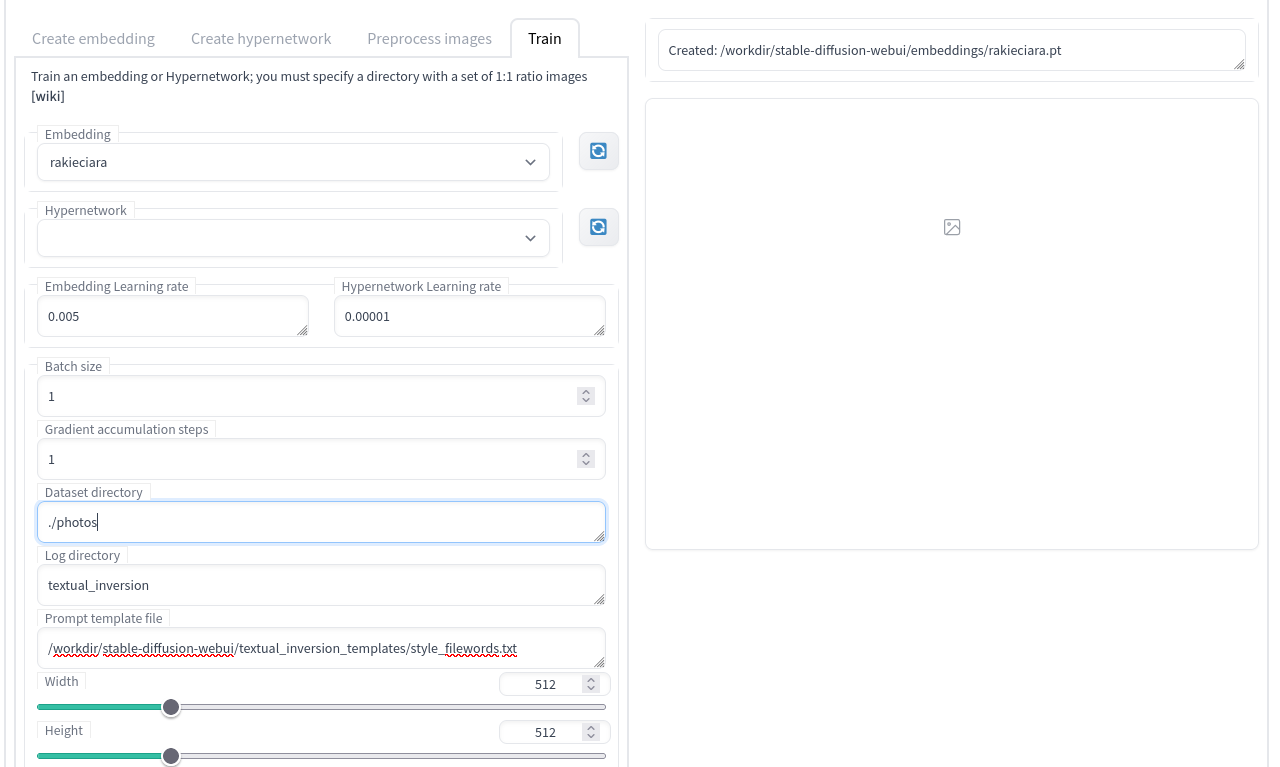
Przydatną opcją jest też Read parameters from text2img tab when making previews. Jeśli ją zaznaczymy, to co zdefiniowany interwał kroków obrazek wygenerowany z identycznym promptem jaki mamy aktualnie wpisany w zakładce text2img, zostanie zapisany. Analizując te obrazki jak na dłoni widać postęp treningu – wygenerowane osoby są coraz bardziej podobne do tych w zbiorze uczącym.
Resztę parametrów przy pierwszym uruchomieniu można zostawić na wartościach domyślnych. Pozostaje kliknąć train i czekać. U mnie trenowanie na 20 obrazkach, 2 vectors per token, 100k max steps zajęło około 10h.
Modele
Oprócz różnych, oficjalnych wersji Stable Diffusion (np. SD 1.4, SD 2.1) do pobrania dostępne są również checkpointy modeli tworzone przez społeczność. To efekty trenowania całego modelu (nie jedynie embeddingu) na wyselekcjonowanym pod daną cechę/styl artystyczny zbiorze obrazów. Aktualnie trendujące modele razem z obrazkami przez nie wygenerowanymi przejrzeć można na subreddicie r/StableDiffusion, gdzie użytkownicy bardzo chętnie dzielą się swoimi sposobami na wygenerowanie czegoś pięknego, razem z linkami, gdzie można pobrać dane pliki .ckpt. Do dyspozycji mamy modele w stylu kreskówkowym, anime, fantasy, czy przypominające fotografię analogową.

Bardzo ważne przy generowaniu astronautek okazały się negative prompts, dzięki którym mogłam usunąć cechy, które często miały kobiety w kosmosie na zdjęciach uczących, więc model uznał za cechę charakterystyczną dla zapytania female astronaut. Były to na przykład pociągła twarz (lub lekko zdeformowana soczewką szerokokątną używaną przy zdjęciach z międzynarodowej stacji kosmicznej), wąski nos i zmarszczki wokół oczu.
Img2Img i Inpaint
Świetnymi opcjami, w jakie zostało wyposażone web UI są img2img, czyli dodanie obrazu wejściowego do tekstowego zapytania i Inpaint, gdzie na obrazie wejściowym możemy narysować lub załadować maskę i wygenerowane zostaną jedynie elementy zamaskowane.


wygenerowałam własną wersję lofi girl za pomocą img2img
Textual Inversion i style artysów
Nadanie awatarom stylów możemy zrealizować nie tylko podmieniając cały model, a również używając textual inversion. Podążając za tutorialem i pobierając odpowiedni plik embeddingu .pt, możemy generować nawet obrazki stylizowane na te tworzone przez inny program text2img, Midjourney.
Duży wybór dostępnych do pobrania modeli i embeddingów znajdziemy dzięki wyszukiwarce Civitai, wybierając odpowiednie filtry (embeddingi mogą działać tylko na konkretnym modelu, na którym zostały utworzone). Kilka znajdziemy też przeszukując odpowiednio Huggingface.
W moim przypadku style artystyczne w postaci textual inversion sprawdziły się dużo lepiej, niż podmiana modeli – modele mangowe czy malarskie po wytrenowaniu na zdjęciach mojej twarzy często traciły swój rysunkowy styl i zaczynały przypominać zdeformowaną hybryde zdjęcia i dzieła w danym stylu. Przy użyciu dwóch embeddingów – mojego wytrenowanego i wybranego stylu artystycznego, efekty wyglądały dużo lepiej.


W uproszczonym, disneyowskim stylu wystarczy kolor włosów i okulary i już postać wygląda podobnie.
Podsumowanie
Podsumowując tą małą przygodę z generacją obrazów, nie mogę nie wspomnieć że większość z naprawdę wielu portretów które wygenerowałam była okropna. Zdeformowana, w ogóle nie podobna, zawierająca elementy wyrastające nie wiadomo skąd. Mimo użycia negative promptów, żeby osiągnąć realistyczne i cieszące oko efekty potrzeba wielu iteracji, czasem przyjrzenia się wejściowej bazie obrazków i podmienienia tych powodujących szumy.

To niby oczywiste, ale mnie zaniepokoił trochę fakt, jak bardzo generacja polega na obrazach wejściowych i jak szybko uczy się stylów. Wystarczyła jedna grafika z lofi girl, aby Stable diffusion wygenerowało podobny obrazek przypominający rysunek, kreskówkę. Jest to więc narzędzie, które może rozbudzić kreatywność, ale też pozbawić wielu artystów chęci dzielenia się publicznie swoją sztuką, by nie zostać tylko kolejnym stylem w wyszukiwarce.
Notatka od Karola o środowisku w Dockerze
Do pracy nad tym wpisem zostało przygotowane środowisko w dockerze – tam powstała całość. Jako obraz posłużył obraz od Nvidia’i – wersja z listopada 2022. W kontenerze, ręcznie doinstalowano odpowiednie wersje bibliotek czy też jupyter-laba. Porty – 8888 to jupyter, 22 to ssh, by mieć dostęp bezpośredni, a 7860 to port do webui. ipc=host zadziała tylko na linuxie, wskazałem też pierwszą z dostępnych kart. Aby było lepiej – warto przygotować Dockerfile’a pod webui, ze względu na powtarzalność. Kontener od Nvidia niekoniecznie był tu ułatwieniem, także uwaga.
Poniżej polecenie dockera wykorzystane by uruchomić kontener:
docker run --gpus "device=0" --ipc=host -v ~/working-dir-on-host:/workdir -p 8989:8888 -p 33442:22 -p 7860:7860 -it nvcr.io/nvidia/pytorch:22.11-py3 bash