Poniższy wpis jest kontynuacją serii opisującej nasze zmagania ze zbiorem linii komórkowych CTMC-V1. Zadaniem jest wykrycie i śledzenie obiektów (w tym przypadku komórek) na kolejnych klatkach filmów. Postawnowiliśmy rozwiązać ten problem poprzez rozdzielenie zadania wykrywania i śledzenia komórek. W poprzednim poście, Karol przedstawił w jaki sposób uruchomić trening YOLOv4 na własnym zbiorze. Ja opiszę jakie problemy napotkaliśmy w procesie uczenia, a następnie przedstawię jak podeszliśmy do zadania śledzenia obiektów.
Przypomnę tylko, że zbiór CTMC-v1 pochodzi z tegorocznego MOT Challenge, a rozwiązania można można było przesyłać do 21 maja 2021 roku.
Kontynuacja treningu YOLOv4
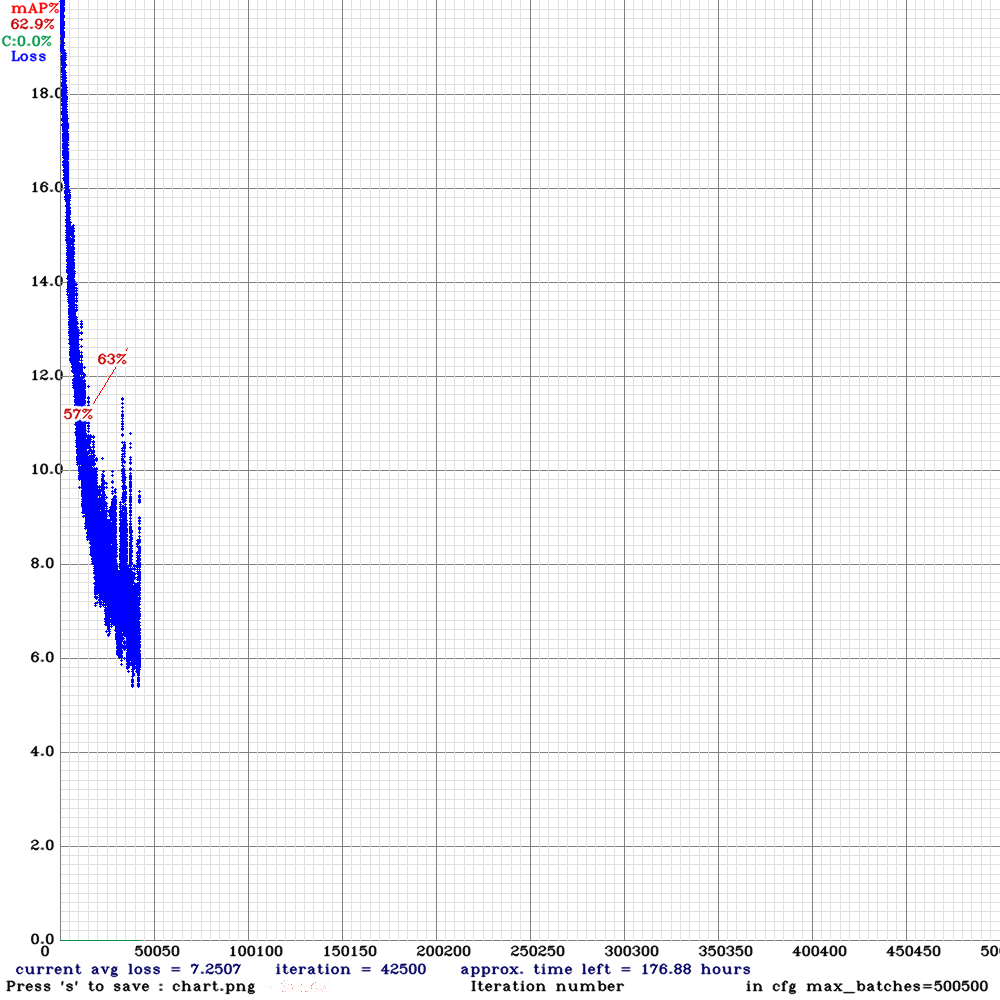
Poprzedni post zakończył się mniej więcej w połowie eksperymentu 001 – w nim już niewiele się wydarzyło. Maksymalna średnia precyzja, jaką udało się osiągnąć, to 95%. W planach było douczenie modelu z wykorzystaniem rozszerzonego o obroty i odbicia zbioru treningowego.
Pierwsza zasadzka
W międzyczasie, odkryłam, że przy generowaniu etykiet w formacie YOLO, wkradł się błąd i groud-truth, które wykorzystaliśmy do treningu było nieco przekłamane. Aby uzyskać współrzędną y środka obiektu, należy oczywiście dodać połowę jego wysokości (a nie szerokości, jak to miało miejsce).xc=x1+0.5*w yc=y1+0.5*w yc=y1+0.5*h
Wygnenerowałam więc jeszcze raz wszystkie etykiety i dodałam do zbioru treningowego.
Eksperyment 002
Mając prawidłowe etykiety mogłam powrócić do przygotowywania nowego zbioru. Dla każdego zdjęcia z train, wygenerowałam po jednej kopii:
- obróconej o 180°
- odbitej w pionie
- odbitej w poziomie
Mając 4x więcej danych niż pierwotnie, uruchomiłam trening. Jaki efekt osiągnęłam?
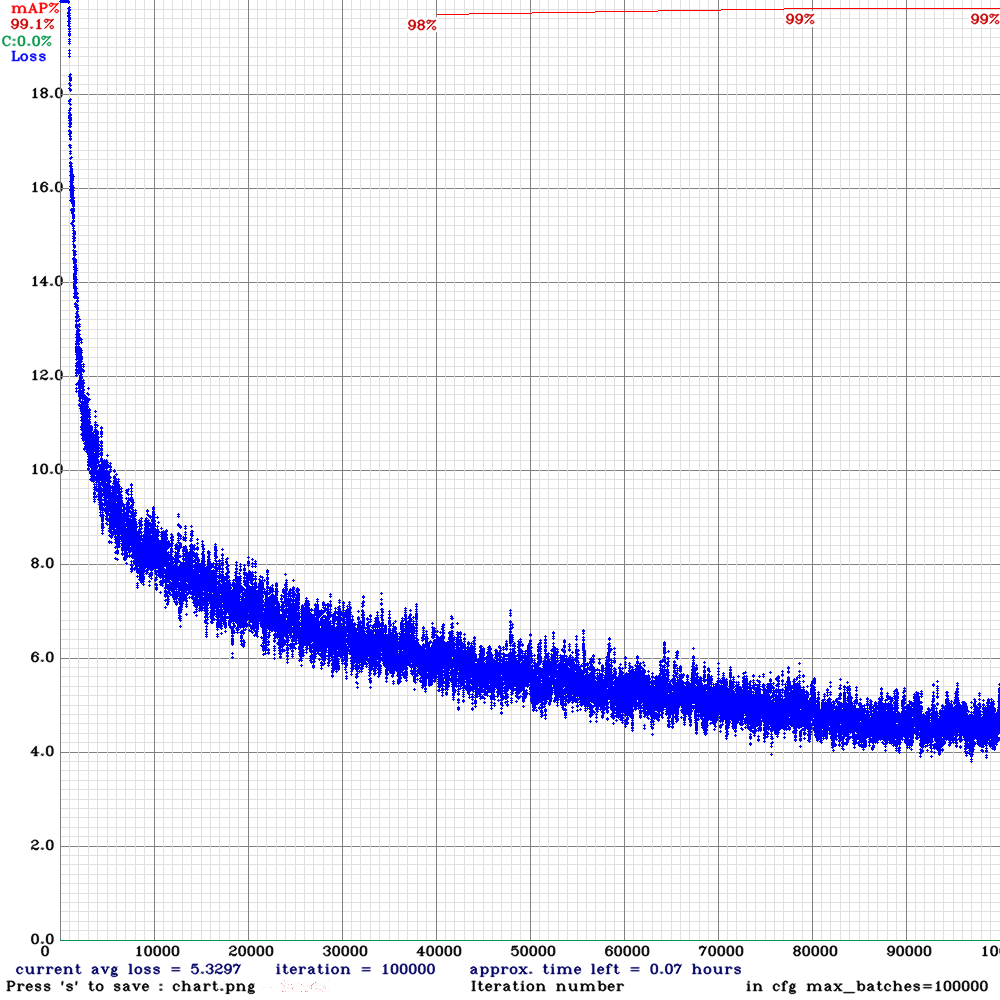
Wydaje się być super, mAP na poziomie 99% to doskonały wynik. Wykonałam inferencję na zbiorze testowym i uzyskany efekt był takie sobie. Pytanie dlaczego?
Druga zasadzka
Okazuje się, że dane w zbiorze CTMC-v1 są dość specyficzne. Jak pamiętasz z pierwszego posta, dane treningowe składają się z 47 sekwencji (czyli klatek filmów) nagranych linii komórkowych. Dane sekwencyjne występują w zagadnieniach przetwarzania obrazów dość często i samo to nie jest nietypowe. Nietypowa natomiast jest niewielka zmienność obrazu między kolejnymi klatkami. Na niektórych sekwencjach, ruch komórek jest nieznaczny, przez co obraz przez kilka, kilkanaście, czy kilkadziesiąt klatek wygląda praktycznie identycznie. Na czym polegał problem, możesz zobaczyć na poniższym screenie.

Jak dokonywaliśmy podziału na zbiór treningowy i walidacyjny? Co 5 klatka z każdej sekwencji w trainval była przydzielana do zbioru walidacyjnego. To sprawiało, żę w wielu przypadkach obrazy w val były niemalże kopią danych w train.
Zbiór walidacyjny nie spełniał swojej funkcji – w pewnym sensie pokazywał nam, jak dobrze model radzi sobie z danymi, na których był uczony.
Trening YOLOv4 – podejście drugie
Już wiemy, że zbiór trzeba podzielić inaczej. Jeśli wybór pojedynczych klatek nie zdał egzaminu, postanowiłam wydzielić do zbioru walidacyjnego całe sekwencje. Tylko jak to zrobić dobrze? Musimy najpierw dookładnie przeanalizować zbiór danych.
Podział zbioru treningowego
Już ze strony MOT Challenge dowiadujemy się, że zbiór zawiera sekwencje 14 linii komórkowych. Na tym etapie wiem, że chciałabym, żeby w walidacji znalazła się przynajmniej jedna sekwencja z każdej z linii. Aby przekonać się, czy jest to możliwe wykonałam wykres przedstawiający ile sekwencji każdej z linii mamy do dyspozycji.
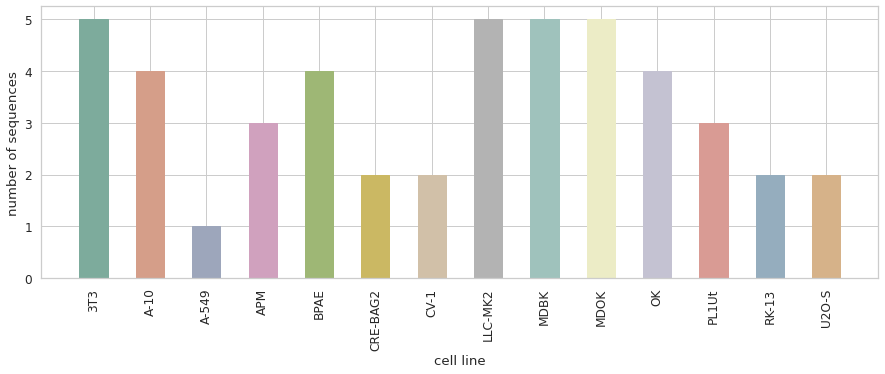
Linia A-549 występuje tylko raz, więc zdecydowałam się na zostawienie jest w zbiorze treningowym. Z pozostałych postanowiłam wybrać po jednej sekwencji. Aby ułatwić sobie wybór, sporządziłam wykresy pokazaujące ile w każdej sekwencjii jest obiektów (boundig-box) oraz ile jest unikalnych obiektów (tracks). Nie chciałam doprowadzić do sytuacji, w której w zbiorze walidacyjnym znalazłby się tylko jeden typ sekwencji – tylko takie z dużą/małą liczbą obiektów/ścieżek.
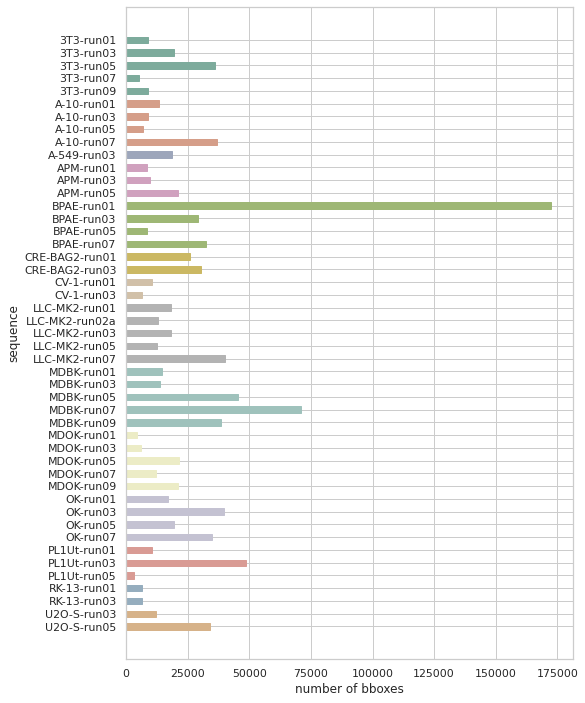
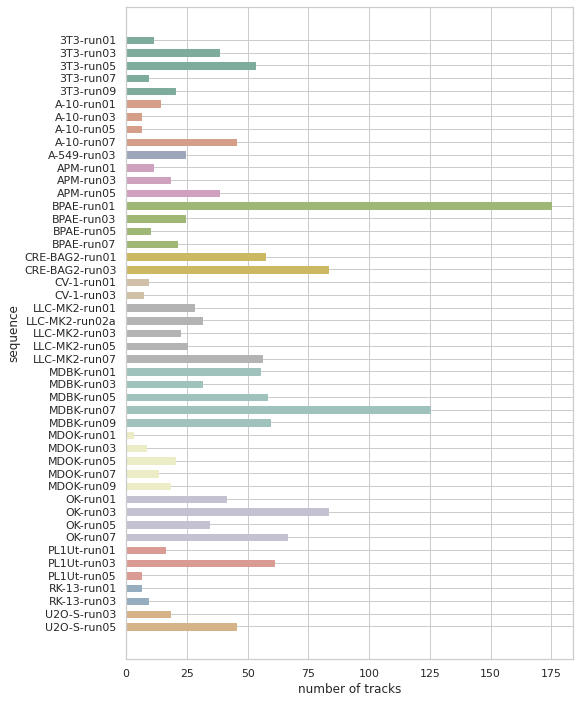
Mając do dyspozycji powyższe informacje, dokonałam podziału ręcznie – wybrałam 13 sekwencji do zbioru walidacyjnego. Pozostałe 34 pozostały w zbiorze treningowym (sekwencje ze zbioru walidacyjnego znajdziesz w repozytorium).
train/val/test
Teraz, gdy zbiór jest już podzielony. Możeby zobaczyć ile sekwencji jest w zbiorze treningowym, walidacyjnym i testowym.
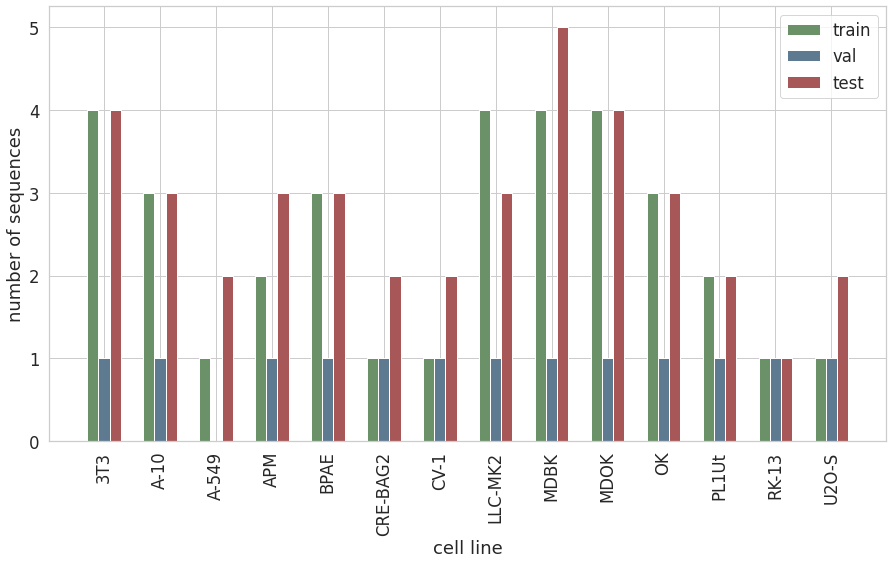
Obecnie, mamy niestety do czynienia z sytuacją, w której dla niektórych linii komórkowych, zbiór testowy ma więcej sekwencji niż zbiór treningowy. Plan jest był więc następujący.
- Wytrenowanie modelu na zbiorze treningowym.
- Dodanie przekształceń obrazu (obroty, odbicia, rozmycie) i wytrenowanie na rozszerzonym zbiorze.
- Dobór algorytmu śledzenia obiektów.
- Zrobienie submission.
- Dotrenowanie modelu na całym zbiorze trainval
- Ponowne submission.
- ….
Poprzez połączenie zbiorów w ostatniej iteracji procesu, powinniśmy poprawić zdolność generalizacji modelu i tym samy lepiej wypaść na zbiorze testowym.
Eksperyment 010
Przystępujemy do treningu po raz kolejny…
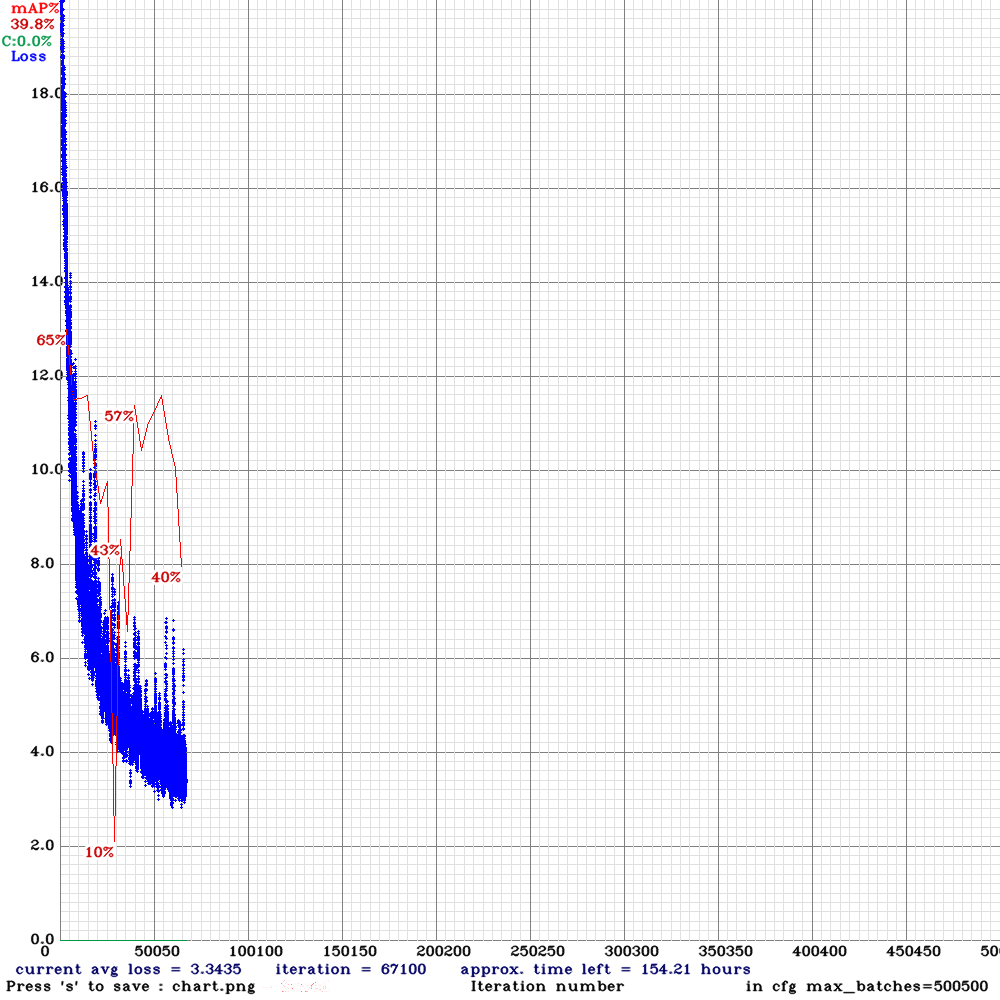
… i znowu efekt jest średni. Loss spada bardzo gwałtownie, a wartość średniej precyzji na zbiorze walidacyjnym jest niska, przez co wiemy, że następuje overfitting. Przyczyną może być zbyt mała liczba różnorodnych danych, przez co model dopasowuje się do zbioru uczącego i traci zdolność generalizacji.
Eksperyment 011
Jak rozwiązać problem ovefittingu? Ja zdecydowałam się na zapewnienie większej różnorodności danych uczących, czyli dodałam obrazy obrócone, odbite (w pionie i w poziomie) oraz rozmyte.
Zdjęcie oryginalne 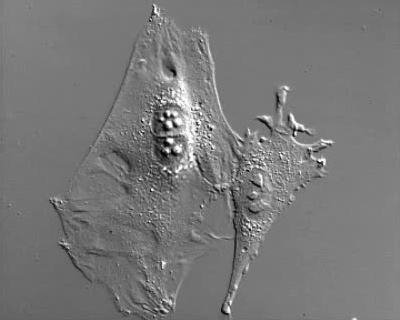
Obrót 180° 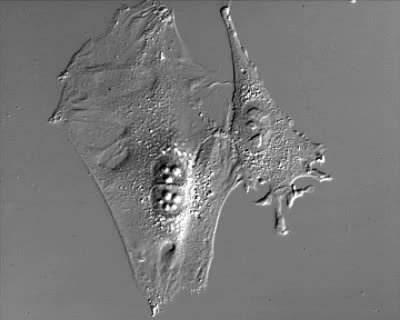
Odbicie względem OX 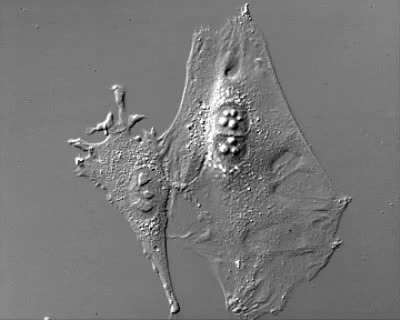
Odbicie względem OY 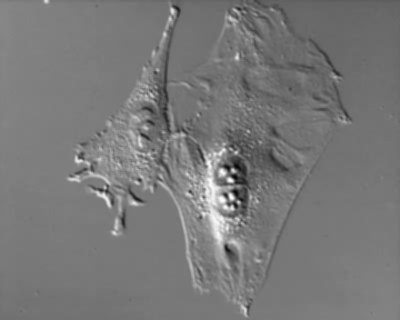
Rozmycie
Dla mnie powyższe zdjęcia wygladają dość podobie, ale model ma inne zdanie na ten temat. Czyżby udało się zażegnać problem?
Wtrącenie, czyli wizualizacja zbioru CTMC-V1
Jak już zabieramy się za wszystko od początku, to zwizualizaujmy jeszcze zbiór danych…
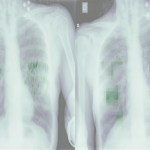
…no i tu też czakają na nas niespodzianki. Etykiety nie są idealne – zupełnie wyrywkowo ogladając sekwencje, udało mi się znaleźc kilka błędów. Na początku sekwencji 3T3-run01 widzimy błędnie opisane komórki w trakcie podziału (???)
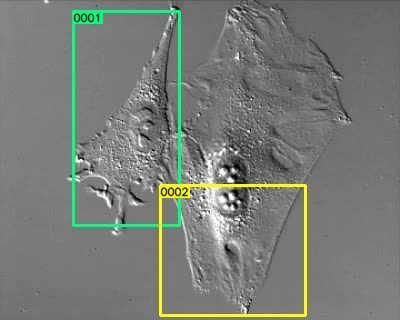
000001.jpg 
000012.jpg
A tu ramka opóźniona o kilka klatek względem obiektu.

000062.jpg 
000063.jpg 
000064.jpg 
000065.jpg 
000066.jpg 
000067.jpg 
000068.jpg 
000069.jpg 
000070.jpg
Co zrobimy z tym faktem? Zupełnie nic, godzimy się na to. Wrzucam tę informację bardziej jako ciekawostkę oraz by pokazać Ci, że w publikowanych zbiorach pojawiają się też błędy i warto mieć tego świadomość.
Rzeczywistość, czyli 6 miesięcy później…
Tutaj miała znaleźć się dalsza opowieść dotycząca naszych zmagań ze zbiorem CTMC-V1. Rzeczywistość zweryfikowała jednak plany – poniższy wykres to dalszy przebieg zapowiadającego się tak optymistycznie treningu.
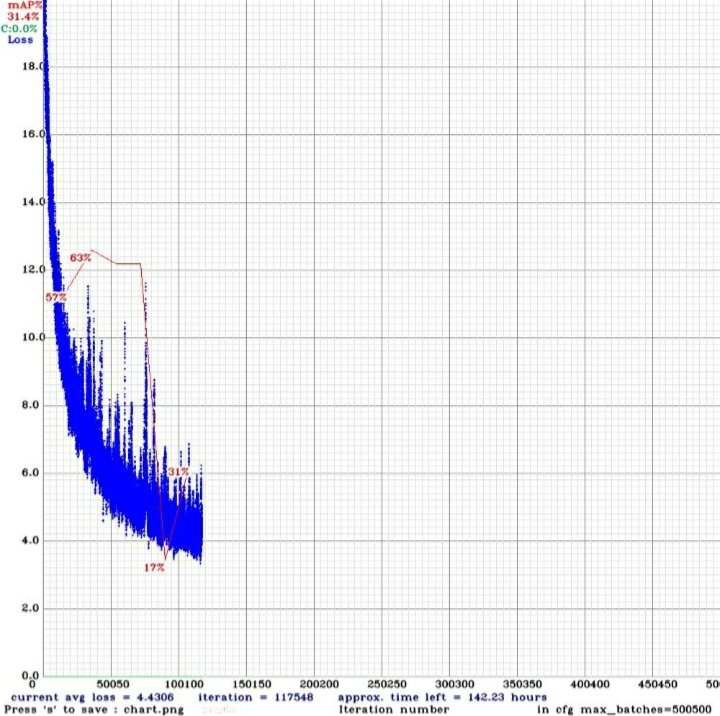
Co mogło się wydarzyć po drugiej walidacji? Prawdopodobnie znów miał miejsce overfitting. Warto byłoby sprawdzić wyniki dla modelu best i na ich podstawie próbować uruchomić śledzenie.
Nie wszystko stracone
Mimo, że czas na publikację rozwiązań w ramach konkusu MOT Challenge dawno się skończył, postanowiłam doprowadzić ten post do końca i pokazać Ci w jaki sposób uruchomić śledzenie obiektów na przykładzie zbioru linii komórkowych.
Meritum, czyli śledzenie obiektów
Zacznijmy od bardzo ogólnego wprowadzenia, czym jest śledzenie i z jakich algorytmów możemy skorzystać. Śledzenie, czyli object tracking jest zagadnieniem ściśle związanym z sekwencjami, czyli filmami. Chodzi w nim o to, żeby każdemu unikalnemu obiektowi przypisać odpowiednie id, dzięki czemu uzyskujemy informację o położeniu obiektów w kolejnych klatkach i możemy analizować ich ruch.
Można wyróżnić dwie główne grupy algorytmów:
1. tracking-by-detection będące procesami dwustopniowymi. W pierwszej kolejności wykonywana jest detekcja, a metadane, czyli wykryte obiekty przekazywane są na wejście trackera.
2. Metody wykonujące jednocześnie wykrywanie i śledzenie.
Jak pewnie się domyślasz, my skorzystamy z podejścia pierwszego i wyniki inferencji wytrenowanego przez nas modelu przekażemy do algorytmu śledzenia obiektów.
Inferencja YOLOv4
W pierwszej kolejności potrzebne nam są detekcje – inferencję wykonam na zbiorze walidacyjnym.darknet detector test cfgs/011-v4.data cfgs/011-v4.cfg backups/011-v4_best.weights -ext_output -dont_show -out results/011-best-val.json < filelists/011-val
W repozytorium znajdziesz gotowy plik 011-best-val.json z detekcjami, dzięki czemu dalszą część możesz wykonać lokalnie na swoim komputerze. git clone https://github.com/deepdrivepl/CTMC-v1-solution.git && cd CTMC-v1-solution
Konwersja wyników do formatu MOT
Dla wygody, już na tym etapie postanowiłam przekonwertować wyniki do formatu MOT, przez co ujednolicimy dalsze działania i już do końca będziemy korzystać z tego formatu danych. Przygotowałam skrypty, które umożliwiają konwersję zarówno dla wyników w postaci plików txt, jak i w postaci pliku JSON.python MOT/yolo2MOT/yolo2MOT.py --input results/011-best-val.json --out_dir results/011-best-val/detection --json
Po wykonaniu skryptu, tak wyglada struktura katalogu results.
results/011-best-val
└── detection
├── 3T3-run03.txt
├── A-10-run05.txt
├── APM-run05.txt
├── BPAE-run03.txt
├── CRE-BAG2-run03.txt
├── CV-1-run03.txt
├── LLC-MK2-run03.txt
├── MDBK-run09.txt
├── MDOK-run07.txt
├── OK-run01.txt
├── PL1Ut-run01.txt
├── RK-13-run03.txt
└── U2O-S-run03.txt
Każdy plik zawiera detekcje w formacie MOT – w miejscach, w którym powinno znajdować się id obiektu wstawiłam -1. Wstawimy w jego miejsce odpowiednie wartości po wykonaniu śledzenia.
Jak uruchomić śledzenie?
IoU Tracking
W pierwszej kolejności uruchomiłam IoU Tracking. Jest to tracker, który jak nazwa wskazuje korzysta z IoU, czyli Intersection over Union – sprawdza on pokrywanie się ramek prostokątów w kolejnych klatkach. Aby obiekt w obecnie analizowanej klatce otrzymał takie samo id jak jeden z obiektów z poprzedniej klatki, obliczone dla tych dwóch obiektów IoU musi być większe od zadanego progu. Jeśli nie ma żadnego takiego obiektu, to obiekt otrzymuje nowe id. Jeśli takich obiektów jest więcej, to wybierany jest ten, dla którego IoU jest największe. Tutaj możesz poznać więcej szczegółów dotyczących tej metody.
Skorzystałam z istniejącej implementacji trackingu IoU. Poniżej pokazałam, co trzeba zrobić, aby uzyskać wyniki.git clone https://github.com/bochinski/iou-tracker.git && cd iou-trackerpython demo.py --detection_path ../results/011-best-val/detection/U2O-S-run03.txt --output_path ../results/011-best-val/iou/U2O-S-run03.txt --format motchallenge
Jest jeden minus – jak widzisz skrypt przyjmuje na wejściu ścieżkę do pliku, a nie katalog – należy go zatem uruchomić 13 razy (bo tyle mamy sekwencji w zbiorze walidacyjnym). Można to zrobić w pętli mając listę sekwencji ze zbioru walidacyjnego.while read p; do python demo.py --detection_path ../results/011-best-val/detection/$p.txt --output_path ../results/011-best-val/iou/$p.txt --format motchallenge; done < ../filelists/011-val-seq
V-IoU Tracking
Do uruchomienia metody V-IoU będą Ci potrzebne zdjęcia ze zbioru treningowego.
Korzystając z tego samego repozytorium możemy uruchomić śledzenie IoU, które dodatkowo korzysta z informacji o obrazie (Visual-IoU Tracking). O tej metodzie możesz więcej przeczytać tutaj. Poniżej wywołanie.while read p; do python demo.py --detection_path ../results/011-best-val/detection/$p.txt --output_path ../results/011-best-val/viou/$p.txt --format motchallenge --frames_path ../train/$p/img1/{:06d}.jpg --visual KCF; done < ../filelists/011-val-seq
norfair
Ostatni tracker, który chciałabym Ci pokazać korzysta z Filtra Kalmana i tym razem będziemy musieli napisać trochę kodu – notebook znajdziesz w repozytorium projektu. Po jego wykonaniu wyniki znajdą się w katalogu results/011-best-val/norfair.
Omówmy teraz kod krok po kroku. W pierwszej kolejności wykonamy importy.
import json
import os
import numpy as np
from tqdm import tqdm
from glob import glob
from norfair import Detection, Tracker, FilterSetup
Następnie musimy zdefiniować funkcję liczącą odległość między wykrytym a śledzonym obiektem. Jest ona potzrebna, ponieważ tracker posiada próg odległości – aby obiekt był rozpatrywany jako należący do tracku, maksymalna odległośc dzieląca go od obiektu z poprzedniej klatki nie może być większa niż zadany próg.
def euclidean_distance(detection, tracked_object):
detection_center = detection.points[0, :]
tracked_center = tracked_object.estimate[0,:]
return np.linalg.norm(detection_center - tracked_center
Następnie potrzebujemy funkcji, która przekonwertuje nam współrzędne bounding-boxa z formatu MOT do np.array (tego wymaga od nas norfair). Oprócz współrzędnych lewego górnego rogu prostokąta oraz jego wymiarów, znalazły się tam także współrzędne środka, ponieważ to one są wykorzystywane przy liczeniu odległości.
def get_coordinates(candidate):
xmin,ymin,w,h = candidate[2:6]
xc=int(xmin+w/2)
yc=int(ymin+h/2)
return np.array([[xc, yc],
[xmin, ymin],
[w, h]])
Poniżej pełna funkcja, która na podstawie jednego pliku z detekcjami, zapisuje plik wynikowy śledzenia.
def track_dir(det_path, out_path, tracker, W=400, H=320):
anns = [x.rstrip().split(',') for x in open(det_path)]
anns = [list(map(float, lst)) for lst in anns]
anns.sort(key=lambda x: x[0])
frames = set([x[0] for x in anns])
mot_objs = []
for frame in frames:
frame_objects = [x for x in anns if x[0]==frame]
frame_objects = [x for x in frame_objects if x[6]>=0.2]
detections = [Detection(get_coordinates(candidate), data=candidate)
for candidate in frame_objects]
tracked_objects = tracker.update(detections=detections)
if len(tracked_objects) == 0:
continue
for tracked_object in tracked_objects:
if not tracked_object.live_points.any():
continue
bbox = [int(tracked_object.estimate[1,0]),int(tracked_object.estimate[1,1]),
int(tracked_object.estimate[2,0]),int(tracked_object.estimate[2,1])]
if len(tracked_object.last_detection.data) == 9:
adds = tracked_object.last_detection.data[-3:]
adds = [int(x) for x in adds[-3:]]
elif len(tracked_object.last_detection.data) == 10:
adds = tracked_object.last_detection.data[-4:]
adds = [adds[-4]]+[int(x) for x in adds[-3:]]
else:
print('Invalid format')
break
mot_obj = [int(frame), tracked_object.id] + bbox + adds
mot_objs.append(mot_obj)
with open(out_path, 'w') as f:
for obj in mot_objs:
line = ','.join([str(x) for x in obj])
f.write('%s\n' % line)
Omówmy tę funkcję krok po kroku. W pierwszej kolejności wczytywane są detekcje z pliku, a następnie wyznaczany jest zbiór klatek, na których zostały wyryte jakieś obiekty.
anns = [x.rstrip().split(',') for x in open(det_path)]
anns = [list(map(float, lst)) for lst in anns]
anns.sort(key=lambda x: x[0])
frames = set([x[0] for x in anns])
Następnie w pętli, klatka po klatce wyznaczam wykryte w tejże klatce obiekty oraz tworzę na ich podstawie obiekty Detection.
frame_objects = [x for x in anns if x[0]==frame]
frame_objects = [x for x in frame_objects]
detections = [Detection(get_coordinates(candidate), data=candidate)
for candidate in frame_objects]
A następnie wykonywany jest update śledzonych obiektów – tutaj pod spodem wykryciom przyporządkowywane są odpwiednie id.
tracked_objects = tracker.update(detections=detections)
Następnie iteruję po śledzonych obiektach i konwertuję je do formatu MOT.
for tracked_object in tracked_objects:
if not tracked_object.live_points.any():
continue
bbox = [int(tracked_object.estimate[1,0]),int(tracked_object.estimate[1,1]),
int(tracked_object.estimate[2,0]),int(tracked_object.estimate[2,1])]
if len(tracked_object.last_detection.data) == 9:
adds = tracked_object.last_detection.data[-3:]
adds = [int(x) for x in adds[-3:]]
elif len(tracked_object.last_detection.data) == 10:
adds = tracked_object.last_detection.data[-4:]
adds = [adds[-4]]+[int(x) for x in adds[-3:]]
else:
print('Invalid format')
break
mot_obj = [int(frame), tracked_object.id] + bbox + adds
mot_objs.append(mot_obj)
Pozostaje zapis wyników do pliku.
with open(out_path, 'w') as f:
for obj in mot_objs:
line = ','.join([str(x) for x in obj])
f.write('%s\n' % line)
No i na koniec uruchomienie śledzenia w pętli dla wszystkich sekwencji.
for det_path in tqdm(glob('./results/011-best-val/detection/*.txt')):
tracker = Tracker(distance_function=euclidean_distance,
distance_threshold=20,
hit_inertia_min=8,
hit_inertia_max=15,
initialization_delay=1,
filter_setup=FilterSetup(R=6,Q=0.1,P=15))
seq = os.path.splitext(det_path.split(os.sep)[-1])[0]
out_path = os.path.join('./results/011-best-val/norfair', '%s.txt' % seq)
os.makedirs(os.path.dirname(out_path), exist_ok=True)
track_dir(det_path, out_path, tracker)
Na sam koniec zostawiłam definicję trackera, którą możesz zobaczyć powyżej.
tracker = Tracker(distance_function=euclidean_distance,
distance_threshold=20,
hit_inertia_min=8,
hit_inertia_max=15,
initialization_delay=1,
filter_setup=FilterSetup(R=6,Q=0.1,P=15))
O parametrach możesz więcej przeczytać w dokumentacji norfair.
Parametry są dobrane bez większego namysłu (dotyczy to norfair jak i IoU/V-IoU), więc warto mieć to na uwadze przy analizie wyników. Dobrym pomysłem byłoby automatyczne dobranie hiperparametrów, o którym więcej możesz przeczytać w poście Alicji.
Zwizualizujmy wyniki
Aby wygenerować wizualizację należy uruchomić skrypt visualizeMOT.pypython MOT/visualizeMOT.py --imgs train --mot_dir results/011-best-val/iou --out_dir results/011-best-val/iou --img_mot
A tak wyglądaja przykładowe wyjście:

W analogiczny sposób zwizualizujemy wyniki V-IoU…python MOT/visualizeMOT.py --imgs train --mot_dir results/011-best-val/viou --out_dir results/011-best-val/viou --img_mot
… oraz norfairpython MOT/visualizeMOT.py --imgs train --mot_dir results/011-best-val/norfair --out_dir results/011-best-val/norfair --img_mot
Jak zweryfikować jakość śledzenia obiektów?
W przypadku śledzenia obiektów, tak jak w innych zagadnieniach oblicza się stosowne metryki, które pozwalają ocenić jak dobrze model radzi sobie z zadaniem. O metrykach MOT możesz przeczytać więcej na stronie MOT Challenge w zakładce results (na przykład tutaj) oraz w readme oficjalnego repozytorium do ewaluacji MOT.
Ja do obliczenia metryk MOT użyłam kodu z innego repozytorium. Korzystałam z niego ostatnio przy innym projekcie i moim zdaniem jest mega wygodne (nie mówię, że oficjalne nie jest, po prostu nie próbowałam).git clone https://github.com/cheind/py-motmetrics.git && cd py-motmetricspython -m motmetrics.apps.eval_motchallenge ../train ../results/011-best-val/ioupython -m motmetrics.apps.eval_motchallenge ../train ../results/011-best-val/vioupython -m motmetrics.apps.eval_motchallenge ../train ../results/011-best-val/norfair
W ten sposób otrzymamy szczegółowe informacje o metrykach dla każdej z sekwencji oraz uśredniony wynik OVERALL dla obu metod śledzenia. Poniżej wartości metryk OVERALL.
| IDF1 | IDP | IDR | Rcll | Prcn | GT | MT | PT | ML | FP | FN | IDs | MOTA | MOTP | |
| OVERALL IoU | 46.5% | 49.6% | 43.7% | 64.2% | 72.9% | 374 | 137 | 178 | 59 | 54413 | 81299 | 1864 | 39.5% | 0.295 |
| OVERALL v-IoU | 45.4% | 48.4% | 42.7% | 64.2% | 72.8% | 374 | 137 | 178 | 59 | 54528 | 81297 | 1968 | 39.4% | 0.296 |
| OVERALL norfair | 52.0% | 54.1% | 50.0% | 65.3% | 70.6% | 374 | 134 | 184 | 56 | 61925 | 78829 | 1107 | 37.6% | 0.298 |
Wyjaśnijmy oznaczenia metryk, które znalazły się w powyższej tabeli.
- IDF1 – F1 (dotyczy śledzenia obiektów)
- IDP – Precision (dotyczy śledzenia obiektów)
- IDR – Recall (dotyczy śledzenia obiektów)
- Rcll – Recall (dotyczy detekcji)
- Prcn – Precision (dotyczy detekcji)
- MT – Mostly Tracked (liczba obiektów, które są śledzone przez conajmniej 80% czasu życia)
- PT – Partially Tracked (liczba obiektów śledzonych między 20% a 80% czasu życia)
- ML – Mostly Lost (liczba obiektów śledzonych przez mniej niż 20% czasu życia)
- FP – False-Positives
- FN – False-Negatives
- IDs – Identity Switches
- MOTA – Multiple Object Tracker Accuracy
- MOTP – Multiple Object Tracker Precision
Podsumowanie
Mam nadzieję, że udało mi się w tym poście przybliżyć Ci kilka stosunkowo prostych metod, które możemy wykorzytsać do śledzenia obiektów. Niestety nie udało nam się w tym roku wziąć udziału w konkursie – może za rok 🙂
Fajnie by było wykonać także inferencję na zbiorze testowym – jeśli chcesz spróbować swoich sił, stąd możesz pobrać wytrenowany przez nas model.
Na koniec dorzucam jeszcze wizualizację wyników na jednym z filmów – od lewej IoU, V-IoU i norfair.
Przydatne linki
- Repozytorium projektu – https://github.com/deepdrivepl/CTMC-v1-solution
- Strona MOT Challenge – https://motchallenge.net/
- Repozytorium Trackingu IoU/V-IoU – https://github.com/bochinski/iou-tracker
- Publikacja dotycząca śledzenia IoU – http://elvera.nue.tu-berlin.de/files/1517Bochinski2017.pdf
- Publikacja dotycząca sledzenia V-IoU – http://elvera.nue.tu-berlin.de/files/1547Bochinski2018.pdf
- Repozytorium norfair – https://github.com/tryolabs/norfair
- Repozytorium py-motmetrics – https://github.com/cheind/py-motmetrics
- Link do pobrania wytrenowanego przez nas modelu – https://www.dropbox.com/s/kivz7s1dfyp4ndg/011-v4_best.weights?dl=1