W tym wpisie pokażę Tobie jak wytrenować YOLOV4 mając zbiór z oznaczonymi obiektami. Wszystko się będzie działo na przykładzie migracji komórek ze zbioru CTMC-v1. Zbiór ten jest częścią MOT Challange – konkursu śledzenia wielu obiektów na obrazie jednocześnie. W tym wpisie skupiam się jedynie na kwestii wykrywania – czyli jak, mając zbiór danych, wytrenować sieć do wykrywania obiektów. Potem te wykrycia możemy wykorzystać do śledzenia obiektów, ale to już w osobnym wpisie, ok?
MOT Challenge CTMC-v1
Nie mam żadnego przygotowania domenowego w dziedzinie biologii. Zaznaczam to, na szczęście dane są już oznaczone przez ekspertów domenowych zwanych prawdopodobnie lekarzami. Wedle opisu ze strony zawodów w zadaniu chodzi o śledzenie migracji komórek w celu lepszego zrozumienia podstawowych biologicznych procesów. Dzięki temu oczekuje się również rozwoju i lepszego zrozumienia leków i odpowiedzi immunologicznej.
Zbiór danych, jak podano, jest oznaczony przez ludzi, co napawa optymizmem, bo automatyczne systemy robią błędy specyficzne. Zbiór ten zwiera oznaczenia komórek jako prostokąty wyrównane do osi zdjęcia wraz z unikalnym identyfikatorem dla każdej z komórek. Czyli na kolejnych klatkach wiemy, która komórka jest która, albo raczej która ramka to która na sąsiednich klatkach filmu. Zbiór zawiera 86 filmów z żyjącymi komórkami, o różnych kształtach i rozmiarach. Ta różnorodność wynika z faktu, że wykorzystano 14 linii komórkowych (14 cell lines).
Faktem jest, że są to zawody – wygrywa zespół, który uzyska najwyższy średni wynik MOTA. Deadline dla wysyłania wyników to piątek 21 maja 2021 17:59 CST.
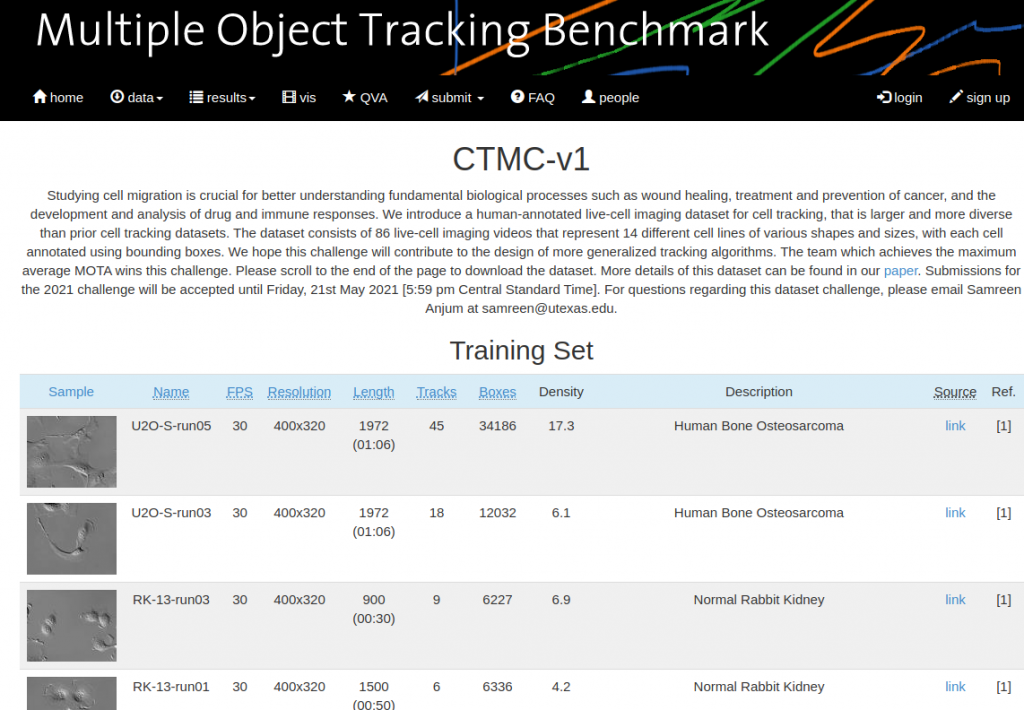
Link do konkursu: https://motchallenge.net/data/CTMC-v1
Jak wygląda zbiór danych?
CTMC-v1 to zbiór filmów podzielony na trening i test. Do treningu otrzymujemy 47 sekwencji, natomiast testowych sekwencji jest 39. Testowe sekwencje nie posiadają annotacji. Oprócz samego materiału źródłowego otrzymujemy również informację o lokalizacji obiektów za pomocą prostokątnych ramek wyrównanych do brzegów obrazu – AABB (Axis Aligned Bounding Boxes). Oprócz ramki mamy także unikatowy identyfikator dla każdego śledzonego obiektu.
Wszystkie klatki filmów w zbiorze są w skali szarości – nie ma tam kolorów, tylko odcienie od czarnego do białego, dominujący jest szary kolor tła. Każdy z filmów w obu zbiorach jest tej samej wielkości 400x320px. Wszystkie nagrane są z prędkością 30 fps. Dane do pobrania to zaledwie 768MB. Można również pobrać same etykiety – 3.7MB. Sekwencje są zapisane jako pliki jpg.
Poniżej zwizualizaowane dane treningowe – widzimy 2 filmy z dwóch sekwencji. Jedna z nich ma dość mało komórek, ta druga natomiast nieco więcej. W zbiorze otrzymujemy unikatowe identyfikatory, więc poniższe filmy mogły mieć kolorowe ramki wg object-id. Pozostałem przy prostszej wizualizacji z dwóch powodów – więrzę że tracking zrobili dobrze oraz nie będę wykorzystywał danych ze śledzeniem do uczenia.
Powyższe filmy wygenerowałem klatka po klatce po konwersji annotacji do formatu YOLO. W celu utworzenia filmu użyłem ffmpeg z opcją glob (uwielbiam).
Plan działania
Mój plan działania jest następujący:
- Przygotować dane
- Wytrenować baseline YOLOv4 bez data augmentation na 80% klatek zbioru uczącego, reszta to będzie walidacja (bez podziału na sekwencje, losowe 80%)
- Dodać tracking
- Zrobić submission rozwiązania baseline
- Iteracyjnie poprawiać wyniki
Data augmentation – pomysły na przyszłe iteracje:
- obrót całego obrazu o 90, 180, 270
- lustrzane odbicie w poziomie i w pionie
Pierwszy trening mimo wszystko będzie mieć augmentację – zmieniać się będzie jasność obrazu oraz wykorzystam mozaikę. Jasność niekoniecznie pomoże w kontekście tego jak wyglądają dane, ale tak postanowiłem już, więc trudno dyskutować z faktami. Odnośnie mozaiki – miewam mieszane uczucia, czasem jestem zadowolony, czasem nie, ale już to wrzuciłem w pierwszy trening, więc jest.
Przygotowanie Darknetu
Aby wszystko mogło się zadziać potrzebujemy zbudować darknet u siebie na komputerze. Skorzystamy oczywiście z wersji Alexeya ze względu na fakt, że to on dodał YOLOv4 i później Scaled YOLOv4.
Skorzystaj z instrukcji z poprzedniego posta:
Wykrywanie komórek na obrazie z wykorzystaniem YOLOv4
Przygotowanie katalogów do treningu
Po pobraniu zbioru danych otrzymujemy katalog CTMCCVPR20, a w nim katalogi z danymi – train i test. W katalogu test nie znajdziesz etykiet, tylko zdjęcia i nazwy sesji. Natomiast katalog train jest dla nas super interesujący, bo tam dodatkowo mamy etykiety. Nie są one w formacie do treningu w Darknecie, tym zająłem się w notebooku konwertującym – patrz poniżej.
Utworzyłem katalogi:
- backups – w nim będą kolejne katalogi z wagamiz treningu
- cfgs – katalog na plik .names oraz pliki .cfg (architektura, augmentation, parametry treningu) i .data (info gdzie są dane)
- filelists – katalog zawierający listy plików train i val dla kolejnych treningów
- scripts – katalog na skrypty – generujące listy plików, skrypty do treningu
Tak wygląda nasz katalog z danymi do treningu:
train/
├── 3T3-run01
│ ├── gt
│ ├── img1
│ ├── seqinfo.ini
│ └── TRA
├── 3T3-run03
│ ├── gt
│ ├── img1
│ ├── seqinfo.ini
│ └── TRA
├── 3T3-run05
│ ├── gt
│ ├── img1
│ ├── seqinfo.ini
│ └── TRA
...
Uzyskałem powyższe poprzez wywołanie na Ubuntu komendy: tree train/ -L 2
W katalogu train znajdziesz 47 katalogów z sekwencjami jak wyżej. W katalogu gt jest plik gt.txt, a w nim znajduje się informacja o położeniu obiektów na obrazach w sekwencji. W katalogu img1 znajdziesz sekwencję obrazów. W katalogu TRA znajdziesz zawsze plik TRA/man_track.txt z informcjami na jakich klatkach widać które obiekty – to nas obecnie nie interesuje.
W katalogu test jak poniżej widzisz nie ma już informacji o tym co widać na obrazie, są tylko sekwencje obrazów i plik seqinfo.ini
test/
├── 3T3-run02
│ ├── img1
│ └── seqinfo.ini
├── 3T3-run04
│ ├── img1
│ └── seqinfo.ini
├── 3T3-run06
│ ├── img1
│ └── seqinfo.ini
Dla formalności – jak wygląda plik seqinfo.ini – plik, którego obecnie do niczego nie używam, podobnie jak man_track.txt. Stąd można odczytać rozmiar plików, ich liczbę, nazwę katalogu i rozszerzenie plików z obrazami.
[Sequence]
name=PL1Ut-run05
imDir=img1
frameRate=30
seqLength=1470
imWidth=400
imHeight=320
imExt=.jpg
Niech pozostałe ktalogi obok train i test będą obecnie puste, ok? Przygotujmy teraz dane!
Przygotowanie danych do formatu YOLO
Jak wyglądają nasze etykiety obecnie? Znajdują się zawsze w plikach gt/gt.txt. Przykład wygląda tak (pierwsze 20 wierszy):
1,1,234,101,123,119,1,-1,-1
2,1,234,101,123,120,1,-1,-1
3,1,234,100,123,120,1,-1,-1
4,1,234,100,123,120,1,-1,-1
5,1,233,100,123,120,1,-1,-1
6,1,233,99,122,120,1,-1,-1
7,1,233,99,122,121,1,-1,-1
8,1,233,99,122,121,1,-1,-1
9,1,233,98,122,121,1,-1,-1
10,1,233,98,122,121,1,-1,-1
11,1,233,97,122,122,1,-1,-1
12,1,233,97,122,122,1,-1,-1
13,1,233,97,121,122,1,-1,-1
14,1,232,96,121,122,1,-1,-1
15,1,232,96,121,123,1,-1,-1
16,1,232,96,121,123,1,-1,-1
17,1,232,95,121,123,1,-1,-1
18,1,232,95,121,123,1,-1,-1
19,1,232,95,121,123,1,-1,-1
20,1,232,94,121,124,1,-1,-1
Interesuje nas 5 kolumn – pierwsza z numerem klatki oraz cztery od trzeciej począwszy – tam jest x1, y1, w, h czyli współrzędne ramki wokół obiektu – współrzędne lewego górnego rogu oraz szerokość i wysokość ramki. Nazwy kolumn, które nas interesują (object_id w sumie nie, ale jest):
frame_num, object_id, x1, y1, w, h, …
Współrzędne są w pikselach, więc na potrzeby yolo musimy je znormalizować przez wielkość obrazu, która jest stała dla wszystkich sekwencji – 400×320. Dlatego też te wartości wpisałem na stałe, w ogólnym przypadku warto odczytać rozmiar z obrazu. Poniższy kod dla każdego katalogu wczytuje dane Ground Truth (stąd gt), tworzy wszystkie pliki annotacji i wpisuje do nich informacje o położeniu obiektów.
Poniższy kod konwertuje format annotacji, ja mam go w notebooku w pliku convert-anno-to-darknet-format.ipynb. Zadziała także gdyby to był plik .py, po prostu w ten sposób go tworzyłem interaktywnie.
from glob import glob
import cv2
import matplotlib.pyplot as plt
dirs=glob('train/*')
print(dirs)
width=400
height=320
for _d in dirs:
images=glob(_d+'/img1/*.jpg')
print(len(images))
# create empty annotation files per image
for img_fname in images:
with open(img_fname.replace('.jpg','.txt'),'w'):
pass
with open(_d+'/gt/gt.txt') as f:
data = f.read().split('\n')
if len(data[-1])==0:
data=data[:-1]
data=[[float(__) for __ in _.split(',')] for _ in data]
for d in data:
fname = _d+'/img1/%06d.txt'%int(d[0])
x1,y1,w,h = d[2:6]
xc=x1 + 0.5 * w
yc=y1 + 0.5 * w
w/=width
h/=height
xc/=width
yc/=height
# Append object to annotation file
with open(fname,'a') as fout:
# Class 0, since we have only 1 class
fout.write('0 %f %f %f %f\n'%(xc,yc,w,h))
Przykładowy plik .txt z annotacjami w postaci YOLO wygląda jak poniżej:
0 0.738750 0.507812 0.307500 0.371875
0 0.242500 0.596875 0.305000 0.337500
Wartości są rozdzielone pojedynczą spacją, jedna linia per obiekt, jeden plik txt per zdjęcie. W linii po kolei:
- klasa numerowana od zera
- xc – środek ramki, współrzędna pozioma, we współrzędnych znormalizowanych 0..1
- yc – środek ramki, współrzędna pionowa, we współrzędnych znormalizowanych 0..1
- w – szerokość ramki we współrzędnych znormalizowanych 0..1
- h – wysokość ramki we współrzędnych znormalizowanych 0..1
Uwaga powyższy kod generuje złe ramki – wystają poza obraz. Warunek xc+0.5*w<1.0 nie jest spełniony, podobnie dla y, podobnie dla drugiego końca zakresu – blisko zera. Pierwszy trening uruchamiam nie przejmując się tym faktem. Darknet informuje o tych błędach, tworzy także listę plików z błędami.
Przygotowanie konfiguracji modelu i treningu
To jest moment na wybór architektury modelu – ja wybieram YOLOv4, gdyż chcę by było dokładnie, nie musi być szybko. Kopiujemy plik z konfiguracją i będziemy go modyfikować:
cp ~/darknet/cfg/yolov4-custom.cfg cfgs/000-v4.cfg
Potrzebujemy zmienić kilka rzeczy, gdyż plik cfg jest przygotowany pod 80 klas ze zbioru COCO. Zmieniamy oczywiście liczbę klas z 80 na 1 oraz związaną z tym liczbę filtrów wynikającą z liczy klas – z 255 na 18, liczba ta wynika ze wzoru (liczba_klas + 5)*3 czyli w tym przypadku: (1+5)*3=18. Zmiany wprowadzamy w 3 miejscach w pliku.
- classes=80 ==> classes=1
- filters=255 ==> filters=18
Obrazy są w skali szarości, więc modyfikuję data augmentation:
- saturation = 1.5 ==> saturation = 0
- exposure = 1.5 ==> exposure = 2
- hue=.1 ==> hue=0
Trening na laptopie, więc eksperymentalnie zwiększam subdivisions, aż się zmieści w GPU RAM. Te wartości ustalisz przy uruchomieniu treningu. Rozdzielczość zmniejszam, bo pliki są małe.
- subdivisions=16 ==> subdivisions=32
- width=608 ==> width=416
- height=608 ==> height=416
Parametr subdivisions definiuje na ile kroków podzielony będzie batch – czyli przy wartości 32, 1 batch 64 zdjęć będzie trwać 32 kroki po 2 zdjęcia w pamięci GPU naraz. To istotny koncept – gradient accumulation – serializujemy obliczenia mając zbyt małe zasoby.
Tak wygląda początek pliku cfgs/000-v4.cfg:
[net]
# Testing
#batch=1
#subdivisions=1
# Training
batch=64
subdivisions=32
width=416
height=416
channels=3
momentum=0.949
decay=0.0005
angle=0
saturation = 0
exposure = 2
hue=0
learning_rate=0.001
burn_in=1000
max_batches = 500500
policy=steps
steps=400000,450000
scales=.1,.1
#cutmix=1
mosaic=1
Plik cfg już jest, teraz czas na plik cfgs/000-v4.data. Przygotowałem go w następujący sposób:
classes= 1
train = ../filelists/000-train
valid = ../filelists/000-val
names = ../cfgs/cells.names
backup = ../backups/000-backup
eval=coco
Plik ten informuje gdzie szukać danych do treningu – list plików, listy klas oraz gdzie zapisywać wagi. Obecnie nie mamy żadnej z tych rzecy gotowych, więc do dzieła.
Katalog na wyniki
Zaznaczam to mocno, bo darknet nie utworzy katalogu, po prostu trening Ci się wysypie na próbie zapisu (serio!). Dla oszczędzenia czasu warto utworzyć katalog za wczasu:
mkdir -p ../backups/000-backup
Lista klas
Plik z listą klas będzie zawierał 1 linię, gdyż mamy 1 klasę. U mnie wygląda następująco:
cell
Podział na train/val – listy plików
W celu automatyzacji podziału utworzyłem sobie skrypt w katalogu scripts. Plik scripts/create_filelists_000.sh wygląda u mnie tak:
find /home/karol/CTMCCVPR20/train -name '*.jpg' > ../filelists/000-all
awk 'NR % 5 != 0' ../filelists/000-all > ../filelists/000-train
awk 'NR % 5 == 0' ../filelists/000-all > ../filelists/000-val
W ten oto chytry sposób:
- Tworzę listę wszystkich plików
- 80% plików przeznaczam na trening
- pozostałe 20% przeznaczam na walidację
Oczywiście można to zrobić za pomocą skryptu w pythonie i zwykle tak to robię, ale tym razem chciałem to mieć na prawdę szybko gotowe.
Trening YOLOv4 na laptopie z RTX2070
Mamy już wszystko czego potrzeba by trenować! Także super, czas przygotować skrypt który uruchomi trening. Będzie to plik scripts/train-000.sh:
~/darknet/build/darknet detector train ../cfgs/000-v4.data ../cfgs/000-v4.cfg ~/darknet/yolov4.conv.137 -map -dont_show -mjpeg_port 8090
Uwagi:
- Pobierz plik
~/darknet/yolov4.conv.137uprzednio – link znajdziesz w repo Darknetu -mapgeneruje wykresy z loss i mean Average Precision (mAP)-dont_shownie pokazuje okien żadnych – chciałem to mieć w tle-mjpeg_port 8090wysyła wykres mAP poprzez port, więc możesz zajrzeć poprzez przeglądarkę na dowolnym komputerze np.http://localhost:8090
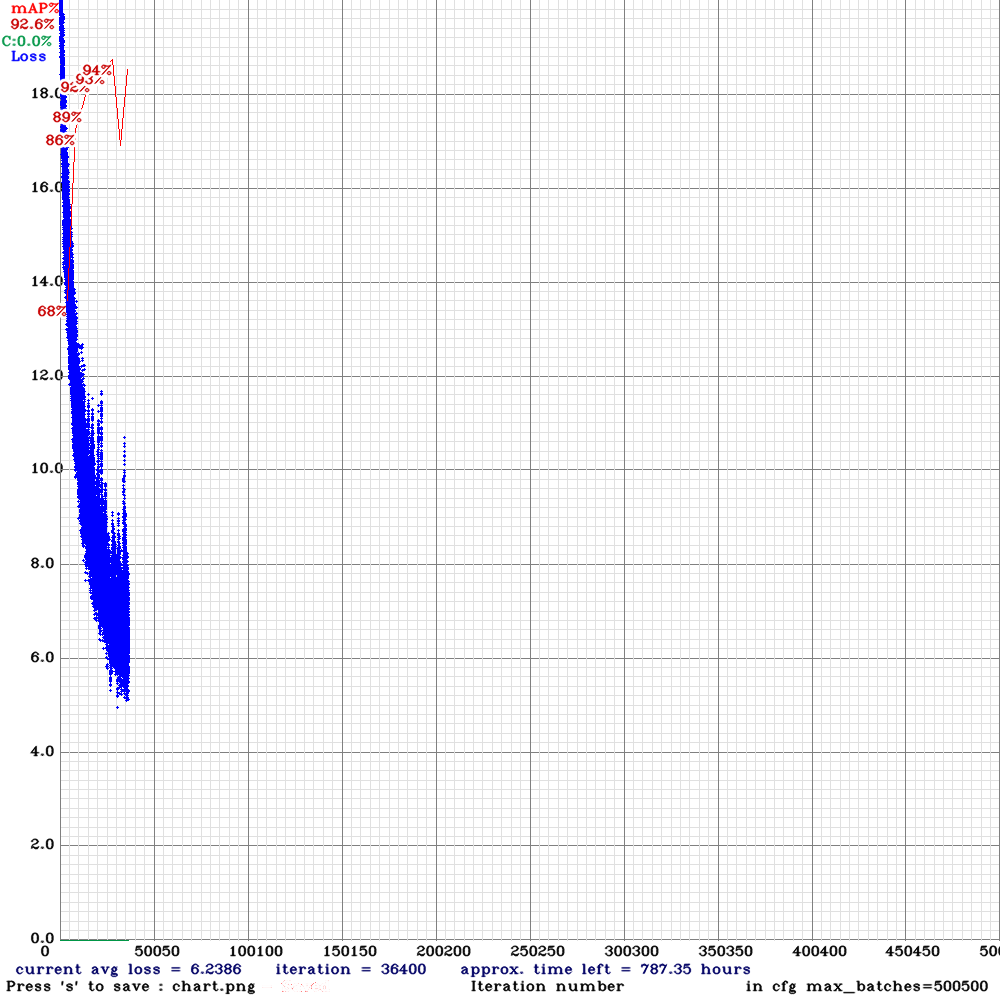
Tak jak widzisz poniżej wygląda wykres mAP dla tego treningu. Trwało to u mnie dobre 24h jak nie dłużej, ale stwierdziłem, że perspektywy są nieciekawe, bo trudno było pracować mając ten trening w tle – zalecam nie trenować na laptopie dłużej niż tydzień, no nie do tego one są, nie?
Pierwsze obliczenie mAP – po 4 epokach.
Trening zapisał poniższe pliki:
../backups/000-backup/
├── 000-v4_30000.weights
├── 000-v4_best.weights
└── 000-v4_last.weights
Są to najlepsze, ostatnie wagi, oraz wagi dla kroku 30000.
Jak interpretować oś x na wykresie? Kiedy mija epoka?
Jedna epoka to przejście dokładnie jeden raz przez wszystkie przykłady ze zbioru uczącego. Czyli przyda się wiedza ile tych przykładów posiadamy. Druga rzecz to krok, wielkość batcha, bo przechodzimy po tym zbiorze, trenujemy batchami. I teraz możemy policzyć ile batchy – kroków uczenia, iteracji – to jedna epoka. Sprawdźmy ile jest przykładów w zbiorze uczącym:
wc -l ../filelists/000-train
64312 ../filelists/000-train
Przykładów jest:
- zdjęć – 64312
- batch size – 64
- iterations per epoch = 64312/64 = 1004,875
W tym przypadku 1 epoka to 1005 kroków
Przeniesienie obliczeń na komputer stacjonarny
Przeniosłem obliczenia na inny komputer, skopiowałem pliki 000 na 001, zmieniłem ścieżki i skróciłem trening 10 razy:
- max_batches = 500500 ==> max_batches = 20000
- steps=400000,450000 ==> steps=10000,15000
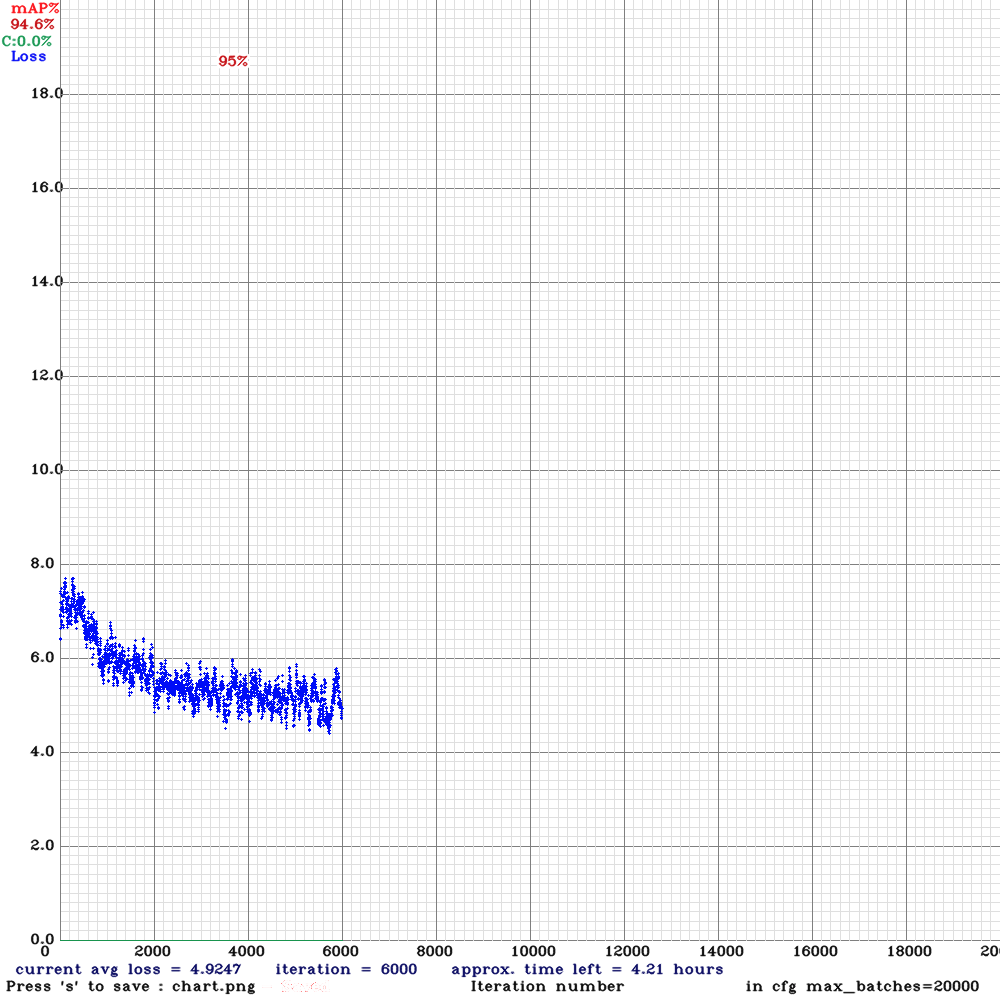
Zmieniłem learning rate na learning_rate=0.0001, oraz uruchomiłem trening na 2 kartach jako kontynuację treningu 000:
~/darknet/build/darknet detector train ../cfgs/001-v4.data ../cfgs/001-v4.cfg ../backups/000-backup/000-v4_best.weights -map -gpus 0,1 -clear -dont_show -mjpeg_port 8090
Aby kontynuować trening podajemy ścieżkę do pliku z wagami oraz dodajemy flagę -clear by zacząć trening od zera, bez clear trening jest kontynuowany (fajne gdy przerwiemy i chcemy dokończyć)
Predykcja!
Najprościej – a tak lubimy – to przygotować listę ścieżek do plików i wykonać predykcję podając listę. Przygotować listę na Linuxie możemy o tak:
cd ..
find $(pwd)/test -name '*.jpg' > test.list
cd scripts
Poniższe polecenie pozwoli nam obejrzeć wyniki modelu 001 wykorzystując najlepsze wagi:
~/darknet/build/darknet detector test ../cfgs/001-v4.data ../cfgs/001-v4.cfg ../backups/001-backup/001-v4_best.weights -thresh 0.25 < ../test.list
Podajemy plik data, plik cfg oraz plik wag. Możemy dostosować próg wykrywania – poniżej niego wykrycia będą odrzucone.
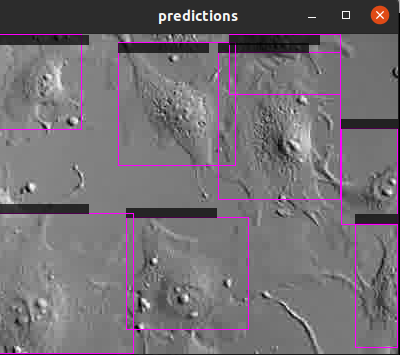
Możemy jeszcze:
- Zapisać predykcje jako etykiety (pseudo-labeling) wykorzystując flagę
-save_labels - Warto dodać
-dont_showwyłączy wyświetlanie każdego obrazu - Możemy zapisać wyniki predykcji do jsona:
-ext_output -out result.json
Podsumowanie
To póki co tyle, ale mam w planie rozwinąć ten wpis o wyniki modelu, oraz część ze śledzeniem, bo to jest dość istotne w tym zadaniu 🙂
Plan się zmienił – śledzenie będzie osobno, a tutaj dodałem jeszcze predykcję.