

Rozpoznawanie znaków drogowych za pomocą CNN – BelgiumTS Dataset
W poprzednim wpisie omówiłam zbiór BelgiumTSC oraz pokazałam w jaki sposób można wytrenować prostą sieć MLP do klasyfikacji znaków drogowych. Ominęła Cię pierwsza część serii? Nic straconego, możesz ją przeczytać pod tym linkiem.
Jeśli jesteś już po lekturze, wiesz, że udało nam się osiągnąć accuracy na zbiorze treningowym na poziomie niecałych 92% – wyniku tego nie udało się poprawić mimo zastosowania trzech różnych metod:
- uwzględnienia wag klas przy liczeniu funkcji kosztu,
- wyrównania liczności klas z wykorzystaniem albumentations (dogenerowania zdjęć),
- augmentacji z tf.keras.layers.experimental.preprocessing.
Pierwsze dwa przekształcenia miały zniwelować wpływ dużej nierównomierności klas, trzecia natomiast miała na celu poprawę zdolności uogólniania. Żadne z nich nie przyniosło oczekiwanych rezultatów. Dlaczego? Jeśli chodzi o augmentację, przychodzą mi do głowy 2 rzeczy: duże podobieństwo danych w zbiorach train i test (przez co augmentacja pogarsza wyniki) oraz fakt, że modele MLP zwyczajnie nie są zdolne do uogólniania. Wagi mogłby poprawić osiągi na mniej licznych klasach jednocześnie pogarszając działanie na tych bardziej licznych, przez co całkowite accuracy uległo pogorszeniu.
Tym razem sprawdzimy jak z tym zadaniem poradzi sobie prosta sieć konwolucyjna. Działanie modeli CNN opiera się na ekstrakcji cech obrazu, przez co augmentacja powinna w tym przypadku zadziałać nieco lepiej. Przynajmniej tak podopowiada intuicja. Czy faktycznie tak jest? Zaraz się przekonasz. Jeśli chcesz, możesz poeksperymentować z kodem w notebooku w Colabie.
Przygotowanie danych
W pierwszej części trochę się namęczyliśmy, żeby otrzymać zbiór w odpowiedniej postaci. Tym razem ułatwimy sobie nieco zadanie – wrzuciłam poprzednio przygotowane dane na dropboxa. Poniższy kod, to wszystko co musimy tym razem zrobić.
!wget -O BelgiumTSC.zip https://www.dropbox.com/s/nl7w2u523zfymlh/BelgiumTSC.zip?dl=1
dataset_zip = 'BelgiumTSC.zip'
zip_ref = zipfile.ZipFile(dataset_zip, 'r')
zip_ref.extractall()
zip_ref.close()
Tutaj, tak jak poprzednio korzystamy z image_dataset_from_directory – nowej funkcjonalności wprowadzonej w TensorFlow 2.3.0. Szerzej omawiałam ją ostatnio, więc żeby się nie powtarzać, wrzucam jedynie definicje zmiennych.
TRAINING_DATA_DIR = 'BelgiumTSC/Training'
TESTING_DATA_DIR = 'BelgiumTSC/Testing'
TARGET_SIZE = 100
BASE_EPOCHS = 100
BASE_LR = 0.01
training_ds = tf.keras.preprocessing.image_dataset_from_directory(
TRAINING_DATA_DIR,
labels="inferred",
label_mode="int",
batch_size=8,
image_size = (TARGET_SIZE, TARGET_SIZE),
shuffle=True,
seed=123)
testing_ds = tf.keras.preprocessing.image_dataset_from_directory(
TESTING_DATA_DIR,
labels="inferred",
label_mode="int",
batch_size=8,
image_size = (TARGET_SIZE, TARGET_SIZE),
shuffle=False)
NUM_CLASSES = len(training_ds.class_names)
AUTOTUNE = tf.data.experimental.AUTOTUNE
training_prefetcher = training_ds.cache().prefetch(buffer_size=AUTOTUNE)
testing_prefetcher = testing_ds.cache().prefetch(buffer_size=AUTOTUNE)
Pierwszy model CNN
Przygotowałam prosty model CNN składający się z czterech warstw konwolucyjnych, po każdej z nich wykonywany jest Max pooling. Oprócz tego, sieć posiada warstwy wykonujące preprocessing, czyli zmieniające rozmiar zdjęć do zadanych wartości (TARGET_SIZE, TARGET_SIZE) oraz skalujące wartości pikseli do warstości między 0 a 1. Po konwolucjach występuje GlobalAveragePooling2D(), którym zastąpiłam Flatten() oraz warstwa Dense(). Poniżej możesz prześledzić architekturę modelu.

Zanim przejdziemy do badania wpływu naszych trzech metod na wyniki sieci, chciałabym Ci pokazać w jaki sposób możemy wykorzystać dropout. Umieszczę go między warstwą GlobalAveragePooling2D() a warstwą Dense(). Co robi dropout i co ma na celu? Jego działanie polega na wyłączaniu ustalonej części połączeń między warstwami w trakcie trenowania sieci. Oznacza to, że jeśli wstawimy warstwę tf.keras.layers.Dropout(0.3), to w każdej epoce wyłączonych zostanie w sposób losowy 30% połączeń (ma to miejsce tylko w czasie treningu, w inferencji wykorzystujemy wszystkie połączenia). Pomaga to zniwelować nadmierne dopasowanie do danych, czyli tak jak augmentacja zmniejsza overfitting.
Sprawdziłam, jaka wartość sprawdza się najlepiej – wykonałam 6 treningów począwszy od wartości 0 (czyli brak dropoutu), kończąc na wartości 0.5 (czyli ignorującej 50% połączeń). Poniżej możesz zobaczyć jak w każdym z przypadków kształtowała się wartość accuracy na danych testowych.
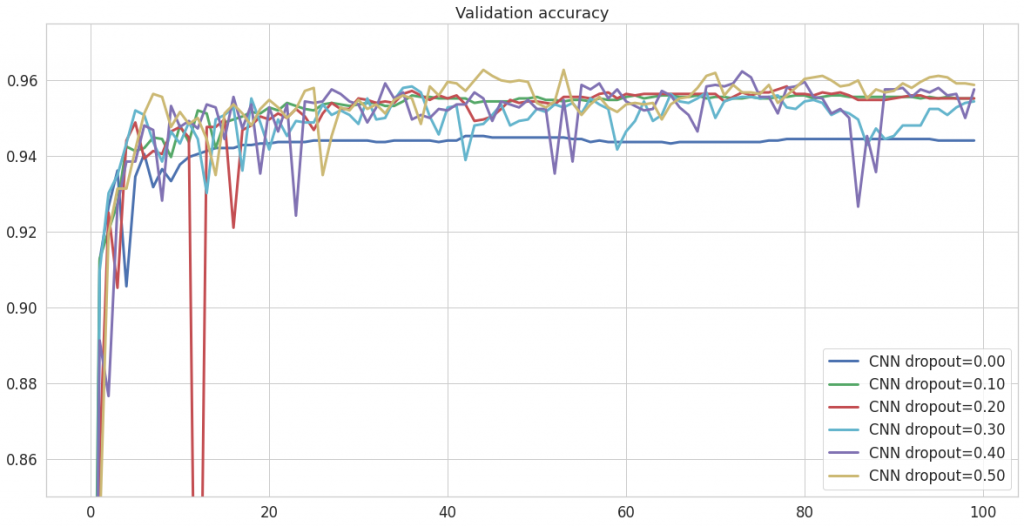
Dwie rzecze widoczne są na pierwszy rzut oka: niezależnie od jego wartości, dropout zawsze poprawia wyniki oraz destabilizuje przebieg accuracy. Destabilizacja wydaje się być tym większa, im wyższy dropout. Moim zdaniem, złotym środkiem będzie wybór dropout=0.2, ponieważ wahania accuracy są tutaj mało zauważalne, szczególnie w końcowym odcinku.
Zdecydowałam się wykorzystać dropout o takiej wartości (0.2) w dalszych eksperymantach. Czym dokładnie one będą? Prześledzimy najpierw wyniki modelu bez dropoutu, następnie go dodamy oraz przetestujemy wpływ wag, preprocessingu oraz augmentacji. Następnie pobawimy się trochę kombinacjami wcześniej wymienionych.
Jak zdefiniować i wytrenować model CNN?
Powyżej pokazałam Ci, jak wygląda architektura modelu, ale w jaki sposób ją zdefiniowałam? Tutaj możesz przeanalizowac kod.
model = tf.keras.models.Sequential([
tf.keras.layers.experimental.preprocessing.Resizing(TARGET_SIZE, TARGET_SIZE),
tf.keras.layers.experimental.preprocessing.Rescaling(1./255),
tf.keras.layers.Conv2D(32, (3,3), activation='relu', input_shape=(TARGET_SIZE, TARGET_SIZE, 3)),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Conv2D(64, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(128, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(128, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.GlobalAveragePooling2D(),
tf.keras.layers.Dense(NUM_CLASSES, activation='softmax')
])
Dalej wszystko przebiega dokładnie tak samo, jak dla modelu MLP. Zanim przystąpimy do treningu, musimy zbudować i skompilować sieć.
model.build(input_shape=(None, TARGET_SIZE, TARGET_SIZE, 3))
model.compile(optimizer=tf.keras.optimizers.SGD(learning_rate=BASE_LR), loss='sparse_categorical_crossentropy', metrics=['accuracy'])
model.summary()
history = model.fit(
training_prefetcher,
epochs = BASE_EPOCHS,
verbose = 1,
validation_data = testing_prefetcher
)
Oprócz powyższego, czyli podstawowego modelu, wytrenowałam jeszcze 4 inne: z dropoutem, wagami klas, warstwami preprocessing i augmentacją z zapisem na dysk. Nie będę tutaj analizować krok po kroku jak przebiega przygotowanie wag i preprocessing, bo to szczegółowo omówiłam w poprzednim wpisie. Jeśli potrzebujesz przypomnienia, możesz też sięgnąć do colaba. Przedstawię jednak definicję wszystkich modeli.
dropout + CNN
Jedyna różnica, która tutaj występuje to obiecana warstwa Dropout(0.2).
model_dropout = tf.keras.models.Sequential([
tf.keras.layers.experimental.preprocessing.Resizing(TARGET_SIZE, TARGET_SIZE),
tf.keras.layers.experimental.preprocessing.Rescaling(1./255),
tf.keras.layers.Conv2D(32, (3,3), activation='relu', input_shape=(TARGET_SIZE, TARGET_SIZE, 3)),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Conv2D(64, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(128, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(128, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.GlobalAveragePooling2D(),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(NUM_CLASSES, activation='softmax')
])
Wagi klas + CNN
Tutaj dodajemy wagi klas w model.fit().
model_weights = tf.keras.models.Sequential([
tf.keras.layers.experimental.preprocessing.Resizing(TARGET_SIZE, TARGET_SIZE),
tf.keras.layers.experimental.preprocessing.Rescaling(1./255),
tf.keras.layers.Conv2D(32, (3,3), activation='relu', input_shape=(TARGET_SIZE, TARGET_SIZE, 3)),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Conv2D(64, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(128, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(128, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.GlobalAveragePooling2D(),
tf.keras.layers.Dense(NUM_CLASSES, activation='softmax')
])
model_weights.build(input_shape=(None, TARGET_SIZE, TARGET_SIZE, 3))
model_weights.compile(optimizer=tf.keras.optimizers.SGD(learning_rate=BASE_LR), loss='sparse_categorical_crossentropy', metrics=['accuracy'])
model_weights.summary()
history_weights = model_weights.fit(
training_prefetcher,
epochs = BASE_EPOCHS,
verbose = 1,
validation_data = testing_prefetcher,
class_weight = class_weight_dict
)
preprocessing + CNN
Przekształcenia z tf.keras.layers.preprocessing są identyczne do tych, które wykorzystałam w MLP. Reszta modelu pozostaje bez zmian względem poprzednich. Z racji tego, że dodane warstwy służą jedynie prepocessingowi, nie doszły żadne nowe parametry, któreych nasza sieć będzie się uczyła.
model_preprocessing = tf.keras.models.Sequential([
tf.keras.layers.experimental.preprocessing.Resizing(TARGET_SIZE, TARGET_SIZE),
tf.keras.layers.experimental.preprocessing.RandomRotation(0.1),
tf.keras.layers.experimental.preprocessing.RandomZoom(0.1),
tf.keras.layers.experimental.preprocessing.Rescaling(1./255),
tf.keras.layers.Conv2D(32, (3,3), activation='relu', input_shape=(TARGET_SIZE, TARGET_SIZE, 3)),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Conv2D(64, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(128, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(128, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.GlobalAveragePooling2D(),
tf.keras.layers.Dense(NUM_CLASSES, activation='softmax')
])
W przypadku tego modelu, z racji dodania kilku początkowych warstw, warto spojrzeć na wynik model.summary(). W postumowaniu, możesz zauważyć, że zgodnie z moimi zapewnieniami, liczba parametrów uczonych przez nas nie uległa zmianie.

augmentation + CNN
Tutaj też pozostajemy z naszym podstawowym modelem zdefiniowanym na początku.
model_aug = tf.keras.models.Sequential([
tf.keras.layers.experimental.preprocessing.Resizing(TARGET_SIZE, TARGET_SIZE),
tf.keras.layers.experimental.preprocessing.Rescaling(1./255),
tf.keras.layers.Conv2D(32, (3,3), activation='relu', input_shape=(TARGET_SIZE, TARGET_SIZE, 3)),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Conv2D(64, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(128, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(128, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.GlobalAveragePooling2D(),
tf.keras.layers.Dense(NUM_CLASSES, activation='softmax')
])
Wyniki
No właśnie, teraz w końcu uzyskamy odpowiedź na postawione we wstępie pytanie. Czy tym razem któraś z tych metod zadziała i uda nam się dzięki niej poprawić wyniki modelu? Spójrzmy na wykresy accuracy na zbiorach treningowym i testowym.
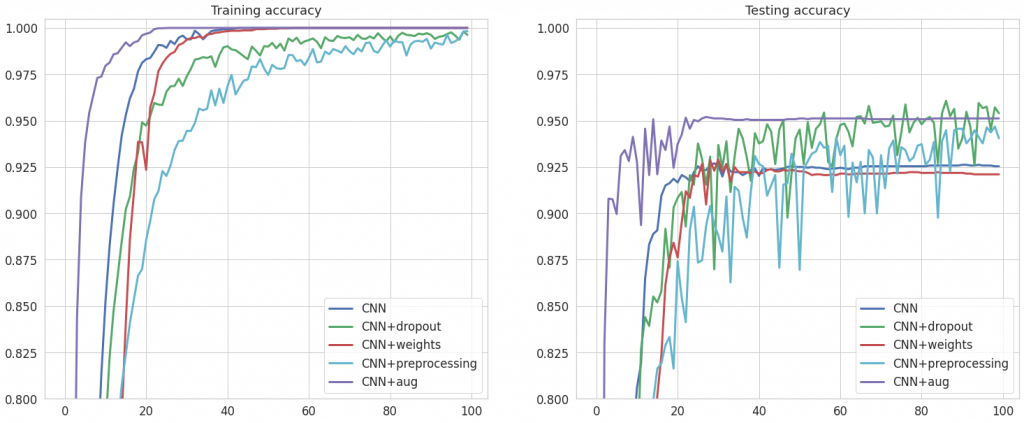
Dobra wiadomość! Tym razem możemy stwierdzić, że wszystkie metody poprawiają wyniki na zbiorze testowym – no, może oprócz wag (tutaj accuracy praktycznie nie uległo zmianie). Jak pamiętasz, z wykorzystaniem MLP udało nam się osiągnąć precyzję na poziomie 92%, czyli poprawiliśmy wynik o 4 punkty procentowe. Idziemy w dobrym kierunku!
A co gdyby połączyć dropout, preprocessing i augmentację i zastosować je wszystkie na raz? Pominęłam więc wagi, których wykorzystanie nie miałoby teraz sensu, ponieważ skorzystamy z rozszerzonego zbioru (po augmentacji), w którym wyrównaliśmy liczebność klas. Poniżej efekt takiego rozwiązania.
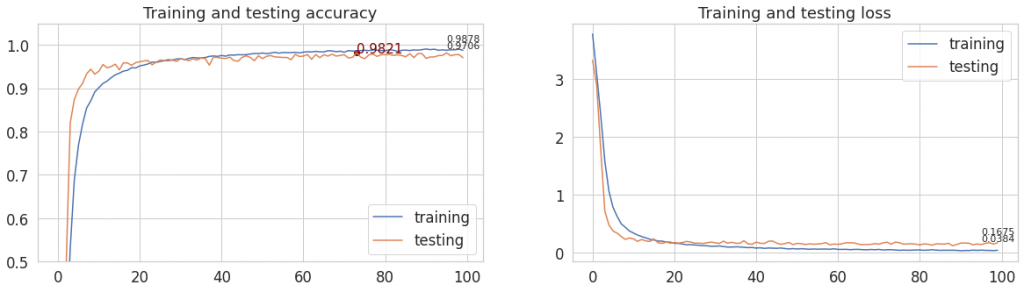
Mamy rekord! Przekroczyliśmy 98%. Czy uda nam się poprawić ten wynik?
Wykonałam kilka eksperymentów, których nie ma w dołączonym notebooku (ale zachęcam Cię do ich samodzielnego wykonania w ramach ćwiczeń). Chciałam znaleźć najlepszą kombinację spośród przedstawionych metod. W efekcie powstała tabela, w której zapisuję maksymalne accuracy na zbiorze testowym.
| dropout | class weights | preprocessing | augmentation | max val accuracy [%] |
|---|---|---|---|---|
| 92.70 | ||||
| x | 96.07 | |||
| x | 92.90 | |||
| x | 94.68 | |||
| x | 95.20 | |||
| x | x | 97.58 | ||
| x | x | 97.02 | ||
| x | x | x | 96.94 | |
| x | x | 95.99 | ||
| x | x | x | 98.21 |
Okazuje się, że pozostałymi kombinacjami nie udało mi się doścignąć wyniku osiąganego przez dropout, preprocessing i augmentację wraz z wyrównaniem liczności klas. Tym samym 98.21% to najwyższe accuracy uzyskane z wykorzystaniem omawianej sieci CNN.
Podsumowanie
Podsumowując, wykorzystując prostą sieć konwolucyjną udało nam się sprawdzić, że za pomocą przedstawionych metod jesteśmy w stanie poprawić wyniki osiągane na zbiorze testowym. W przeciwieństwie do modelu MLP, wszystkie z nich wpłynęły pozytywnie na accuracy. Czyli możemy stwierdzić, że problemem w pierwszej części serii nie były złe metody, ale sama sieć (uff…).
Najbardziej spektakularny wpływ na maksymalną testową dokładność miało zastosowanie dropoutu. Na podium załapały się także augmentacja (wyrównanie liczności klas) oraz wykorzystanie warstw tf.keras.layers.experimental.preprocessing (zoomu i rotacji). Wagi nie przyniosły oczekiwanego efektu. Najlepszy wynik (>98%) dało zastosowanie wszystkich 3 metod jednocześnie. Przy okazji warto się zastanowić co takiego dają nam warstwy preprocessing, czego nie daje nam rozszerzenie zbioru z wykorzystaniem albumentations. Przecież w obu tych przypadkach mamy skalowanie i obrót obrazów (no i kilka dodatkowych rzeczy w przypadku augmentacji z wykorzystaniem albumentations). Dzięki temu, że przekształcenia zawarte są w modelu (preprocessing), w każdej epoce podajemy nieco inne zdjęcie na wejście sieci – nie ograniczają nas dzięki temu zdjęcia, które wcześniej przygotowaliśmy.
Accuracy na poziomie 98% to na prawdę imponujący wynik, szczególnie dla prostej sieci trenowanej od zera. Jedną z przyczyn może być prostota zbioru. Zaraz, zaraz… A co znaczy model trenowany od zera? To da się inaczej? W kolejnej części pokażę Ci jak wykorzystać do tego zadania transfer learning, który polega na wykorzystaniu wag z wytrenowanego na innym zbiorze modelu.
Linki
- BelgiumTS dataset – https://btsd.ethz.ch/shareddata
- Artykuł: https://btsd.ethz.ch/shareddata/publications/Timofte-MVA-2011-preprint.pdf
Dodaj komentarz