

BelgiumTS Dataset – analiza zbioru i rozpoznawanie znaków drogowych
W tym wpisie postaram się przybliżyć Ci zagadnienie rozpoznawania znaków drogowych. Posłużymy się zbiorem danych z 2011 roku – BelgiumTS Dataset (czyli Belgium Traffic Sign Dataset). Myślę, że to dobry przykład na początek przygody ze znakami drogowymi, ponieważ posiada on niewielką liczbę klas – przez co nie zakopiemy się w ogromie kategorii, tylko będziemy mogli skupić się na zadaniu. Dodatkowo, oprócz zbioru do wykrywania obiektów (detekcji), autorzy przygotowali także dane do klasyfikacji – wydzielony zbiór wyciętych znaków BelgiumTSC – BelgiumTS Classification, dzięki czemu mamy możliwość oswoić się z tematem przy okazji nieco prostszego zagadnienia.
Poniżej krótkie podsumowanie dotyczące BelgiumTS Dataset.
- Link: https://btsd.ethz.ch/shareddata
- Rok: 2011
- Zadanie: detekcja, klasyfikacja
- Lokalizacja: Belgia
- Liczba klas: 210 (detekcja), 62 (klasyfikacja)
- Liczba zdjęć: 9006 (detekcja), 7095 (klasyfikacja)
- Wielkość zdjęć: 1628×1236 (detekcja)
- Artykuł: https://btsd.ethz.ch/shareddata/publications/Timofte-MVA-2011-preprint.pdf
Zdjęcia znaków drogowych
Zastanówmy się, co takiego szczególnego jest w znakach drogowych, co odróżnia je od innych obiektów w zadaniach widzenia maszynowego. Przede wszystkim, charakteryzuje je wysoki współczynnik odbicia światła, co przy pewnych warunkach atmosferycznych może sprawić, że zdjęcia będą prześwietlone, a sam znak trudny do rozpoznania. To dotyczy zarówno klasyfikacji jak i detekcji. Jest jeszcze jeden problem, który występuje jedynie w wykrywaniu obiektów – znaki mogą zajmować bardzo małą powierznię zdjęcia, a to znacznie utrudnia zadanie.
BelgiumTSC
Zgodnie z obietnicą, zaczniemy od zbioru do klasyfikacji – dokładniej są to wycięte i pogrupowane w kategorie znaki z BelgiumTS Dataset. Dostajemy w nim 4575 zdjęć w danych treningowych oraz 2520 zdjęć w danych testowych. Poniżej zebrałam po jednym przykładzie znaku dla każdej z 62 dostępnych klas.

Jeśli dokładnie przyjrzysz się powyższemu zestawieniu, zauważysz, że jest pewien problem – w klasie piatej i szóstej (numeracja od 0, klasy idą wierszami) widzimy jednakowe znaki. Jeśli pobierzesz dane, do których linki podałam wyżej i wejdziesz w katalog Training/00006, zobaczysz, że trzy zdjęcia zostały tu błędnie umieszczone – powinny znaleźć się w folderze 00005. Nie chcemy, aby nasza sieć uczyła się na błędnych danych, mamy zatem 2 wyjścia: przeniesienie danych do prawidłowego katalogu, albo ich usunięcie. Jestem zdecydowanie za opcją pierwszą – nie chcemy przecież tracić danych. Ciekawe, czy takich niespodzianek czeka nas więcej?
Przejrzałam wszystkie foldery – w danych testowych znajdziemy jeszcze 3 zdjęcia obiektu 02048 w katalogu 00018 (powinny być w 00017) oraz 3 zdjęcia dość dziwnego obiektu w danych treningowych w katalogu 00039. Ciekawi Cię jak wyglada ów dziwny obiekt? Poniżej zamieściłam screena, na którym możesz go zobaczyć.

Wszystkie zdjęcia tego znaku po prostu usunęłam.
Analiza zbioru
Przejdźmy do analizy naszych danych. Jest kilka informacji oprócz liczebności każdego z podzbiorów (treningowego i testowego) i liczby klas, które mogą okazać się bardzo przydatne przed przystąpieniem do treningu. Pierwsza z nich, to liczba wystąpień każdej z kategorii (intuicja podpowiada, że im bardziej zrównoważony jest zbiór, tym lepiej dla naszego treningu). Drugą jest informacja o rozdzielczości zdjęć – pomoże nam to nieco przy doborze rozmiaru wejścia do modelu.
Z poniższego wykresu możemy wywnioskować, że klasy rozkładają się bardzo nierównomiernie.
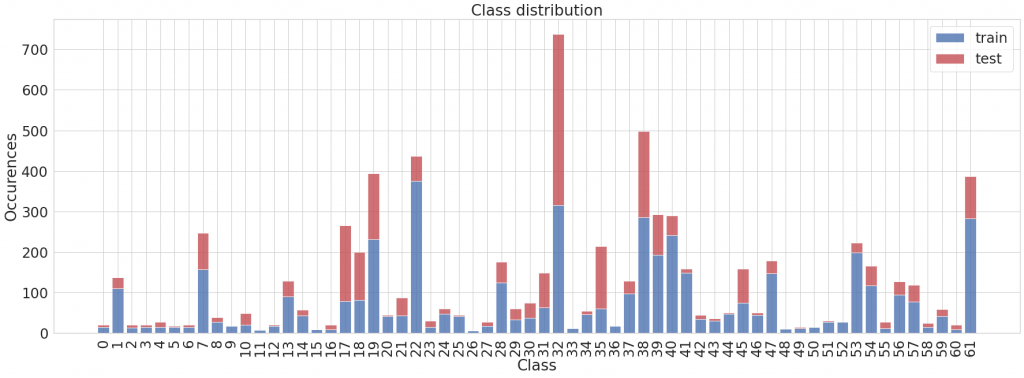
Jeśli dane w postaci niezmienionej podamy na wejście naszego modelu, zobaczy on niektóre kategorie znacznie rzadziej niż pozostałe, a to może mieć negatywny wpływ na jakość treningu. Poźniej pokażę Ci w jaki sposób można sobie z tym poradzić.
Zwróć uwagę, że niektóre klasy w ogóle nie występują w zbiorze testowym – to już jest bardziej problematyczne i trudniej będzie nam się z tym uporać. Poza tym, w danych testowych zdecydowanie dominuje jedna klasa, przy bardzo małej liczności pozostałych. Możemy miec przez to problem z miarodajną oceną modelu.
Rzućmy okiem na rozdzielczość zdjęć.
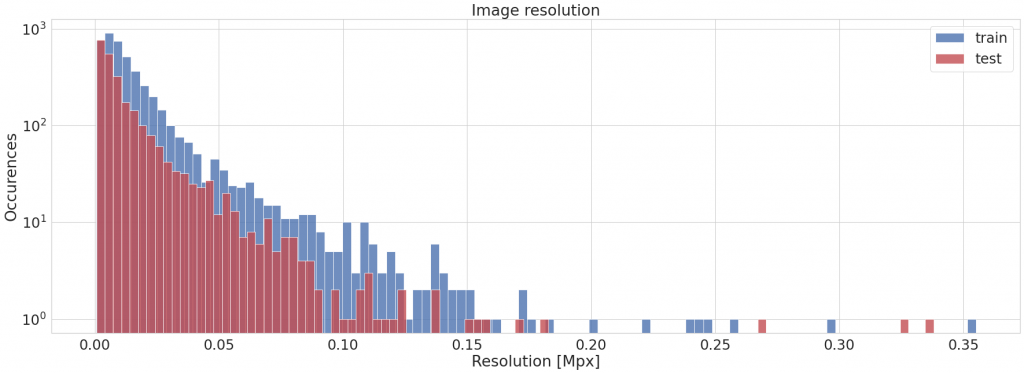
Na osi y znajduje się rozdzielczość, czyli powierzchnia zdjęcia. Możemy zatem wywnioskować, że większość obrazów jest mniejsza od 0.05 Mpx, co odpowiada mniej więcej kwadratowi 224×244 piksele. Nie dziwi nas mały rozmiar – pamiętamy, że nasze dane to znaki drogowe wycięte ze zbioru BelgiumTS Dataset.
Dodatkowo, sprawdziłam jeszcze jak wygląda rozdzielczość w poszczególnych kategoriach. Obliczyłam średnią rozdzielczość w każdej z klas dla danych treningowych i testowych.
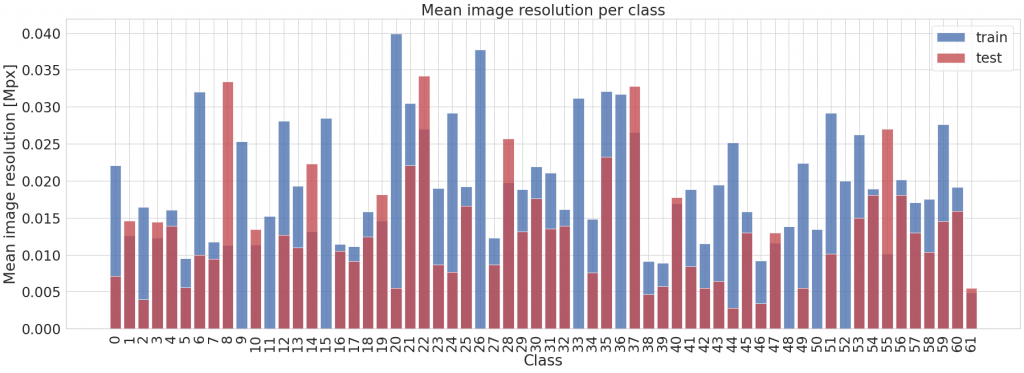
Możemy zaobserwować dosyć spore zróżnicowanie, jednak nie powinno mieć to wpływu na proces trenowania – informacje z powyższego wykresu traktujemy raczej jako ciekawostkę. Wejście sieci będzie miało ustalony rozmiar, więc powyższe różnice znikną.
Przygotowanie danych
Jeśli już nieco wiemy o naszych danych, możemy spróbować wytrenować model, który będzie klasyfikował znaki. W pierwszej kolejności sprawdzimy, jak z tym zadaniem poradzi sobie najprostszy typ sieci, czyli multilayer perceptron (MLP). Tutaj znajdziesz notebook w colabie, który możesz uruchomić i poeksperymentować z modelem.
Model będziemy trenować w TensorFlow. Wykorzystam nową funkcjonalność, która pojawiła się w tf 2.3.0 i zastąpiła ImageDataGenerator – image_dataset_from_directory. Jeśli chcesz poczytać więcej o nowościach wprowadzonych w wersji 2.3.0, zapraszam tutaj.
Pierwsza rzecz to instalacja wspomnianego TF 2.3.0.
! pip install tensorflow==2.3.0
Następnie importujemy niezbędne pakiety.
import os
import zipfile
import random
from glob import glob
import cv2
import numpy as np
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as plt
import tensorflow as tf
Poniższa sekcja przedstawia pobieranie i rozpakowywanie danych.
root_dir = 'BelgiumTSC'
if not os.path.exists(root_dir):
os.makedirs(root_dir)
!wget --no-check-certificate https://btsd.ethz.ch/shareddata/BelgiumTSC/BelgiumTSC_Training.zip
!wget --no-check-certificate https://btsd.ethz.ch/shareddata/BelgiumTSC/BelgiumTSC_Testing.zip
training_zip = 'BelgiumTSC_Training.zip'
zip_ref = zipfile.ZipFile(training_zip, 'r')
zip_ref.extractall(root_dir)
testing_zip = 'BelgiumTSC_Testing.zip'
zip_ref = zipfile.ZipFile(testing_zip, 'r')
zip_ref.extractall(root_dir)
zip_ref.close()
Uwaga! Przypominam o błędach, które wcześniej znalazłam. Przed przejściem dalej, musimy to wyczyścić. Warto byłoby edytować też pliki csv dla zachowania zgodności danych, ale nie będziemy z nich korzystać, więc nie jest to konieczne.
!find 'BelgiumTSC/Training/00039' -name '01247*' -delete
!find 'BelgiumTSC/Testing/00018' -name '02048*' -exec mv -t 'BelgiumTSC/Testing/00017' {} +
!find 'BelgiumTSC/Training/00006' -name '00147*' -exec mv -t 'BelgiumTSC/Training/00005' {} +
W jaki sposób wczytamy dane? Z pomocą przyjdzie nam wspomniana wcześniej metoda image_dataset_from_directory – możemy ją wykorzystać z uwagi na sposób organizacji zdjęć w katalogach. Obrazy podzielone są na kategorie – wszystkie pliki należące do tej samej klasy znajdują się w jednym folderze, którego nazwa jest jednocześnie nazwą klasy. W takich przypadkach stosowanie image_dataset_from_directory jest bardzo wygodne – z pewnością jeszcze nieraz się z tym spotkasz, więc warto zapamiętać.
Niestety, w przeciwieństwie do ImageDataGenerator, image_dataset_from_directory nie obsługuje zdjęć w formacie ppm, a taki właśnie jest format danych z BelgiumTSC. Musimy wykonać dodatkowy krok – przekonwertować oba zbiory (treningowy i testowy) do plików jpg (albo innych, które są wspierane – ja zdecydowałam się na jpg).
Wykorzystamy do tego morgify z ImageMagick – poniższe linie kodu pobierają go i instalują.
! sudo apt update
! sudo apt-get install build-essential
! wget https://www.imagemagick.org/download/ImageMagick.tar.gz
! tar xvzf ImageMagick.tar.gz
%cd ImageMagick-7.0.10-28
! sh configure
! make
! sudo make install
! sudo ldconfig /usr/local/lib
! magick -version
%cd ..
Po instalacji wykonujemy konwersję i usuwamy niepotrzebne już pliki.
%cd BelgiumTSC
! find . -name '*.ppm' -exec mogrify -format jpg {} +
! find . -name '*.ppm' -delete
%cd ..
Na tym etapie zdefiniujemy stałe: katalogi z danymi treningowymi i testowymi, dolecowy rozmiar zdjęć, liczbę epok oraz learning_rate.
TRAINING_DATA_DIR = 'BelgiumTSC/Training'
TESTING_DATA_DIR = 'BelgiumTSC/Testing'
TARGET_SIZE = 100
BASE_EPOCHS = 200
BASE_LR = 0.01
image_dataset_from_directory
Teraz przyszła kolej na image_dataset_from_directory – metoda ta zwraca obiekt tf.data.Dataset. Tworzymy 2 takie obiekty – po jednym dla danych treningowych i testowych. Jakie argumenty podajemy na wejściu? Są to:
- katalog z danymi,
- informacja o etykietach – „inferred” oznacza, że zostaną one wyznaczone na podstawie struktury katalogów,
- label mode, który wskazuje w jakieś postaci mają być przechowywane etykiety – zdecydowałam się na „int”, żeby następnie wykorzystać sparse_categorical_crossentropy,
- batch_size informujący ile zdjęć ma być przetwarzanych na raz,
- rozmiar zdjęć,
- informację, czy dane mają być wymieszane,
- seed wykorzystywany przy losowym mieszaniu oraz transformacjach.
Tutaj dzieje się cała magia. Jako jedno z wejść podajemy katalog nadrzędny ze zdjęciami – dzięki temu, w każdym kroku treningu otrzymamy zdjęcia wraz z poprawnymi etykietami (na podstawie nazwy katalogu). Wygodne, prawda?
training_ds = tf.keras.preprocessing.image_dataset_from_directory(
TRAINING_DATA_DIR,
labels="inferred",
label_mode="int",
batch_size=8,
image_size = (TARGET_SIZE, TARGET_SIZE),
shuffle=True,
seed=123)
testing_ds = tf.keras.preprocessing.image_dataset_from_directory(
TESTING_DATA_DIR,
labels="inferred",
label_mode="int",
batch_size=8,
image_size = (TARGET_SIZE, TARGET_SIZE),
shuffle=False)
Liczbę klas, która przyda się później wyznaczamy jak poniżej.
NUM_CLASSES = len(training_ds.class_names)
Poniższy kod przedstawia utworzenie datasetu, który zoptymalizuje nam operacje na plikach. Podczas pierwszej epoki treningu, wczytane obrazy zostaną zapisane w pamięci podręcznej (cache), dzieki czemu odczyt zdjęć nie stanie się wąskim gardłem naszego procesu.
AUTOTUNE = tf.data.experimental.AUTOTUNE
training_prefetcher = training_ds.cache().prefetch(buffer_size=AUTOTUNE)
testing_prefetcher = testing_ds.cache().prefetch(buffer_size=AUTOTUNE)
MLP – podejście pierwsze
Wreszcie możemy przejść do modelu, który w tym przypadku będzie niezwykle prosty. Składa się on z warstwy Flatten() i warstwy Dense() z 512 neuronami i funkcją aktywacji ReLU. W warstwie wyjściowej liczba neuronów musi odpowiadać liczbie klas. Z uwagi na fakt, że mamy do czynienia z multiclass classification, funkcją aktywacji jest softmax.
Pierwsze 2 warstwy wykonują preprocessing – zmieniają rozmiar zdjęcia i skalują wartości pikseli do zakresu od 0 do 1. Dlaczego dwukrotnie definiuję rozmiar zdjęcia? Podałam go już przecież tworząc training_ds i testing_ds. Dzięki umieszczeniu tego w modelu, będziemy mogli później wykonać inferencję na wczytanym bez wykorzystania image_dataset_from_directory zdjęciu, bez przejmowania się jego rozmiarem. Nie będziemy musieli nawet go pamiętać, model wykona resize za nas.
model = tf.keras.models.Sequential([
tf.keras.layers.experimental.preprocessing.Resizing(TARGET_SIZE, TARGET_SIZE),
tf.keras.layers.experimental.preprocessing.Rescaling(1./255),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dense(NUM_CLASSES, activation='softmax')
])
Następnie kompilujemy nasz model – na tym etapie podajemy optymalizator, funkcję kosztu oraz metryki. Miało być najprościej jak się da, więc zdecydowałam się na SGD (Stochastic Gradient Descent) ze zdefiniowaną wcześniej wartością learning_rate, której wartość pokrywa się z wartością domyślną. Jako loss wybieramy sparse_categorical_crossentropy, a z uwagi na klasyfikację, metryką będzie accuracy.
model.compile(optimizer=tf.keras.optimizers.SGD(learning_rate = BASE_LR), loss='sparse_categorical_crossentropy', metrics=['accuracy'])
Czas na trening! W model.fit() podajemy przygotowane wcześniej training_prefetcher i testing_prefetcher oraz liczbę epok.
history = model.fit(
training_prefetcher,
epochs = BASE_EPOCHS,
verbose = 1,
validation_data = testing_prefetcher
)
Spójrzmy na wykres lossu i accuracy. Czy powinniśmy wprowadzić jakieś zmiany w hiperparametrach?
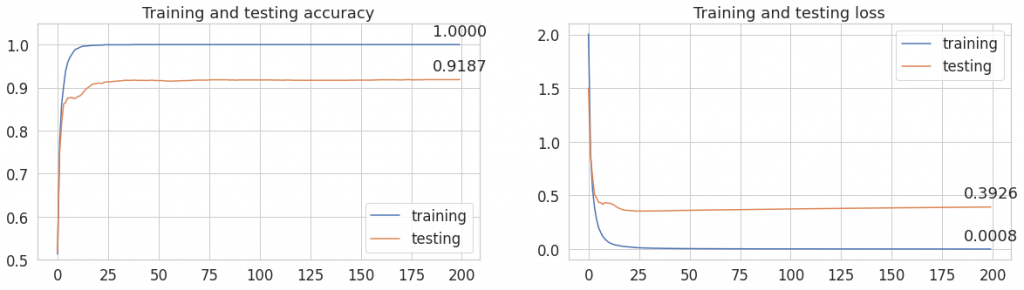
Wygląda na to, że wszystko jest w porządku. Nie obserwujemy nagłego spadku dokładności dla danych testowych. Gdyby tak się działo, mielibyśmy problem z overfittingiem. Jeśli spotykasz się z tym pojęciem pierwszy raz, zachęcam Cię do poszukania informacji na jego temat. W skrócie, overfitting ma miejsce wtedy, gdy wagi modelu zbyt dopasują się do danych, na których model był uczony i traci on zdolność do uogólniania. Czyli wyniki na danych treningowych są super, a na teście model wypada słabo. U nas tak się nie dzieje, więc nie mamy powodów do zmartwień.
Fakt, że overfitting nie wystąpił jest jednak dość zastanawiający, ponieważ trenowaliśmy aż przez 200 epok, co przy niedużym zbiorze danych jest sporą wartością. Może być to spowodowane dużym podobieństwem danych w zbiorze treningowym i testowym.
Kolejne eksperymenty wykonamy z takimi samymi wartościami hiperparametrów.
Jak poprawić wyniki?
W ostatniej epoce, udało mi się osiągnąć val_accuracy na poziomie 0.92 – całkiem nieźle jak na tak prosty model. Ale czy możemy zrobić coś, żeby ten wynik poprawić? Zanim przejdę to bardziej skomplikowaych modeli, chciałabym pokazać Ci typowe sposoby wykorzystywane do poprawy wyników dawanych przez sieć. Czy sprawdzą się i tutaj? Zobaczymy!
Chciałabym teraz zaadresować problem nierównomiernego rozkładu danych w zbiorze treningowym. W jaki sposób sobie z tym poradzić? Możemy do tego podejść na 2 sposoby:
- Wykorzystać wagi klas w funkcji kosztu aka loss_function.
- Zastosować augmentację danych, czyli dogenerować zdjęcia w klasach, w których jest ich mniej. Dogenerowanie polega wówczas na przetworzeniu w pewien sposób istniejących już obrazów.
Druga z metod (augmentacja), standardowo służy do poprawy zdolności uogólniania modelu. Jeśli jednak dogenerujemy zdjęcia na dysk, z powodzeniem możemy ją także wykorzystać do próby poradzenia sobie z nierównomierną dystrybucją klas.
MLP – podejście drugie, wagi klas
Zacznijmy od tego, co w ogóle wagi robią i w jaki sposób się je wyznacza.
Wagi wyznaczamy przed treningiem i są one bezpośrednio związane z liczebnością. Pamiętasz wykres liczności klas? Niektóre z nich są bardzo mało liczne. Kiedy nasz model natrafi na zdjęcie z jednej z takich klas, będzie miało ono większy wpływ na wartość funkcji kosztu, niż zdjęcie z bardzo licznej kategorii. Im więcej plików z danej klasy, tym mniejsza waga i odwrotnie – im mniej plików, tym wyższa waga.
Do tego zadania, z pomocą przyjdzie nam sklearn, a dokładniej funkcja compute_class_weight. Zwraca ona listę wag, z której tworzymy później słownik. Dlaczego słownik? Ponieważ tego wymaga od nas tensorflow w metodzie fit().
from sklearn.utils.class_weight import compute_class_weight
def get_gts(dataset):
gts = []
for images, labels in dataset.unbatch():
gts.append(labels.numpy())
return [int(x) for x in gts]
labels = get_gts(training_ds)
class_weight_vect = compute_class_weight('balanced', np.unique(labels), labels)
class_weight_dict = {cls:weight for cls, weight in enumerate(class_weight_vect)}
Najpierw musimy uzyskać listę etykiet ze zbioru treningowego, robimy to wykorzystując get_gts(dataset).
Na wejście compute_class_weight podajemy listę klas oraz etykiety ground-truth. balanced oznacza, że wagi zostaną wyznaczone zgodnie ze wzorem n_samples / (n_classes * np.bincount(y)).
Model pozostawiłam bez zmian. Jedyna różnica jest widoczna w model_weights.fit() – dochodzi dodatkowy parametr, którym są wagi klas.
model_weights = tf.keras.models.Sequential([
tf.keras.layers.experimental.preprocessing.Resizing(TARGET_SIZE, TARGET_SIZE),
tf.keras.layers.experimental.preprocessing.Rescaling(1./255),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dense(NUM_CLASSES, activation='softmax')
])
model_weights.compile(optimizer=tf.keras.optimizers.SGD(learning_rate=BASE_LR), loss='sparse_categorical_crossentropy', metrics=['accuracy'])
history_weights = model_weights.fit(
training_prefetcher,
epochs = BASE_EPOCHS,
verbose = 1,
validation_data = testing_prefetcher,
class_weight = class_weight_dict
)
Do jakich wniosków możemy dojść po wytrenowaniu modelu?
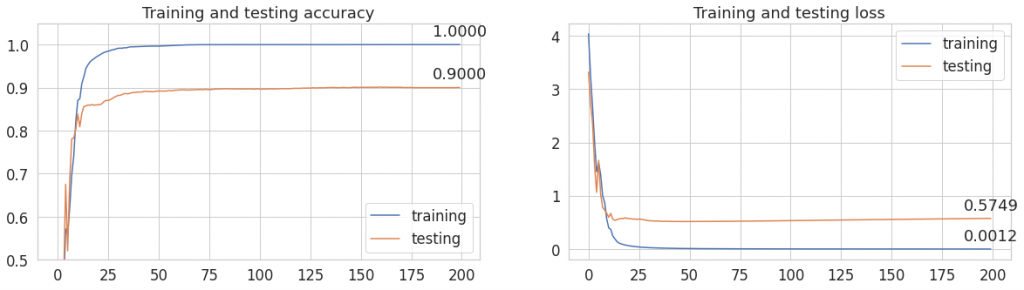
Wagi nie zmieniły wyników na zbiorze treningowym, ale pogorszyły nieco testowe accuracy.
MLP – podejście trzecie, augmentacja z wykorzystaniem preprocessing layers
Augmentację możemy wykonać na kilka sposobów. Wspomniałam wcześniej, że może ona służyć poprawie zdolności uogólniania modelu. Ale co to właściwie znaczy? W każdym kroku, w pewien sposób zmieniamy nasze zdjęcia – mogą to być obroty, rotacje, odbicia, rozmycia, zamiana kolejności kanałów w przestrzeni barw… Możliwości jest mnóstwo. Wówczas w każdej epoce treningu, sieć widzi nieco inny obraz – utrudniamy wtedy overfitting. Rozszerzamy też sztucznie zbiór danych (zdjęć źródłowych jest tyle samo, ale sieć dostaje je za każdym razem w innej postaci), więc w efekcie powinniśmy zaobserwować poprawę wyników na zbiorze testowym.
Zastanówmy się, jakie przekształcenia możemy wykorzystać. Kolor jest jedną z cech definiującą znak drogowy – mając to na uwadze, nie powinniśmy drastycznie zmieniać barw (odpada na przykład zamiana kolejności kanałów RGB). Możemy natomiast pobawić się nieco jasnością. Nie użyjemy także na pewno horizontal_flip, ani vertical_flip, ponieważ orientacja znaku względem drogi jest też jego cechą charakterystyczną, odbijając obiekt wzdłuż osi y, możemy uzyskać zupełnie inną klasę (pomyśl o znaku reprezentującym łuk). W grę wchodzi jednak niewielka rotacja.
Z racji tego, że chcę pokazać Ci wykorzystanie nowych warstw z tf.keras.layers.experimental.preprocessing, wybór mamy jeszcze bardziej ograniczony. Zdecydowałam się na dwa przekształcenia RandomZoom() i RandomRotation(). Oba bardzo delikatne. Pozostałe elementy modelu pozostają bez zmian, nie ruszam też hiperparametrów.
model_preprocessing = tf.keras.models.Sequential([
tf.keras.layers.experimental.preprocessing.Resizing(TARGET_SIZE, TARGET_SIZE),
tf.keras.layers.experimental.preprocessing.RandomRotation(0.1),
tf.keras.layers.experimental.preprocessing.RandomZoom(0.1),
tf.keras.layers.experimental.preprocessing.Rescaling(1./255),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dense(NUM_CLASSES, activation='softmax')
])
model_preprocessing.compile(optimizer=tf.keras.optimizers.SGD(learning_rate=BASE_LR), loss='sparse_categorical_crossentropy', metrics=['accuracy'])
history_preprocessing = model_preprocessing.fit(
training_prefetcher,
epochs = BASE_EPOCHS,
verbose = 1,
validation_data = testing_prefetcher
)
Jak to wpłynęło na wyniki?
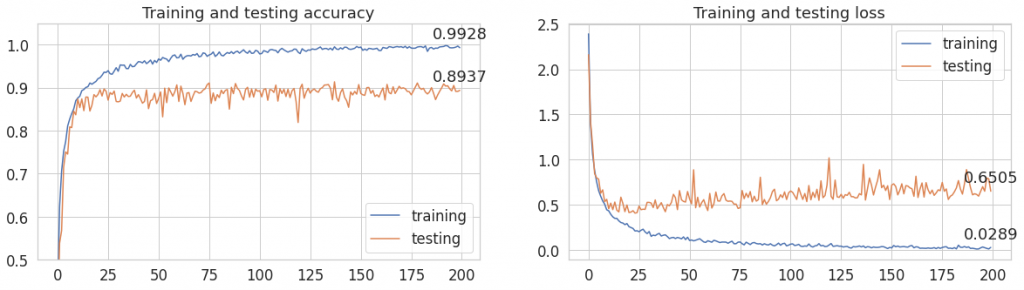
Możemy zaobserwować, że wystąpiły wahania wartości lossu i accuracy – szczególnie na danych testowych. Wyniki nie poprawiły się w porównaniu do poprzednich. Dlaczego? Może przychodzą Ci do głowy jakieś pomysły. Zanim jednak przejdziemy do wyciągania wniosków i podsumowania, rzućmy okiem na nieco inne zastosowanie augmentacji.
MLP – podejście 4, wyrównanie klas z wykorzystaniem albumentations
Teraz wykorzystamy augmentację do wyrównania liczności klas – dogenerujemy przekształcone zdjęcia tak, aby zdjęć we wszystkich kategoriach było po równo. Wykorzystam do tego celu bibliotekę albumentations. Dzięki niej będziemy mogli wypróbować różne możliwości i w łatwy sposób je wyświetlić.
Zacznijmy od przygotowania fukcji, które pomogą nam w uzyskaniu listy plików i liczby wystąpień każdej z klas.
def rootdir2list(directory, ext = 'jpg'):
paths_list = []
for dirpath, dirnames, filenames in os.walk(directory):
for filename in [f for f in filenames if f.endswith('.%s' % ext)]:
paths_list.append(os.path.join(dirpath, filename))
return paths_list
def get_occurences(paths_list, num_classes):
class_occurences = {k: 0 for k in range(num_classes)}
for path in paths_list:
norm_path = os.path.normpath(path)
path_class = int(norm_path.split(os.sep)[-2])
class_occurences[path_class] += 1
return class_occurences
Następnie z ich pomocą wyznaczamy kolejno: listę ścieżek do plików ze zbioru treningowego, słownik przechowujący nazwy klas i ich liczności, maksymalną liczbę wystąpień oraz słownik, który jako wartość ma liczbę zdjęć do wygenerowania w danej kategorii.
training_paths = rootdir2list(TRAINING_DATA_DIR)
class_occurences = get_occurences(training_paths, NUM_CLASSES)
max_occurences = int(max(class_occurences.values()))
to_generate = {k:(max_occurences-v) for k,v in class_occurences.items()}
Teraz, kiedy mamy już przygotowane niezbędne rzeczy, poeksperumentujmy z przekształceniami. Importujemy przekształcenia, które checmy wykorzystać oraz definiujemy transform jako złożenie tych przekształceń.
from albumentations import (
Compose,
RGBShift,
RandomBrightnessContrast,
RandomGamma,
Blur,
ShiftScaleRotate
)
transform = Compose([
RGBShift(p = 0.8, r_shift_limit=20, g_shift_limit=20, b_shift_limit=20),
RandomBrightnessContrast(p=1, brightness_limit=0.3, contrast_limit=0.15),
RandomGamma(p = 0.8, gamma_limit=(80, 180)),
Blur(p = 0.8, blur_limit=(5,10)),
ShiftScaleRotate(rotate_limit=30)
])
Następnie wizualizuję wyniki dla 100 zdjęć. Poniżej przedstawiam, jak to zrobić.
random.shuffle(training_paths)
sns.set(style = 'white', font_scale = 2)
plt.figure(figsize=(10, 10))
plt.tight_layout()
for idx, x in enumerate(training_paths[:100]):
image = cv2.imread(x)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image = cv2.resize(image, (TARGET_SIZE,TARGET_SIZE))
output_image = transform(image = image)['image']
plt.subplot(10, 10, idx+1)
plt.xticks([], [])
plt.yticks([], [])
plt.subplots_adjust(wspace=0, hspace=0)
plt.imshow(output_image)
Poniżej możesz zobaczyć zdjęcia przed augmentacją (po lewej stronie) i po augmentacji (po stronie prawej). W każdym przypadku jest to losowe 100 obrazów ze zbioru treningowego.

Zachęcam Cię do poeksperymentowania z przekształceniami – dodaniem nowych, zmianą ich parametrów. Może uda Ci się znaleźć lepszą do tego zagadnienia kombinację.
Teraz mamy wszystko, czego potrzebujemy do dogenerowania danych. No, może prawie wszystko. Poniższe funkcje służą do zwrócenia słownika, który klasie przyporządkowuje listę ścieżek do zdjęć danej klasy.
def get_class_from_path(path):
return int(os.path.normpath(path).split(os.sep)[-2])
def get_class_path_dict(paths):
classes = list(set([get_class_from_path(p) for p in paths]))
class_path_dict = {k:[] for k in classes}
for path in paths:
path_cls = get_class_from_path(path)
class_path_dict[path_cls].append(path)
return class_path_dict
Poniższy kod dogenerowuje dane.
from tqdm import tqdm
class_path_dict = get_class_path_dict(training_paths)
for cls, aug_nb in tqdm(to_generate.items()):
fname = random.choice(class_path_dict[cls])
image = cv2.imread(fname)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
for x in range(aug_nb):
output_image = transform(image = image)['image']
if not os.path.isfile(('-%d-.' % x).join(fname.split('.'))):
cv2.imwrite(('-%d-.' % x).join(fname.split('.')), output_image[:,:,::-1])
else:
cv2.imwrite(('-%d-.' % x+1).join(fname.split('.')), output_image[:,:,::-1])
Zmieniły nam się dane źródłowe, musimy zatem w takim razie utworzyć nowe zbiory danych. Tak samo, jak wcześniej wykorzystamy możliwość zapisu danych do pamięci cache w trakcie treningu.
training_ds_aug = tf.keras.preprocessing.image_dataset_from_directory(
TRAINING_DATA_DIR,
labels="inferred",
label_mode="int",
batch_size=8,
image_size = (TARGET_SIZE, TARGET_SIZE),
shuffle=True,
seed=123)
testing_ds_aug = tf.keras.preprocessing.image_dataset_from_directory(
TESTING_DATA_DIR,
labels="inferred",
label_mode="int",
batch_size=8,
image_size = (TARGET_SIZE, TARGET_SIZE),
shuffle=False)
AUTOTUNE = tf.data.experimental.AUTOTUNE
training_prefetcher_aug = training_ds_aug.cache().prefetch(buffer_size=AUTOTUNE)
testing_prefetcher_aug = testing_ds_aug.cache().prefetch(buffer_size=AUTOTUNE)
Dalej też niezbyt wiele się zmienia – wykorzystujemy dokładnie taki sam model, co wcześniej.
model_aug = tf.keras.models.Sequential([
tf.keras.layers.experimental.preprocessing.Resizing(TARGET_SIZE, TARGET_SIZE),
tf.keras.layers.experimental.preprocessing.Rescaling(1./255),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dense(NUM_CLASSES, activation='softmax')
])
model_aug.compile(optimizer=tf.keras.optimizers.SGD(learning_rate=BASE_LR), loss='sparse_categorical_crossentropy', metrics=['accuracy'])
history_aug = model_aug.fit(
training_prefetcher_aug,
epochs = BASE_EPOCHS,
verbose = 1,
validation_data = testing_prefetcher_aug
)
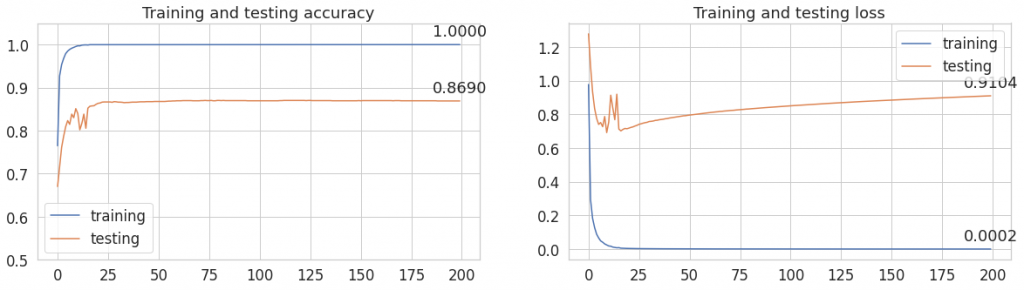
Widzimy, że accuracy na zbiorze testowym jest niższe niż poprzednio. Jak widać augmentacja i tym razem się nie sprawdziła. Widoczny jest też wzrost lossu, co może utwierdzić nas w przekonaniu, że występił overfitting.
MLP – podsumowanie
Na wspólnych wykresach przedstawiłam precyzję na zbiorze testowym i treningowym. Co możesz zaobserwować?
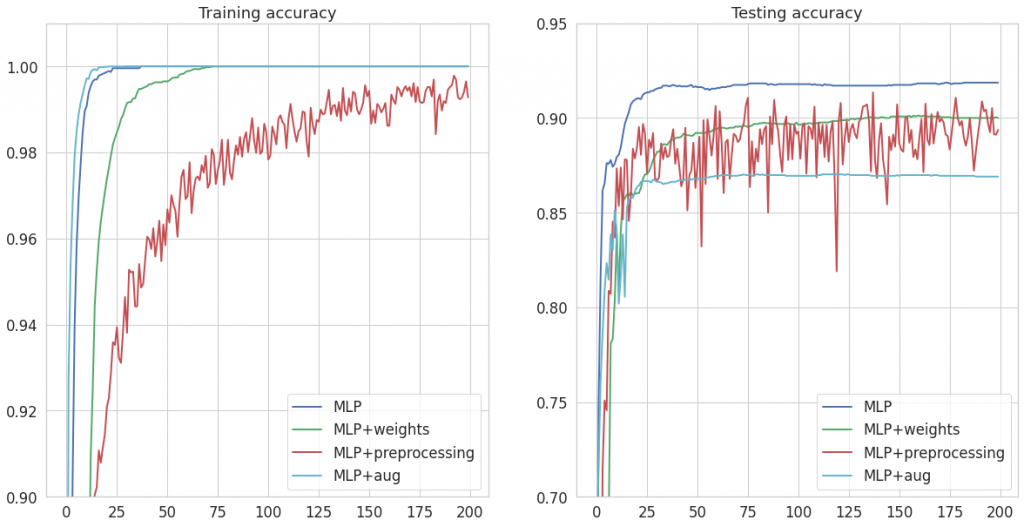
Zestawmy wnioski, jakie możemy wyciągnąć z powyższych wykresów:
- Zastosowanie wag klas przy obliczaniu funkcji nie poprawiło ogólnego accuracy na zbiorze testowym. Dlaczego tak się stało? Dodaliśmy wagi w procesie trenowania, ale nie są one uwzględniane w liczeniu metryk. Prawdopodobnie poprawiliśmy nieco działanie na mało licznych klasach, których udział w całkowitej dokładności jest niewielki. Jeśli osłabiliśmy tym samym zdolność rozróżniania bardziej licznych klas, tłumaczy to spadek wartości accuracy.
- Wykorzystując przekształcenia z tf.keras.layers.experimental.preprocessing usiągnęliśmy niższe accuracy, wystąpiły też dość duże wahania wartości metryk.
- Augmentacja z wykorzystaniem albumentations, rozszerzająca zbiór treningowy spowodowała osiągnięcie 100% accuracy na zbiorze treningowym przy jednoczesnym pogorszeniu wyników na teście. Jest to typowy przykład overfittingu – nasz model zbyt dopasował się do przekształconych zdjęć ze zbioru uczącego, co sprawiło, że gorzej radzi sobie z niewidzianymi wcześniej danymi. Dodatkowo, ważny może być tu fakt dużego podobieństwa między train a test – przeuczenie nie jest zauważalne na oryginlanych danych właśnie z uwagi na to podobieństwo.
Możemy więc śmiało stwierdzić, że żadne z 3 podejść nie pomogło nam w poprawie wyników.
Dlaczego augmentacja nie przyniosła pożądanych rezultatów? Nie pomogło zarówno zastosowanie tf.keras.layers.experimental.preprocessing, jaki i albumentations. Jej głównym zadaniem ma być bowiem poprawa zdolności uogólniania modelu, a jest to raczej domena sieci konwolucyjnych i jest to trudne, bądź niemożliwe do uzyskania z wykorzystaniem prostych sieci MLP.
Modele konwolucyjne w kolejnych warstwach, ekstrahują z obrazów coraz bardziej złożone cechy, więc o przynależności obiektu do danej kategorii decyduje zbiór jego cech, co samo w sobie podpowiada nam, że łatwiej tu o uogólnienia.
Sieci CNN (Convolutional Neural Network) pojawią się w kolejnym poście z serii dotyczącej znaków drogowych. Zobaczymy, czy uda nam się poprawić wyniki dzięki wykorzystaniu konwolucji.
Linki
- Notebook z omawianym kodem: https://colab.research.google.com/drive/1EGB0T_UWGkKPPAtM62E1lMIU0to6m6JW?usp=sharing
- BelgiumTS dataset: https://btsd.ethz.ch/shareddata
- Artykuł: https://btsd.ethz.ch/shareddata/publications/Timofte-MVA-2011-preprint.pdf
-
20 maja, 2021 o 1:39 pm
Niestety ale mam problem przy „image_from_directory”. Pomimo przekopiowania kodu otrzymuje błąd „Input 'filename’ of 'ReadFile’ Op has type float32 that does not match expected type of string.”
-
20 maja, 2021 o 3:12 pm
Patrzyłeś może na link do Colaba z całym kodem?
Dodaj komentarz