W dzisiejszych czasach wiele słyszy się o deep fakach, czyli m.in o filmach/obrazach, przedstawiających pewną postać — która jak się okazuje nią nie jest. Najczęściej algorytmy, potrafiące wygenerować taki film/obraz wykorzystują metody głębokiego nauczania. Zanim jednak „wpakujemy” do świata sieci, można zastanowić się jakie metody klasycznego przetwarzania obrazu mogły by pomóc uzyskać podobny efekt. W tym tutorialu zajmiemy się zamianą twarzy pomiędzy dwoma osobami.
Dowiemy się o metodach opartych na paletach barw koloru obrazu, triangulacji, przekształceniach afinicznych, punkach znaczących (konkretnie twarzy), a także o transformacjach morfologicznych.
Dane wykorzystane w tym wpisie dostępne są pod linkiem lapa-dataset [1]. Ten zbiór danych został wybrany dlatego, że.. nie jest on idealny do tego zadania 🙂
Ktoś by mógł się zapytać, czemu więc wybierać taki zestaw danych do zaprezentowania jakiegoś tutorialu? A no właśnie dlatego, że świat danologów nie jest zawsze prosty. Napisanie modeli predykcyjnych to najczęściej najprostszy element całego analitycznego pipelinu (czyli schematu rozwiązywania jakiegoś zadania). Ten tutorial pokaże Wam cały proces. Zaprezentowany został więc sposób myślenia, ewaluacji i dostrzegania problemów w czasie analizy, które najczęściej płyną właśnie z nieidealnego zbioru danych. Większości znane jest pewnie powiedzenie „Garbage In, Garbage Out”. A jeśli nie jest one znane Tobie drogi czytelniku proszę zapoznaj się z nim jak najszybciej! W wielkim skrócie mówi ono o podejściu, w którym błędne przetwarzanie danych wejściowych, będzie dawało błędne rezultaty. Tylko, czy analityk powinien odrzucać projekty, w których dane są nie przygotowane? Wydaje mi się, że wtedy ciężko byłoby o pracę 🙂
Po tym wpisie mam nadzieję, że będziesz wiedział/a jak ważne jest rozumienie swoich danych. W sieci znajdują coraz więcej modeli oraz gotowych produktów, które mogły by być użyte do tego zadania. I dobrze, działają szybko i dają dobrą dokładność swoich wyników. Ale nie zapominajmy o klasykach! Piękne modele i algorytmy, w pełni zrozumiałe i do tego łatwe do aplikacji. To im dziś poświęcę ten tutorial.
Meet dataset! – czyli najpierw porozmawiajmy o zbiorze danych
Dane, na których będziemy pracować zawierają obrazy BGR przedstawiając twarze różnych osób o różnych atrybutach. W idealnym układzie będziemy mieć do czynienia z twarzą skierowaną frontalnie oraz jednolitym tłem (oczywiście takich przykładów jest bardzo mało). Wielkość obrazów nie jest jednolita, czyli są one różnej rozdzielczości. By w przyjemny i szybki sposób poznać dane, należy się z nimi „spotkać”. Zapraszam Was zatem do przetestowania notebooka: MeetDataset/meetDataset.ipynb.
Za pomocą prostej funkcji read_folder możemy wczytać obrazy znajdujące się w folderze ’../LaPa/examples’, by zaczytać etykiety oraz dodatkowe informacje jakimi są punkty znaczące należy podać odpowiednio nazwy pod folderów. Flaga „RGB” wyznacza nam, czy chcemy przetwarzać obrazy BGR czy RGB.
PATH = '../LaPa/examples'
images = read_folder(PATH,
labels = 'labels',
landmarks= 'landmarks', RGB = True)Piksele obrazów zostały zaklasyfikowane do odpowiednich kategorii. Wyznaczono także 106 punktów znaczących nazywanych landmarkami, które nie rzadko używane są m.in do rozpoznawania mimiki itp. Poniżej znajduje się przykład jednego zestawu danych:

Kategorie odnoszą się do głowy (w szczególności twarzy), wydzielono klasy takie jak: włosy, skóra twarzy, lewa/prawa brew, lewe/prawe oko, nos, górna/dolna warga, wewnętrzne ust, tło. Poniżej przykładowo zostały wydzielone trzy różne klasy, dla trzech różnych obrazów wsadowych:

Warto zauważyć, że numery punktów znaczących (zaznaczone na niebiesko), zawsze odpowiadają dokładnie tej samej części twarzy. Dzięki czemu w naturalny sposób możemy wyznaczyć miejsce znajdującego się nosa, czy brwi nie znając etykiet. Albo…. inaczej mówiąc, możemy wyznaczyć etykiety, o ile mamy informację o punktach znaczących. Łatwo jest też wyznaczyć symetrię twarzy.

Jeśli na danym obrazie znajduje się więcej niż jedna osoba, tylko wycentrowana osoba jest podana etykietowaniu. Nie ukrywam, że może to powodować wiele błędów. A nawet jeśli nie w procesie analizy, to na pewno w rzeczywistym środowisku systemy musiały by centrować twarz by była dalsza możliwość przetwarzania takiego obrazu (oczywiście wszystko zależy od indywidualnego przypadku).

Co my będziemy używać? Na pewno obrazów BGR do aplikacji algorytmów. Etykiet do ewaluacji. Punkty znaczące są naprawdę pomocne! Za pomocą ich obserwacji wyznaczymy podstawowe wnioski dotyczące położenia twarzy. Przede wszystkim pozwalają nam wyznaczyć trójkąty, które następnie posłużą do transformacji twarzy. Istnieje kilka algorytmów do ich obliczenia. Dlatego nie będziemy korzystać bezpośrednio z tych, które zostały podane we zbiorze danych. Sami je wyznaczymy. Jednak zanim to nastąpi, przypatrzmy się triangulacji twarzy.
Triangulacja twarzy
Kod wraz z dodatkowymi komentarzami znajdziecie w notebooku Triangulation/triangulation.ipynb.
Na początku tego tutorialu użyjemy punktów znaczących, które znajdują się w zbiorze danych.
Użyjemy wczytanych wcześniej danych do słownika images. By zaczytać obraz do przetwarzania możemy prosto znaleźć go pod wybranym kluczem example_img:
# wybierz obraz, który będziemy rozważać
example_img = '10256701615_2'# wczytaj obraz
img_RGB = images[example_img]['img']
# wczytaj punkty znaczące
landmarks = images[example_img]['landmarks']()Dla bardziej zainteresowanych polecam prześledzić co kryje się pod obiektem images[example_img][’landmarks’]. Szczegółowa implementacja znajduje się w folderze „src„.
type(images[example_img]['landmarks'])
# output: src.landmarks.Landmarks
Zmienna landmarks zawiera jednak już nie sam obiekt typu Landmarks, a wartości współrzędnych.
print(landmarks)
# output:
array([[240, 354],
[239, 378],
[239, 402],
.... ] )Triangulacja Delone (Delaunay)- pod tą nazwą, kryje się najbardziej rozpowszechniony algorytm do podziału danego obszaru (np. figury geometrycznej) na trójkąty.
Implementację algorytmu znajdziesz w bibliotece scipy, dlatego zastosowanie jej jest… banalnie proste 🙂
from scipy.spatial import Delaunay
triangles = Delaunay(landmarks)Wynikiem triangulacji jest m.in lista wskaźników punktowych trójkątów tworzących triangulację. Przykładowo, pierwsze 3 trójkąty możemy wyznaczyć za pomocą atrybutu simplices.
triangles.simplices[:3]
# output:
array([[41, 33, 34],
[90, 28, 27],
[22, 21, 91]], dtype=int32)W celu wizualizacji, możemy skorzystać z funkcji plt.triplot.
# wyznaczenie współrzędnych na osi x.
x = landmarks[:,0]
# wyznaczamy współrzędne na osi y. Ponieważ obcujemy z obrazami, do ładniejszej wizualizacji należy pomnożyć współrzędne razy (-1).
y = landmarks[:,1] * (-1)
# wizualizacja punktów znaczących
plt.plot(x, y, 'o')
# wizualizacja trzech pierwszych trójkątów
plt.triplot(x, y, triangles.simplices[:3], '--', color = 'black')

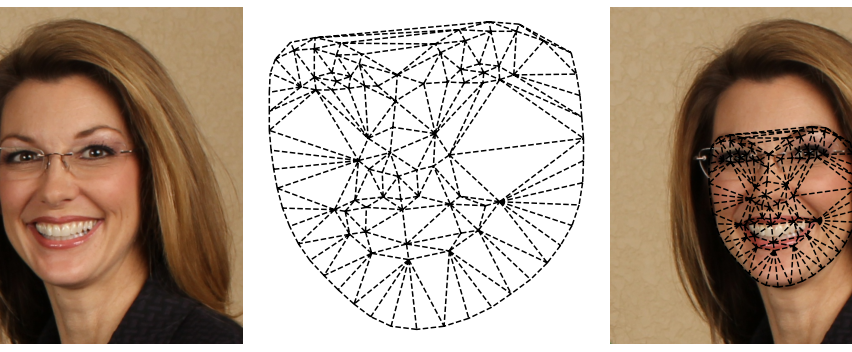
Obiekt (twarz) może więc być przedstawiona jako siatka trójkątów:
Warto zobaczyć, że wyznaczone trójkąty nie są symetryczne względem twarzy (widać to wyraźnie zwłaszcza kiedy przyjrzymy się policzkom):
Czy to nam przeszkadza? W gruncie rzeczy … nie. Ale mam takie przeczucie, że siatka wyznaczająca twarz powinna być symetryczna.
# znajdźmy symetrię twarzy, używając do tego obiektu Landmarks
symmetry = images[example_img]['landmarks'].symmetryObiekt symmetry to tak naprawdę słownik, który zawiera pary punktów znaczących na twarzy, np. lewy kącik lewego oka odpowiada prawemu kącikowi prawego oka.
print(symmetry)
# output: {0: 32,
32: 0,
1: 31,
31: 1,
.... }Ponieważ, będziemy odbijać wybraną połowę twarzy względem symetrii, musimy wybrać, która część twarzy będzie „wiodąca”. W moim przypadku będzie to lewa.
# określ, które punkty należą do lewej strony twarzy.
LEFT_FACE_SIDE = images[example_img]['landmarks'].points_info['LEFT_FACE_SIDE']print(LEFT_FACE_SIDE)
# output : [33, 34, 35 ... ]By móc określić, które trójkąty należą do lewej/prawej strony twarzy, możemy stworzyć funkcję pomocniczą, która będzie przyjmować wszystkie trójkąty i sprawdzać, czy trójkąt zawiera wybrany punkt/punkty.
def triangles_specific_points_sets(triangles: Delaunay,
include_point_set: np.array,
only_points_set: bool = True,
except_points_set: np.array = None)
-> np.array:
"""
find triangles which inlude points from include_point_set.
Parameters:
-------
triangles - scipy.spatial._qhull.Delaunay
Delaunay object with triangles Indices of the points
forming the simplices in the triangulation.
For 2-D, the points are oriented counterclockwise.
include_point_set - array
with points which have to be included
only_points_set - bool, default True
if True, output will inlclude traingle if all points
in triangle will be in include_point_set,
if False, output will inlclude triangle if any point
will be in include_point_set
except_points_set - array
with points which can not be included. Even if
traingle will have points from set include_point_set
Returns
-------
traingles_points: array
array with triangles Indices of the points forming
the simplices in the triangulation. Triangles inlude
"""
# select traingles considering include_point_set and
# only_points_set flag
traingles_in_points_set = []
for triangle in triangles.simplices:
if only_points_set:
len_triangle = len(triangle)
point_in_points_set = 0
for point in triangle:
if point in include_point_set:
point_in_points_set += 1
else:
break
if point_in_points_set == len_triangle:
traingles_in_points_set.append(triangle)
else:
for point in triangle:
if point in include_point_set:
traingles_in_points_set.append(triangle)
break
# check if any points in selected triangles not exist in
# except_points_set
if except_points_set is not None:
traingles_without_except_points_set = []
for triangle in traingles_in_points_set:
len_triangle = len(triangle)
point_in_points_set = 0
for j in triangle:
if j not in except_points_set:
point_in_points_set += 1
if point_in_points_set == len_triangle:
traingles_without_except_points_set .append(triangle)
return np.array(traingles_without_except_points_set )
return np.array(traingles_in_points_set)Z pomocą triangles_specific_points_sets wyznaczymy współrzędne trójkątów, które znajdują się po lewej stronie. Zatem będziemy klasyfikować trójkąty wyznaczone za pomocą algorytmu Delaunay triangles. Będziemy chcieli, by trójką zawierał punkty, tylko i wyłącznie (only_points_set = True) z listy punktów odnoszących się do lewej strony twarzy (include_point_set = LEFT_FACE_SIDE)
# wybierz trójkąty, powstałe na skutek triangulacji, które znajdują się po lewej stronie twarzy
left_face_side_traingles = triangles_specific_points_sets(triangles, include_point_set = LEFT_FACE_SIDE, only_points_set = True)print(left_face_side_traingles )
# output: array([[ 41, 33, 34],
[ 35, 41, 34], ... ] )
Następnie dzięki słownikowi symetrii możemy stworzyć odbicie lustrzane trójkątów:
def create_mirror_traingles(traingles: np.array , symmetry_dir: dict) -> np.array:
"""
find triangles mirrored to choosen ones.
Parameters:
-------
traingles: np.array
traingles array with landmarks which will be reflected
symmetry_dir: dict
dictonary with corresponding factial points
Returns
-------
mirror_traingles: np.array
array with traingles mirrored to traingles
"""
mirror_traingles = []
for triangle in traingles:
# create new mirrored triangle to triangle
new_triangle = []
for point in triangle:
# for each point in triangle find symmetrical point using symmetry_dir
new_triangle.append(symmetry_dir[point])
mirror_traingles.append(np.array(new_triangle))
return np.array(mirror_traingles)# znajdź punkty wyznaczające trójkąty, które są symetryczne do wybranych trójkątów -- znajdujących się w left_face_side_traingles
mirror_triangles_to_left_side_face = create_mirror_traingles(left_face_side_traingles, symmetry)print(mirror_triangles_to_left_side_face)
# output: array([[ 47, 46, 45],
[ 44, 47, 45], ... ])
Należy zauważyć, że nie jesteśmy w stanie wszystkich punktów wyznaczyć symetrycznie. Istnieją trójkąty, które stanowią połączenie pomiędzy lewą, a prawą stroną twarzy. Mieszczą się one m.in pomiędzy brwiami (zaznaczone na poniższym obrazku na czerwono). Dokładnie jak je wyznaczyć opisuję w notebooku, więc zajrzyj tam koniecznie lub/i spróbuj sam!

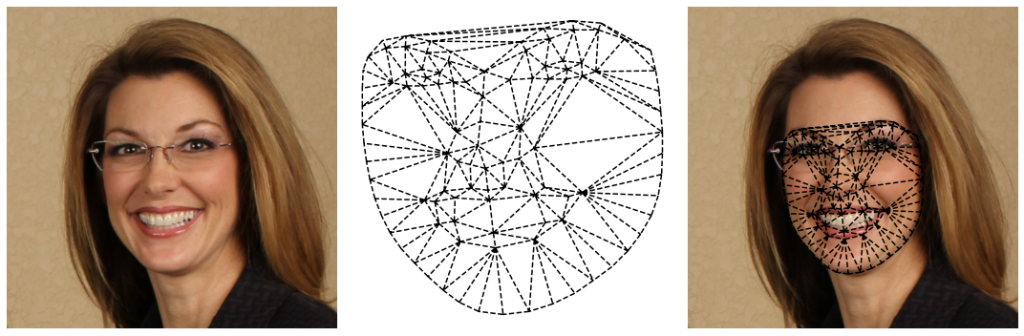
Ostatecznie możemy stworzyć siatkę, która symetrycznie wykreśla nam twarz kobiety:
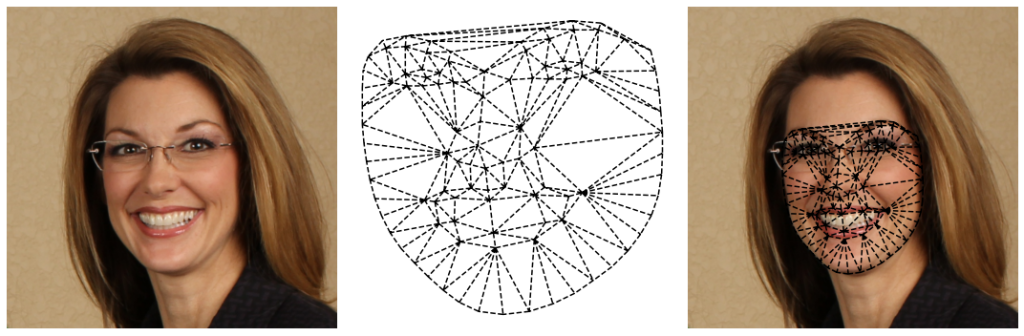
Zastosowanie algorytmu jest jednak lekko zdradliwe. Zadajmy sobie pytanie, co się stanie jak użyjemy innych współrzędnych landmarks? Warto zwrócić uwagę, że algorytm tworzy trójkąty dla siebie najbardziej optymalne. W rezultacie szybko odkryjemy, że punkty wyznaczające dany trójkąt różnią się. Poniżej znajduje się przykład, triangulacji, nie współgrający z wynikiem triangulacji na punktach znaczących u twarzy kobiety.
Należy mieć świadomość, że triangulacja dla różnych obrazów (figur wyznaczonych z pomocą punktów znaczących) będzie dawać różne rezultaty. Chcąc podmieniać dane przestrzenie (trójkąty) między dwoma osobami, nie możemy pozwolić, by trójkąty odpowiadały różnym obszarom twarzy. Dlatego będziemy najpierw wyznaczać siatkę (np. z pierwszego rozważanego obraz), a następnie aplikować ową siatkę do drugiego.
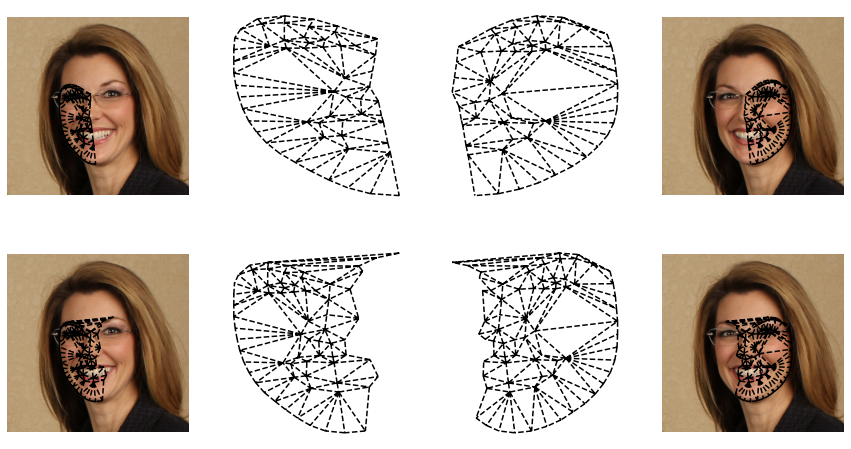
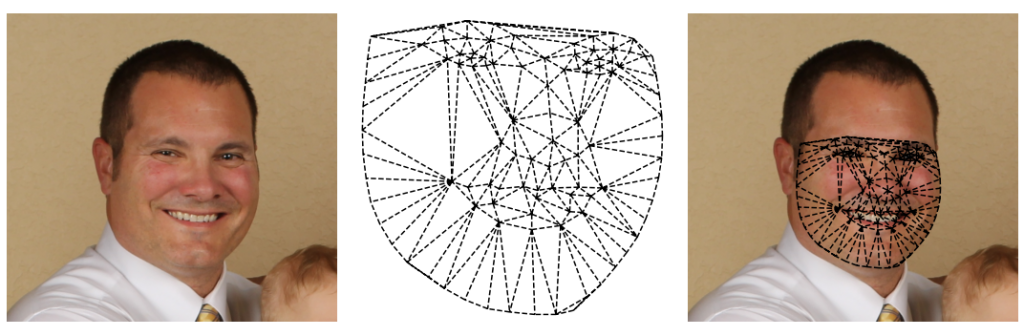
Czy możemy tak zrobić? A czemu nie? Poniżej przykład siatki, utworzonej z pomocą lewej strony twarzy mężczyzny:
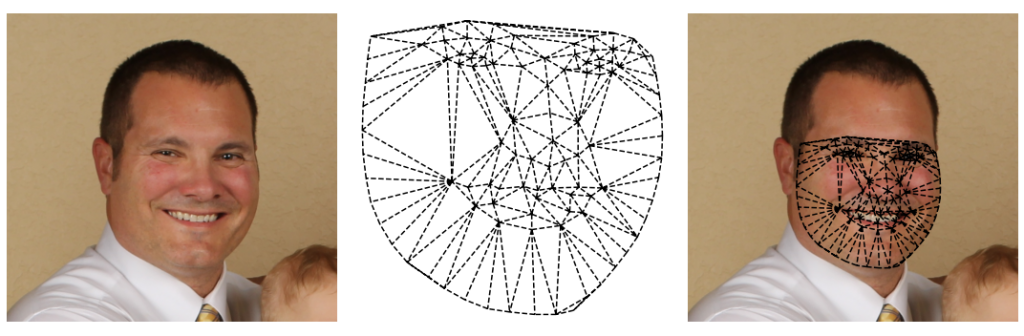
Oraz dla porównania zastosowanie siatki, utworzonej z pomocą punktów znaczących twarzy kobiety:
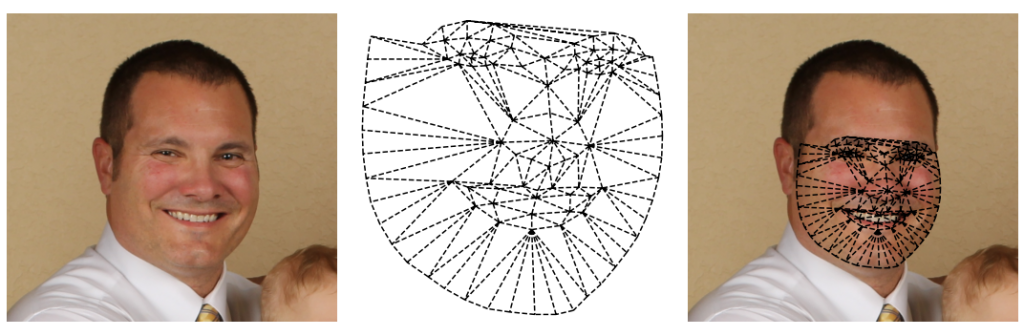
Czy można stwierdzić, która siatka spowoduje bardziej naturalny efekt transformacji twarzy? Czy może warto stosować jedną siatkę do wszystkich obrazów, które są rozważane == czy istnieje idealna siatka? Te pytania pozostawiam czytelnikowi 🙂
Punkty charakterystyczne twarzy – sposoby wykrywania
Jak byłam młodsza wielokrotnie w filmach wtedy Science Fiction widziałam sceny, gdy drzwi otwierają się po zeskanowaniu czyjeś twarzy. Było to dla mnie wtedy niezwykle ciekawe, co taki skaner może „zczytywać”. Zastanawiałam się jak można było by oszukać algorytm — np. czy jeśli osoba, który nosi wąsy następnego dnia by ich nie miała — to czy drzwi wpuściły by ją?
Teraz świat wygląda troszkę inaczej, a algorytmy wykrywające twarz towarzyszą nam każdego dnia na portalach społecznościowych. Ciekawe jest jednak to, że pomimo, że wiele telefonów wprowadziło możliwość odblokowania ekranu poprzez wykrycie twarzy właściciela — jest to mniej popularne niż odblokowywanie kodem, czy palcem. Pewnie pod tym kryje się wiele powodów, ale zawsze mi się przypomina historia jak telefon „nie poznaje” z rana właściciela. Jak to jest, że wchodząc w galerie telefonu nie rzadko pokazują nam się sugestie kto jest kim, a codzienne użytkowanie może być w dalszym czasie problematycznie?
Ta sekcja opowie o wykrywaniu punktów znaczących, czyli tych punktów, których użyliśmy do triangulacji. Jak je „zdobyć”, gdy nie mamy miłych anotatorów, którzy mieli by czas nam je wyznaczyć? Poniżej znajdują się przykładowe rozwiązania, a kod możecie znaleźć w notebooku FaceLandmarks/faceLandmarks.ipynb.
MediaPipe
MediaPipe to rozwiązanie, które proponuje nam przetrenowane modele, czyli taki, które możemy użyć od razu — lekko je dopasowując do naszego rozwiązania. Dzięki biblioteki możemy: wykrywać twarz, tworzyć siatkę twarzy, wykrywać punkty znaczące pozycji człowieka, a także wykrywać punkty znaczące ręki. Biblioteka oferuje nam detekcję, segmentację i obserwowanie pewnych obiektów.
Muszę przyznać, że działa naprawdę dobrze! Jest bardzo łatwa w użyciu. Wręcz idealna jeśli na szybko chcemy coś przetestować, pokazać prototyp.
Ponieważ jest rozwiązaniem stworzonym „na większą skalę” nie będzie działać idealnie do naszego zbioru danych, zawsze można jednak podrasować rozwiązanie, do czego gorąco zachęcam.
Do znalezienia punktów znaczących będziemy skupią przede wszystkim na MediaPipe Face Mesh (https://google.github.io/mediapipe/solutions/face_mesh#face-landmark-model)
Z całego serca rekomenduję poczytać o rozwiązanych na stronach https://github.com/google/mediapipe! zwłaszcza: https://github.com/google/mediapipe/blob/master/mediapipe/python/solutions/face_mesh.py
# na początku importujemy bibliotekę MediaPipe
import mediapipe as mpPonieważ zdecydowałam się używać gotowego modelu, należy z rozwiązań siatki (solution.face_mash) wybrać metodę „FaceMash()” tak aby stworzyć obiekt:
faceMeshModel = mp.solutions.face_mesh.FaceMesh()Wybieramy teraz przykładowy obrazek i zamieniamy go na RGB. Możemy oczywiście skorzystać z funkcji pomocniczych m.in read_folder. Czyli tak samo jak w MeetDataset/meetDataset.ipynb:
PATH = '../LaPa/examples'
images = read_folder(PATH,
n = 10,
landmarks= 'landmarks', RGB = True)Parametr „n” odpowiada za wczytanie 10 obrazków
Wybierzmy obraz `2312594442_3’ :
example_img = '2312594442_3'
img_RGB = images[example_img]['img']By uzyskać punkty znaczące na wybranym obrazie wystarczy jedynie wywołać metodę process:
results = faceMeshModel.process(img_RGB)
# output: mediapipe.python.solution_base.SolutionOutputs
I to wszystko? TAK! 😀 To było takie proste.
By móc podejrzeć punkty znaczące wystarczy jedynie odwołać się do parametru mlti_face_landmarks:
results.multi_face_landmarks
# output: [landmark {
x: 0.5272213816642761
y: 0.6497410535812378
z: -0.0339466817677021
} ... {...} ]Punkty znaczące przedstawione są nam w postaci listy obiektów landmark z trzema pozycjami x, y, z. Oznacza to, że z obrazka 2D MediaPipe dało nam możliwość stworzenia maski 3D!
Chcąc narysować taką maskę możemy użyć metody scatter3D z biblioteki matplotlib. Jest zapewne wiele sposób, by stworzyć listę koordynatów, poniżej przedstawiam najprostszą z nich, czyli „przelecenie” po wszystkich punktach pętlą for i stworzenie 3 list (odpowiadającym wektorom) położenia.
x = []
y = []
z = []
for landmark in results.multi_face_landmarks[0].landmark[:]:
x.append(landmark.x)
y.append(landmark.y)
z.append(landmark.z)Teraz możemy narysować maskę (oczywiście nie zapomnijcie o imporcie odpowiednich bibliotek! )
f, ax = plt.subplots(1,3, figsize= (15,5),
subplot_kw=dict(projection='3d'))
ax[0].scatter3D(x, y, z);
ax[0].view_init(180, 10)
ax[0].axis('off')
ax[1].scatter3D(x, y, z);
ax[1].view_init(180, 90)
ax[1].axis('off')
ax[2].scatter3D(x, y, z);
ax[2].view_init(90, 90)
ax[2].axis('off')
f.suptitle('3D Meshgrid from different views')
plt.show()
Pomimo, że maska 3D jest fajnym „bajerem” w naszym zadaniu się nie przyda Potrzebujemy wiedzieć jak punkty znaczące odnoszą się do obrazka 2D. Dlatego należy znormalizować punktu (zrzutować je na płaszczyznę). Oczywiście zachęcam do przypomnienia sobie materiału z optyki, zapewne z liceum — ale nie jest to teraz potrzebne. Ponieważ biblioteka serwuje nam gotowe funkcje: _normalized_to_pixel_coordinates w module odpowiadającym za wizualizację drawing_utils. Stwórzmy zatem funkcję find_landmarks, która będzie znajdywała punkty znaczące, a w rezultacie otrzymamy koordynaty punktów w postaci wektorów x, y:
def find_landmarks(img_RGB):
results = faceMeshModel.process(img_RGB)
x = []
y = []
image_rows, image_cols, _ = img_RGB.shape
for landmark in results.multi_face_landmarks[0].landmark[:]:
landmark_px = mp.solutions.drawing_utils.
_normalized_to_pixel_coordinates(
landmark.x, landmark.y,
image_cols, image_rows)
x.append(landmark_px[0])
y.append(landmark_px[1])
return x,yKiedy ją wywołamy:
x,y = find_landmarks(img_RGB)Możemy teraz koordynaty zamienić na obiekt Landmarks:
landmarks = Landmarks(np.array([x,y]).T)dzięki czemu: po pierwsze będziemy użyć obiektu, co samo w sobie powoduje czyściejszy kod, a po drugie możemy użyć przygotowanych funkcji pomocniczych do wizualizacji (dla bardziej dociekliwych kod znajduje się w src/visualization) i wyświetlania punktów znaczących:
plot_img(img_RGB)
plot_landmarks_color(landmarks)Oki, największy plus użycia tego rozwiązania już znacie: jest szybkie, tanie i łatwe.
Teraz o minusie 🙂 Po pierwsze dla tego tutorialu – nie jest klasyczną metodą. Opiera się na wytrenowanej sieci, co oczywiście nie jest minus w praktyce!
Minusem jednak dla projektu jest chociażby problem z detekcją kontur. Jeśli chwilę zastanowimy się co się stanie jeśli osoba na zdjęciu nie będzie stała frontowo — po pewnym czasie dojdziemy do konkluzji, że płaszczyzna na którą rzutowany jest obraz 3 koordynat nie jest na bezpośrednio na froncie przed osobą na zdjęciu. Oznacza to, że punkty rzutowania są na odbiorcę (czyli na nas). Oznacza to…, że kiedy wybierzemy inny przykład zdjęcia np: ’10004446093_1’. Kontury (niebieskie punkty na poniższym zdjęciu) utworzą coś ala półksiężyc. Jest to logiczne ponieważ wyznaczone punkty odpowiadają konturom twarzy frontowej (czyli żuchwie itd). Dla naszego projektu będzie to po prostu upierdliwe, ponieważ chcemy wykrywać kontur całej twarzy.
example_img = '10004446093_1'
img_RGB = images[example_img]['img']
x,y = find_landmarks(img_RGB)
landmarks = Landmarks(np.array([x,y]).T)
plot_landmarks_color(landmarks)
plot_img(img_RGB)
Rozwiązania, które nasuwają się same są dwa – można wyznaczyć inną płaszczyznę rzutowania. Jest to świetne rozwiązanie, które zajmuje troszkę więcej czasu niż ktokolwiek by chciał. Drugim rozwiązaniem jest… zmiana podejścia i poszukanie innego rozwiązania 😀 Ponieważ tutorial tutorial miał opierał się na klasycznych metodach opowiem Wam jeszcze o jeszcze o jednej bibliotece: Dlib. Choć zachęcam do przejrzenia innych rozwiań jak m.in „Menpo„.
Więcej na temat Mediapipe można znaleźć pod linkiem: Mediapipe face_mesh.
Dlib
Najlepszym toturialem jaki znalazłam dotyczącym biblioteki jest oczywiście dokumentacja, która w tym wypadku jest naprawdę dobrze sporządzona. Zachęcam zatem do sprawdzenia dwóch linków, gdzie znajdują się potrzebne plik, więcej opcji oraz po prostu szerzej wyjaśnione funkcje:http://dlib.net/files/, http://dlib.net/python/index.html. Zachęcam także do zerknięcia do repozytorium: https://github.com/davisking/dlib-models gdzie znajdują się m.in gotowe modele do pobrania z pełną informacją.
W tym tutorialu zdecydowałam się na model shape_predictor_68_face_landmarks.dat, ponieważ używa detektora HOG. Polecam poczytać na ten temat tutaj: https://towardsdatascience.com/hog-histogram-of-oriented-gradients-67ecd887675f. A dla ludzi ciekawych od czego zaczęła się popularność tego algorytmu zapraszam do przejrzenia artykułu Navneeta Dalala i Billa Triggsa „Histograms of Oriented
Gradients for Human Detection” http://lear.inrialpes.fr/people/triggs/pubs/Dalal-cvpr05.pdf.
Algorytm HOG do detekcji cech/punktów używa histogramu gradientów. Metoda ta opiera się zatem przede wszystkim na kontraście, ale także kształcie obiektu, ponieważ obliczenie są gradienty obrazu (globalnie i lokalnie, w zależności od parametryzacji). Jest wiele metod, które następnie klasyfikują kierunek gradientu do tak zwanych koszyków. Kilka metod zaprezentowanych jest w tutorialu: https://www.analyticsvidhya.com/blog/2019/09/feature-engineering-images-introduction-hog-feature-descriptor/.
Zaczynami jak zawsze od wczytania odpowiedniej biblioteki:
import dlibDo wykrywania twarzy (czyli wskazywania ramki) będziemy używać detektora HOG, zaimplementowany jako podstawowy detektor twarzy frontalnej:
DETECTOR = dlib.get_frontal_face_detector() Predykatorem 68 punktów będzie wspomniany już model shape_predictor_68_face_landmarks.dat:
PREDICTOR = dlib.shape_predictor(
"shape_predictor_68_face_landmarks.dat")Tak zaimplementowany detektor działa w sposób szybki i wygodny dla użytkownika.
Przekształcenia afiniczne
W tej sekcji skupimy się na przekształceniach obrazu. Cały notebook z kodem i dodatkowymi komentarzami dostępny jest jest jako affine transformation.ipynb.
Wiemy już co co to jest triangulacja. Umiemy ją nawet już wyznaczyć! Teraz chcielibyśmy móc przekształcić jeden wybrany obszar (dokładniej trójkąt) na jednym obrazku (np. poniżej policzek środkowej postaci) w drugi odpowiadający trójkąt na drugim rysunku (w policzek na pierwszym od lewej obrazku).

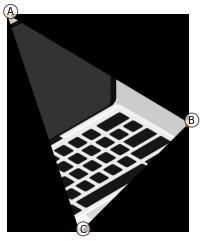
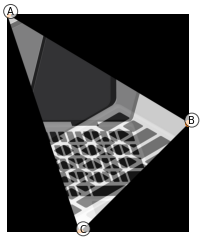
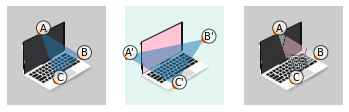
By nauczyć się bardziej dokładniej o przekształceniach afinicznych weźmy obrazek [3], nie zależy od bazy z twarzami.
# wczytaj przykładowy obraz
img = cv2.cvtColor(cv2.imread('laptop_black.jpg'), cv2.COLOR_BGR2RGB)
# narysuj
plt.imshow(img)
plt.axis('off')
Następnie wyznaczmy trzy punkty, które będą określać nam trójkąt
# Wyznacz 3 wierzchołki trójkąta
A = [int(img.shape[1]/3), int(img.shape[0]/4)]
B = [int(img.shape[1]*3/4), int(img.shape[0]/2)]
C = [int(img.shape[1]/2), int(img.shape[0]/4*3)]
# określ trójkąt z wierzchołkami A, B i C
src_anotation_label = ['A', 'B', 'C']
src_triangle = np.array([A, B, C])Obraz wraz trójkątem „wejściowym”, czyli takim, który będziemy przekształcać z bazowego obrazka wygląda następująco:

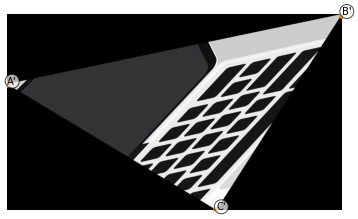
Następnie wyznaczmy wierzchołki trójkąta, w które dany trójkąt wejściowy będzie przekształcany.
# Definie destination triangle
A_prim = [0, int(img.shape[0]/2)]
B_prim = [int(img.shape[1]*4/5), int(img.shape[0]/3)]
C_prim = [int(img.shape[1]/2), int(img.shape[0]*4/5)]
# definiowanie trójkąta wyjściowego
dst_anotation_label = ["A'", "B'","C'",]
dst_triangle = np.array([A_prim, B_prim, C_prim])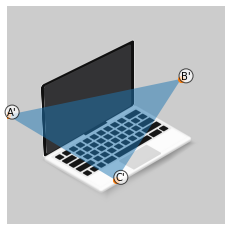
Przekształcenie będzie polegać na „zrzutowaniu” punktów A na A’ , B na B’ oraz C na C’. Oczywiście wszystkie cały środek trójkąta wejściowego także powinien zostać przekształcony.
Wyznaczmy teraz koordynaty prostokąta, który będzie obejmował cały trójkąt wejściowy:
bounding_source_rectangle = cv2.boundingRect(np.float32([src_triangle]))A następnie przytnimy obraz wejściowy, tak aby obraz obejmował tylko trójkąt, który będziemy przekształcać. Zauważmy, że wystarczy użyć koordynat prostokąta, uzyskanego chwilę wcześniej.
rect = bounding_source_rectangle
# uzyskaj wycinek obrazu wejściowego img, tak aby obejmował tylko trójkąt wejściowy.
img_bounded_by_source_rectangle =
img[rect[1]:rect[1] + rect[3],
rect[0]:rect[0] + rect[2]]Przycinając obraz, rzecz jasna, zmieniamy koordynaty trójkąta wejściowego!
bsr = bounding_source_rectangle
# zmiana koordynat trójkąta, tak aby odpowiadały przyciętemu obrazowi.
src_triangle_in_bounding_rectangle = []
for i in range(0, 3):
src_triangle_in_bounding_rectangle.append((
(src_triangle[i][0] - bsr[0]),
(src_triangle[i][1] - bsr[1])))Po tych kilku prostych operacjach możemy narysować wycinek:

Stwórzmy teraz maskę, która określać będzie trójkąt wejściowy:
src_mask = np.zeros((bounding_source_rectangle[3],
bounding_source_rectangle[2], 3), dtype = np.float32)
# Fill triangle in mask
cv2.fillConvexPoly(src_mask, np.int32(src_triangle_in_bounding_rectangle), (1, 1, 1));
Maska wygląda następująco:

Ponieważ czarne miejsca w miejsca wypełnione są zerami, chcąc uzyskać tylko i wyłącznie obraz trójkątów wystarczy przemnożyć maskę wraz z wycinkiem. Piksele objęte białym obszarem będą przemnożone razy 1, przez co nie zmienią swoich wartości, w przeciwnym razie wartości wyzerują się.
bounded_triangle = (src_mask *
img_bounded_by_source_rectangle).astype(int)Uzyskamy wtedy następujący efekt:
Dokładnie takie same operacje wykonujemy na trójkącie docelowym, czyli takim w który chcemy przekształcić trójkąt wejściowy:

W końcu możemy zdefiniować funkcję, która dokona przekształcenia. Będziemy działać na obrazie src_img, i dokonować transformacji src_triangle w dst_triangle. Będziemy także pododawać rozmiar size:
# define geometric transformation which preserves collinearity
def affine_transform(src_img, src_triangle, dst_triangle, size) :
# find the affine transform.
warpMat = cv2.getAffineTransform(
np.array(src_triangle).astype(np.float32),
np.array(dst_triangle).astype(np.float32) )
# apply the Affine Transform
output_img = cv2.warpAffine( src_img, warpMat, (size[0],size[1]))
return output_imgPrzykładowo, dla naszego przykładu, użycie funkcji transformującej będzie wyglądać następująco:
# transformacja obszaru trójkąta źródłowego na docelowy
warpImage_src_to_dest = affine_transform(
img_bounded_by_source_rectangle,
src_triangle_in_bounding_rectangle,
dst_triangle_in_bounding_rectangle,
(bounding_destination_rectangle[2],
bounding_destination_rectangle[3]))Efekt prezentuje się następująco:
Obraz obejmujący przez trójkąt ABC został przekształcony w trójkąt A’B’C’. Oczywiście dobierając odpowiednio parametry możemy przekształcać trójkąt A’B’C’ w ABC, dokładnie na takich samych zasadach uzyskując warpImage_dest_to_src. Chcąc uzyskać cały obraz, możemy „wkleić” w odpowiedni obszar zainteresowania:
1) obraz img_bounded_by_source_rectangle poza obszarem trójkąta (aby to uzyskać wystarczy pomnożyć jako odwrotność maski: ( 1 – src_mask )
2) wynik przekształcenia np. A’B’C’ w ABC. warpImage_dest_to_src * src_mask
# stwórz kopię obrazu, tak aby móc działać na kopi
concatenated_img = img.copy()
# złącz dwa obrazy, zastępując obszar ograniczonego prostokąta.
# aby "zamienić" tylko obszar trójkąta należy użyć src_mask.
bsr = bounding_source_rectangle
concatenated_img[bsr[1]:bsr[1] + bsr[3],
bsr[0]:bsr[0] + bsr[2]] =
img_bounded_by_source_rectangle * ( 1 - src_mask ) +
warpImage_dest_to_src * src_maskEfekt docelowy wygląda następująco:
W niektórych przypadkach (a dokładnie w moim 😀 ) nie będzie chcieli zastępować piksel wejściowego obrazu w piksel przekształconego, a jedynie „nakładać” na siebie obszary, dlatego musimy dodać trochę przezroczystości. W tym celu użyjemy parametru alpha.
# zdefiniuj alfę, która pozwoli zobaczyć oba obszary.
alpha = 0.5
overlapping_img = ((1.0 - alpha) *
(img_bounded_by_source_rectangle *
src_mask.astype(int) ) + alpha *
warpImage_dest_to_src * src_mask).astype(int)Przykład nakładającego się obrazka wejściowego wraz z transformacją, na obszarze wyznaczonym przez trójkąt ABC, wygląda następująco:
Łącząc wszystkie powyższe informacje w całość, możemy bardzo łatwo stworzyć funkcję, dzięki, której będziemy mogli przekształcać wybrany trójkąt na obrazie (img2) w wybrany trójkąt na obrazie (img1). Cały efekt możemy nałożyć na concatenated_img, które najczęściej będzie kopią img1.
# of course we can transform one image to another, to do that we will definie transform_triangle funtion
def transform_triangle(img1,
img2,
concatenated_img,
src_triangle,
dst_triangle,
alpha = 0.5
):
# Find the minimal up-right bounding rectangle for both triangles
bounding_source_rectangle = cv2.boundingRect(
np.float32([src_triangle]))
bounding_destination_rectangle = cv2.boundingRect(
np.float32([dst_triangle]))
# Find image bounded by bounding_rectangle
bsr = bounding_source_rectangle
img_bounded_by_source_rectangle = img1[bsr[1]:bsr[1] + bsr[3],
bsr[0]:bsr[0] + bsr[2]]
bdr = bounding_destination_rectangle
img_bounded_by_destination_rectangle = img2[bdr[1]:bdr[1] +
bdr[3],
bdr[0]:bdr[0] +
bdr[2]]
# Because we will consider only bounded rectangles possition,
# let's change triangles corridanates
src_triangle_in_bounding_rectangle = []
dst_triangle_in_bounding_rectangle = []
bdr = bounding_destination_rectangle
for i in range(0, 3):
src_triangle_in_bounding_rectangle.append((
(src_triangle[i][0] - bsr[0]),
(src_triangle[i][1] - bsr[1])))
dst_triangle_in_bounding_rectangle.append((
(dst_triangle[i][0] - bdr[0]),
(dst_triangle[i][1] - bdr[1])))
# create RGB mask of maxium size of bounding_rectangle.
src_mask = np.zeros((bsr[3], bsr[2], 3), dtype = np.float32)
# Fill triangle in mask
cv2.fillConvexPoly(src_mask,
np.int32(src_triangle_in_bounding_rectangle),
(1, 1, 1));
# define bounded triangle
bounded_triangle = (src_mask *
img_bounded_by_source_rectangle).astype(int)
# transform source triangle into destination triangle
warpImage_dest_to_src = affine_transform(
img_bounded_by_destination_rectangle,
dst_triangle_in_bounding_rectangle,
src_triangle_in_bounding_rectangle,
(bounding_source_rectangle[2],
bounding_source_rectangle[3]))
# create overlapping img
overlapping_img = (
(1.0 - alpha) * (img_bounded_by_source_rectangle ) +
alpha * warpImage_dest_to_src).astype(int)
# concatenate two images - replace source_rectangle with
# warpImage_dest_to_src, to replaced only triangle
# -- use src_mask
concatenated_img[bsr[1]:bsr[1] + bsr[3],
bsr[0]:bsr[0] + bsr[2]] =
img_bounded_by_source_rectangle*(1-src_mask )
+ overlapping_img * src_mask
return concatenated_img, warpImage_dest_to_srcWywołanie funkcji:
concatenated_img, warpImage_dest_to_src = transform_triangle(img1,
img2, img1.copy(),
src_triangle, dst_triangle,
alpha = 0.5)Przykład transformacji trójkąta A’B’C’ z obrazka img2 na trójkąt o koordynatach ABC na obrazie img1.
trójkąta A’B’C’ na ABC
na obrazie img1
Znając już transformację afiniczną, triangulację umiejąc wyznaczyć punkty twarzy …. hej powinniśmy już umieć zamienić twarzami dwie postacie! Spróbujmy to zrobić. Najprościej będzie „przelecieć” pętlą po każdym trójkącie zamieniając go z obrazka na obrazek. Efekt zamiany twarzy widzimy poniżej:

Ok, udało nam się „przenieść” twarz z drugiego obrazka na pierwszy, ale:
1) przy alpha = 1 (czyli przy zerowej przezroczystości) otrzymujemy bardzo widoczne odcięcie „twarzy” od czoła. Jest to spowodowane oczywiście tym, że punkty którymi dysponujemy dotyczą skupiają się głównie na punkach znaczących czyli żuchwie, nosie, brwiach itd… czoło … tak naprawdę nie ma punktu znaczącego, a przynajmniej bardzo ciężko je zdefiniować. Nie ma nagłej zmiany koloru ani struktury. Możemy próbować wykryć linię brzegową włosów i tam wyznaczyć równolegle punkty – tak by stworzona maska/siatka trójkątów obejmowała także i czoło. Zrobimy to w następnej sekcji, ponieważ nie oszukujmy się, ale efekt jest nie zadawalający.
2) Gdy przezroczystość jest znikoma (alpha = 1), widzimy bardzo duże odcięcie się obrazów. Zwiększając przezroczystość możemy między innymi „otworzyć” usta drugiej postaci. Stworzona przez nas postać powinna mieć cechy i jednej i drugiej osoby. Efekt końcowy jest jednak bardziej przyjemny dla oka, dlatego warto „pobawić się” i tym parametrem.
Detekcja skóry
Zaproponowane dotychczas narzędzia pozwoliły nam wykryć zarys twarzy postaci na wybranym obrazku. Jeśli wykorzystalibyśmy tylko triangulację trójkątów powstałych z wyznaczonych punktów (landmarków) efekt… byłby niezadowalający, ponieważ omijamy czoło. Często odcienie skóry mogą się zbyt różnić i powstanie nie naturalne przejście. By temu zaradzić spróbujmy wykryć całą twarz (skórę). Kod potrzebny do realizacji tego fragmentu znajdziecie w notebooku SkinDetection/skinDetection.ipynb.
Zastanawiając się jak my “widzimy” skórę pierwszym odruchem jest pomyślenie o kolorze. Warto zaznaczyć, że algorytmy klasyczne oparte na kolorach (palecie/modelu barw RGB) mogą być niedokładne, czy nawet rasistowskie. Warto jednak zastanowić się jak wygląda skóra z użyciem innych modeli barw – czyli różnych sposobów na zapisanie koloru.
Do zabawy paletami barw możemy użyć biblioteki opencv:
import cv2Załóżmy, że zmienna img_BGR przechowuje obiekt obrazu z użyciem palety barw BGR. By manipulować kolorem wystarczy użyć wbudowanej metody cvtColor:
img_RGB = cv2.cvtColor(img_BGR, cv2.COLOR_BGR2RGB)
img_HSV = cv2.cvtColor(img_BGR, cv2.COLOR_BGR2HSV)
img_YCrCb = cv2.cvtColor(img_BGR, cv2.COLOR_BGR2YCrCb)Poniżej wybierzmy sobie 4 różne przykłady:


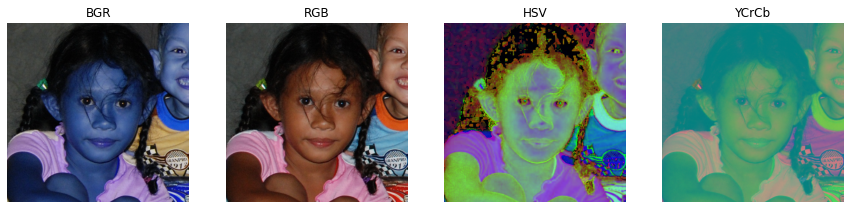
Postacie różnią się od siebie kolorem skóry, oraz oświetleniem – co widać używając palety barw HSV. Używając tego modelu możemy w dość prosty sposób mi.in odczytać jasność oraz nasycenie barwy. Przekształcenia wykonywane m.in z RGB na HSV są bardzo fajnie przedstawione pod linkiem: https://docs.opencv.org/3.4/de/d25/imgproc_color_conversions.html. Jak widzimy istnieje wiele różnych modeli barw, które znajdują różne zastosowania w przetwarzaniu obrazu. Warto czasami połączyć dwa modele, ponieważ dostajemy dodatkową (być może cenną) informację.
Tak jak na wstępie zaznaczyłam – algorytmy oparte na kolorach nie są najdokładniejsze, praktycznie niemożliwym jest postawić sztywnie ustalony próg, który oddzieli nam skórę od reszty obrazu, tak by pasował do wszystkich przykładów treningowych/testowych. Chcielibyś jednak maksymalizować dokładność, dlatego warto się zastanowić w jakich przedstałach występują wartości omawianych kolorów. By to zrobić wykorzystamy histogram wartości na danym obrazie! Przykładowo, weźmy obraz:

W powyższym wypadku widzimy, że rozkład składowej H jest bardzo skoncentrowany i ma bardzo małe ogony. Oznacza to, że wiele punktów na obrazie będzie miało tę samą wartość (co potwierdza pierwszy obrazek z nagłówkiem HSV[0]).
Najbardziej wartym uwagi jest składowa Cb w palecie barw YCrCb odpowiadający stanowiącą różnicę między luminancją (składowa Y) a czerwonym kolorem. Bardzo wyraźnie wskazuje na skórę dziewczynki.
Przyglądając się dla porównania jeszcze przykładowi:
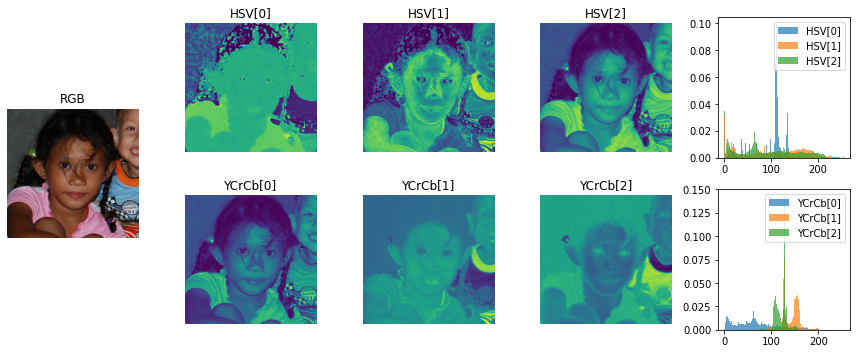
Dochodzimy do wniosku, że patrząc tylko na histogramy widzimy, że nie jesteśmy w stanie ustawić takiego progu dla składowych: HSV[2], YCrCb[0], aby móc uzyskać dobry efekt wydłużenia skóry. Co więcej, zakres skóry twarzy na obu zdjęciach jest inny. Widzimy też, że światło ma ogromny wpływ na wynik.
Dobrą wiadomością jest to, że pomimo różnych odcieni/zakresów wyraźnie widać oddzielenie skóry od reszty obrazu, na przykład na YCrCb[2] jest możliwe (ale może nie idealne). Na pierwszym zdjęciu problematyczne mogą być jasne kosmyki pasujące do koloru skóry.
Naiwne progowanie
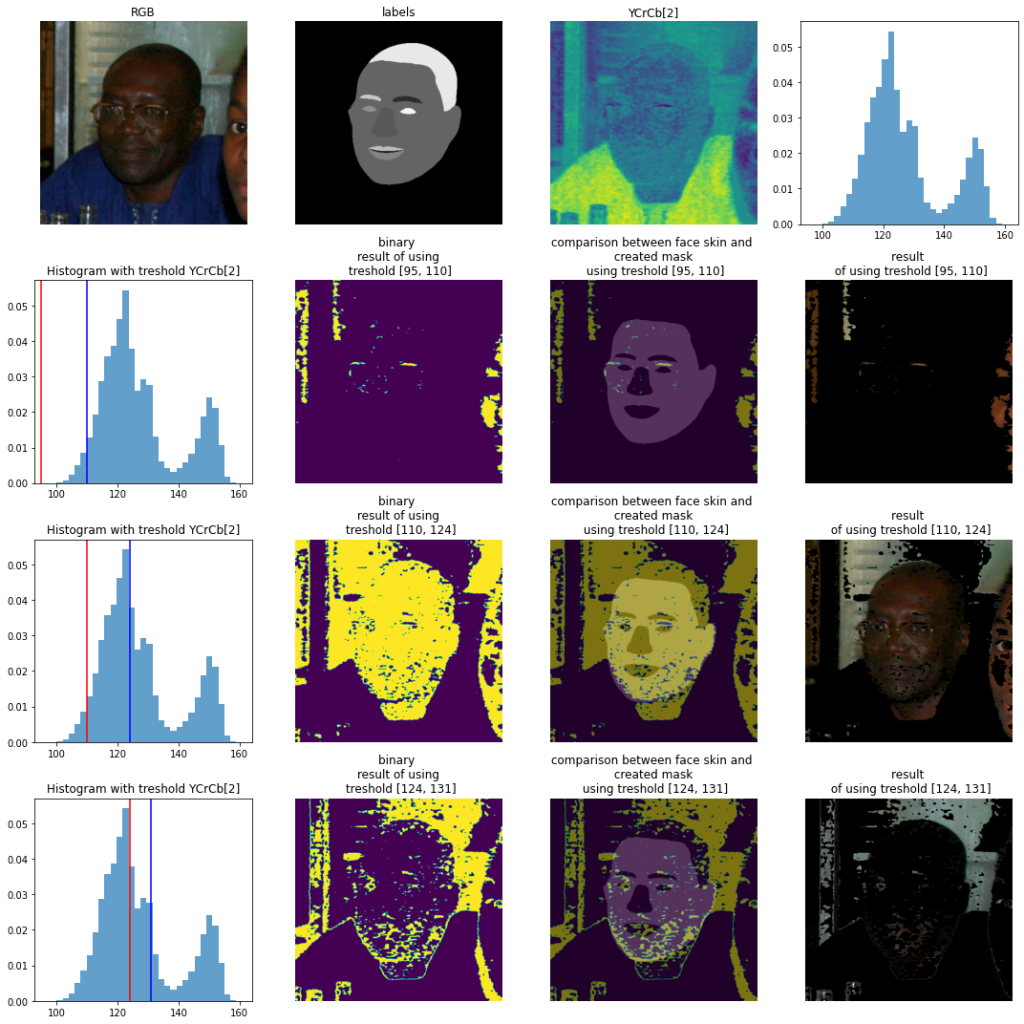
Wybierzmy jeden przykładowy komponent np. YCrCb[2] i spróbujmy dobrać taki zakres, aby móc określić skórę na obrazie. Taka metoda jest jednym z podstawowych algorytmów do segmentacji (binaryzacji) i zwana jest “Metodą Otsu”. Najczęściej mówmy o binaryzacji odcieni szarości na obrazie czarno-białym, jednakże idea jest dokładnie taka sama. Każda moda może przedstawiać inne obiekty na obrazie.

Na poniższym obrazie widzimy, że wybierając zakres wartości Cb od 95 do 110 w dużej mierze otrzymujemy obszary obrazu, które kolorystycznie przypominają skórę! Warto zauważyć, że nie tylko skórę małej dziewczynki, a także obejmującą ją dłoń. Wybierając zakres od 110 do 124 wychwytujemy ciemniejsze obszary (a właściwie te segmenty, które mają większą różnicę między luminalizacją a kolorem czerwonym). Najwyższe wartości praktycznie odpowiadają nam za białe elementy sukienki oraz wianka.
Dla porównania wykorzystajmy dokładnie te same zakresy na innym obrazku:

Widzimy, że zakresy nie zawierają w swoim przedziale wartości odpowiadających za pewną modalność. Jedynie zakres [124,161] zawierała dwie pełne modalności – w rezultacie widzimy oznaczające się tło wraz z różową i niebieską koszulkę dzieci. Pierwsza modalność została “podzielona” przez dwa zakresy. Widzimy, że lepszym zakresem było by zatem wybranie progu od 100 do 120; tak aby cała „górka” na histogramie zawiera się w zakresie.
Ostatni przykład Pana na bardzo zaszumionym obrazie pokazuje, że wybrane na sztywno progi zawierają się wszystkie w pierwszej „górce” histogramu. Nawet jeśli skupimy swoją uwagę na 2 zakresie (czyli tak naprawdę zmniejszając wariancję ), efekt jest nie zadawalający.
Warto zauważyć:
- jeśli na zdjęciu widzimy więcej niż jedną osobę, nasza baza danych nie posiada etykiet dla obu osób (np. tak jak w przypadku drugiego obrazku, gdy na zdjęciu jest dwoje dzieci, tylko jedno jest oznakowane),
- dopasowanie jednego progu jest nieskuteczne,
- histogram może zawierać więcej niż 2 mody. W zależności od wielkości powierzchni, światła i innych czynników „górka” może może mieć różną wysokość (wynika to z wariancji i ilości podobnych do siebie pikseli).
Gdy zrezygnujemy ze sztywnego progu a wybierzemy odpowiedni fragment histogramu możemy uzyskać dobre rezultaty nawet naiwną metodą:



Oczywiście możemy natrafić na problematyczny obrazek taki jak poniższy:

Mężczyzna ma kolor skóry bardzo podobny do koloru tła. Tło jednak różni się np teksturą. Zachęcam Ciebie Drogi czytelniku do zastanowienia się co jeszcze odróżnia skórę od tła. My z tym problemem poradzimy sobie inaczej niż z użyciem, kolorów, jednakże taki prosty przykład pokazuje, że Warto przejrzeć dane treningowe i zastanowić się nad warunkami jakie mogą pomóc podczas analizy.
Uśredniając wyniki:
Ponieważ mamy dość dużą bazę danych, możemy sprawdzić jak rozkładają się wartości średnie dla etykiety twarzy (skóry twarzy) dla wybranej palety kolorów.
Wybierzmy obraz (ze zbioru treningowego) a następnie wyciągnijmy obszary dla wybranej etykiety:

Następnie dla każdego z obszaru wyliczmy średnią danego koloru. Średnia jest ponownie „naiwną” statystyką. Jednakże jest najprostszą! A jeśli dziś po prostu uczymy się „myślenia” o palecie kolorów, myślę, że bardzo fajnie jest zacząć właśnie od właśnie średniej wartości pixela na wybranym obszarze. Inne statystki warte rozważania to przede wszystkim wariancja, najwyższe, najniższe wartości. Poniżej możemy zobrazować na „kafelkach” średnie wartości kolorów dla powyższego obrazka:

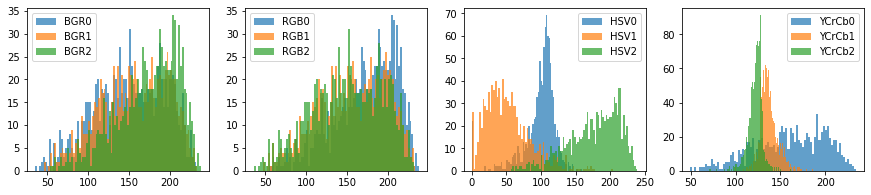
Rozkład średniej wartości odpowiednich składowych koloru dla wszystkich danych treningowych, możemy przedstawić za pomocą histogramów:
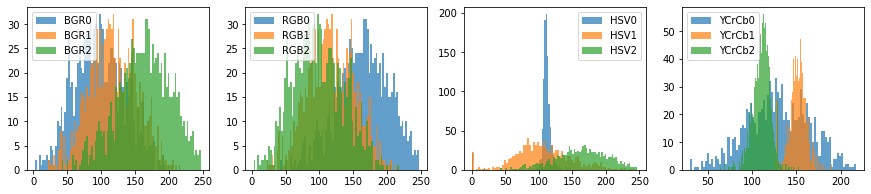
Widzimy, że przy wyborze modelu barw BGR czy RGB nie jesteśmy w stanie wybrać odpowiednie zakresy ponieważ wartości mają dużą wariancję. Na przykład dla modelu barw RGB: wartości R przyjmują zakres od 50 do 250, wartości G i B od 0 do 200. W sytuacji gdy wiemy iż maksmalny zakres obejmuje wartości od 0 do 255, widzimy, że zbyt dużo pikseli została by zaklasyfikowana jako skóra. Oznacza to też, że średnio nasz zbiór danych zawiera zdjęcia przedstawiajcie postacie o <prze>różnym odcieniu skóry, naświetleniu itp. Podkreślę jedynie, że padamy estymator średniej, który być może nie jest najbardziej wiarygodną wartością, ale zdecydowanie dużo nam podpowiada.
Drugim spostrzeżeniem jest, że wartość luminancji („Y” – 0rowej składowej YCrCb) przyjmuje prawie każą wartość z zakresu. Ciekawym spostrzeżeniem mogło by być iż rozkłady Cr i Cb są praktycznie separowane.
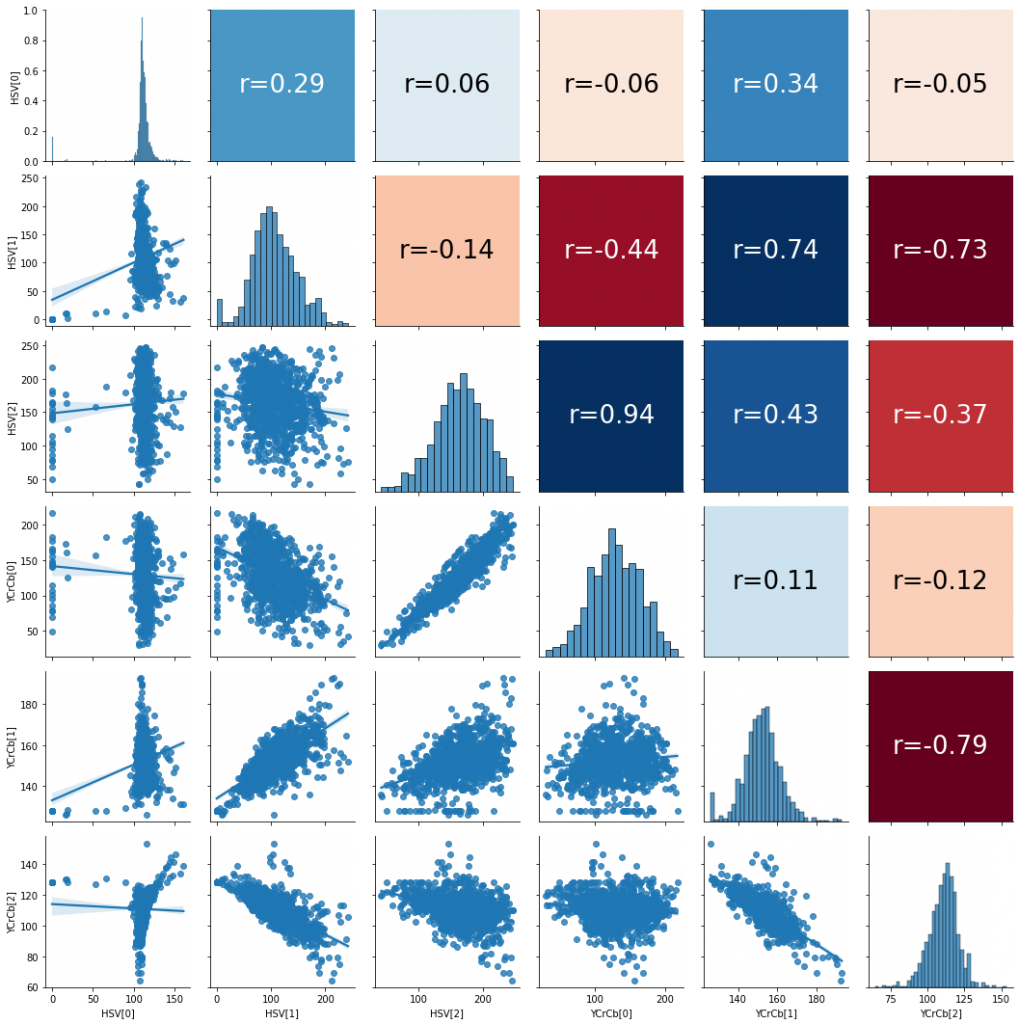
Zwykła ciekawość powinna poprowadzić nas do zbadania korelacji między wartościami. Tak aby móc przyjrzeć się także osobno rozkładom wybranych składowych. Widzimy, że wartości mogą pochodzić z pewnych rozkładów Gaussowskich, z jedną modalnością. Nie powinno nas też dziwić korelacja równa 0.94 pomiędzy składową V w palecie barw HSV oraz składową Y w palecie barw YCrCb. Obie te wartości starają się opisać światło.
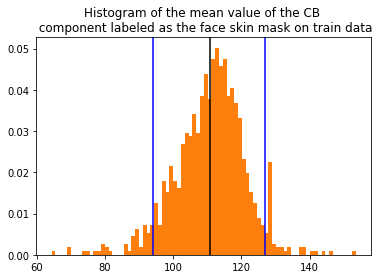
Przyglądając się rozkładowi średniej wartości komponentu Cb możemy na pierwszy rzut oka zobaczyć, że rozkład jest dość „symetryczny”. W łatwy sposób możemy m.in odczytać wariancję (ok 100).
Mają więc informację o średnich wartościach obliczonych za pomocą wyselekcjonowanego regionu z pomocą etykiety twarzy, możemy zobaczyć jak ustawione wartości progowania mogły by wpłynąć na metryki. Zróbmy więc odwrotną czynność: wybierzmy średnią wartość jaka powinna przyjmować skóra i sprawdźmy jak wpływa to na rezultat. Ponieważ jest to czynność tylko i wyłącznie w formie ćwiczeń operacje wykonamy na tym samym zbiorze tak by móc wyciągnąć dodatkowe wnioski. Rozważane metryki to:
- precyzja (precision)
- IoU (Intersection over Union / jaccard_score)
- czułość (recall)
Możemy zdefiniować funkcję measure, która pozwoli nam na „porównanie” obszaru zaznaczonego jako etykieta skóry twarzy (wartość 1) „truth”:
truth = (img_inf['labels']==1)[:,:,0]oraz produkowanego („predicted”) obszaru, tam gdzie spodziewamy się skóry na obrazku:
predicted = generated_maskFunkcja measure, korzysta z zaimplementowanych już metryk, dlatego należy pamiętać o imporcie odpowiednich bibliotek:
from sklearn.metrics import precision_score, recall_score, jaccard_scoredef measure(truth, predicted):
# najpierw musimy doprowadzić do formy, którą będziemy mogli
porównywać
real = truth.flatten()
pred = predicted.flatten()
# obliczamy metryki
iou_measure = jaccard_score(real, pred)
recall_score_measure = recall_score(real, pred, zero_division = 0)
precision_score_measure = precision_score(real,pred,zero_division=0)
return iou_measure, recall_score_measure, precision_score_measurePrzyjrzyjmy się jeszcze raz na moment:
treshold_ranges = [ [(90), (108)] ]
example_img = '10256701615_6'
img_inf = images[example_img]
Jak widać udało nam się osiągnąć bardzo naiwne progowanie obszaru skóry. Problem polega jednak na tym, że skóra została wykryta nie tylko na twarzy, ale także na dekolcie i dłoni, która nie należy do dziewczyny. Obliczmy metryki dla zadanego obrazka:
iou_measure, recall_score_measure, precision_score_measure =
measure(truth, predicted)
iou: 0.3767724782468579 recall: 0.9548207803992741 precision: 0.38361139846786946
Pomimo tego, że zdefiniowaliśmy precyzję, czułość i IoU, nie istnieje jedna, jedyna wiarygodna miara dla zadania wykrycia skóry.
Recall będzie w tym wypadku przyjmować dużą wartość, ale precyzja nie. Wynika to z tego, że wykrywamy na obrazu całą widoczną skórę – a nie tylko i wyłącznie skórę twarzy. Maksymalizując recall dążymy do tak naprawdę zaznaczenia większego obszaru – w którym może (ale nie musi) znajdować się interesujący nas obszar. Z drugiej strony maksymalizując precyzję dążymy do zaznaczenia mniejszego obszaru niż obszar wskazany przez etykietę. IoU stara się w pewien sposób połączyć te dwie metryki.
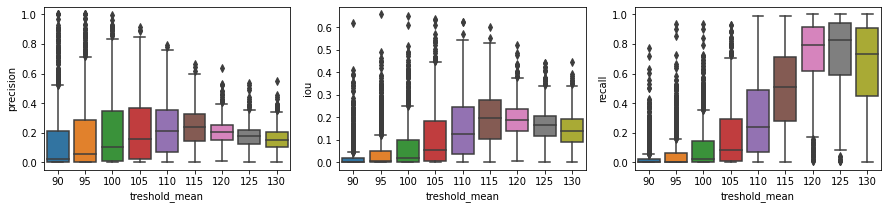
Pomimo tego, że same wartości metryk są mało wiarygodne (zwłaszcza bez odniesienia); możemy swoją uwagę skupić na trendzie wartości metryk (powstały w wyniku procesu sprawdzenia hiperparametrów).
Patrząc na histogram:
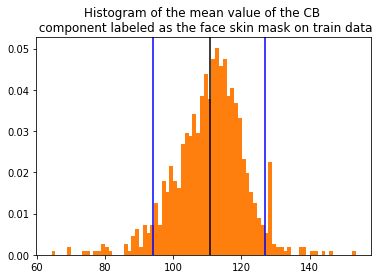
widzimy, że nasze metryki będą średnio zmaksymalizowane, gdy średnia wartość wartości komponentu Cb będzie dążyć do średniej wartości rozkładu. Możemy to stwierdzić, ponieważ działamy na tym samym zbiorze.
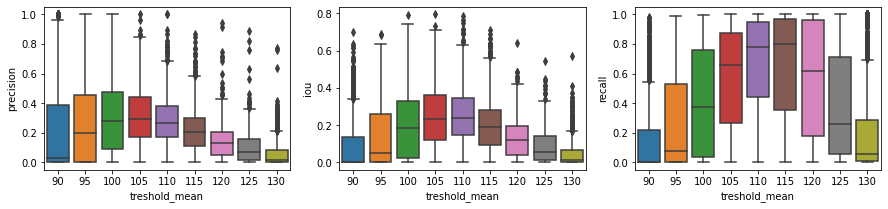
Pierwszą rzeczą, którą rzuciła mi się w oczy są bardzo niskie wartości pozyskanych metryk. Jest to w pewien sposób oczywiste – metoda klasyczna oparta jedynie na jednym komponencie koloru — nie oczekiwałam za dużo! Duże ogony w rozkładach sugerują, że wiele obrazów we zbiorze danych jest po prostu różna od średniej. Najgorzej wypadają skrajne wartości (dalekie od średniej rozkładu = 110) takie jak treshold_mean = 90 lub 130. Tak czy siak, powyższe wykresy w bardzo prosty sposób dodają nam interpretację do histogramu — ustając próg bliski średniej będziemy mogli „obsłużyć” więcej przypadków, wynika to z gaussowskiego charakteru rozkładu.
Drugim spostrzeżeniem powinno być zwrócenie uwagi na wartości metryki recall, okazuje się, że są one wyższe niż w przypadku precision, wynika to z charakteru progowania. Ustalając naiwnie próg mamy tendencję do zaznaczenia znacznie większego obszaru niż skóra twarzy (tylko taką etykietę posiadamy, odnoszącą się do skóry).
Jeśli ktoś by się zastanowił to badanie jednego komponentu jednej palety na nie preprocesowanych obrazach brzmi bardzo naiwnie 😀 Choć działa nie do końca wspaniale – to ej ! nie działa tragicznie.
Przypatrzmy się postaci, której kolor skóry ma podobny odcień co kolor tła.


normalizacja:
def equalizeHists(img):
channels = cv2.split(img)
output = []
for i in channels:
output.append(cv2.equalizeHist(i))
equ = cv2.merge(output)
return equWyrównajmy histogramy względem modelu barw BGR (zachęcam do wypróbowania do innych modeli):
equ = equalizeHists(img_BGR)

Ograniczając składnik Cb (z palety kolorów YCrCb), możemy mniej więcej określić kolory skóry na obrazach. Patrząc na konkretny przykład obrazu, możemy powiedzieć, że średnio kolor skóry ma zmienność około 10, a średnia wynosi od 100 do 120. Można to również zobaczyć na obrazie pokazującym histogramy odpowiednich składników wygenerowanych dla podstawienia danych treningowych.
Detekcja skóry twarzy
Jak pewnie łatwo było zauważyć w ostanim akapicie omawiana detekcja obejmowała całą skórę widoczną na obrazie. My chcielibyśmy wykryć tylko skórę twarzy, ze względu na chęć uwzględnienia czoła, by uzyskać bardziej naturalny rezultat niż poniższy:

Pełny kod dotyczący tego rozdziału z wieloma komentarzami znajduje się w notebooku: SkinDetection/skinDetectionWithFaceLandmarks.ipynb.
Chcielibyśmy skupić się na całym obszarze twarzy, tak aby maska nie obejmowała szyi czy włosów. Pomogą nam w tym punkty orientacyjne. Dzięki nim w łatwy sposób będziemy mogli ograniczyć przestrzeń wyników. Mówiąc po ludzku — jeśli wykryjemy linię szczęki z pomocą punktów znaczący, obszar „poniżej” wyznaczonej linii będzie ignorowany. Uznajemy bowiem, że nie może istnieć „twarz” poniżej szczęki. Takich reguł logicznych można stworzyć dużo więcej. Przypominam, że o wykrywaniu punktów znaczących można przeczytać w FaceLandmarks/faceLandmarks.ipynb.
Punkty orientacyjne twarzy są idealną bazą, którą możemy wykorzystać do zdefiniowania regionu zainteresowania lub podstawowej maski:

Na powyższym obrazku wykorzystaliśmy punkty by móc zdefiniować pewien podstawowy obszar. Jeśli byśmy się nad tym zastanowili — jest to obligatoryjny obszar, który chcemy wykrywać. Zastanawiając się jak możemy utrudnić sobie zadanie z jednej strony warto pod uwagę brać maskę bez uwzględnienia oczu, nosu czy ust (full mask: False), ponieważ możemy bezpośrednio porównać to z etykietą „skóra twarzy” (class = 1). Etykiety były omawiane w MeetDataset/meetDataset.ipynb. Z drugiej strony, dla naszego zadania dokładność wykrycia skóry twarzy może nie być aż tak znacząca… Możemy przecież stworzyć nową etykietę stworzoną z „sumy” etykiet: „skóra twarzy”, „nos”, „usta”, „oczy”.
Pamiętając jak wyglądają histogramy kolorów z poprzedniego rozdziału, zastanówmy się czy moglibyśmy „spersonalizować” jakoś tworzenie zakresów progowania. Bardzo, bardzo prostym sposobem mogło by być wyznaczenie „maski podstawowej”/”maski bazowej” z użyciem punktów znaczących. Następnie policzenie średniej wartości koloru skóry oraz wyznaczenie pewnego zakresu, który obejmowałby najbardziej prawdopodobne wartości odcieni skóry.
Licząc średnią nie możemy uwzględnić brwi, oczu, ust ponieważ zaburzą nam one kolorystykę skóry 🙂 Przykładowo usta zwiększą nam wartość odpowiadający za kolor czerwony.
Poniżej widzimy średnie wartości kolorów na obszarze wyznaczonym przez 2 od lewej maskę na ostatnim obrazku (marked by: jaw; full mask: False). Nazwijmy ją landmarks_mask.

BGR: (48.42768615692154, 70.66186906546727, 121.20029985007496),
RGB: (121.20029985007496, 70.66186906546727, 48.42768615692154),
HSV: (110.91007829418623, 155.52293853073462, 121.20782941862402),
YCrCb: (83.25850408129268, 155.1006829918374, 108.34702648675662)]
Jeszcze raz przyglądnijmy się uważnie histogramowi, a dokładniej skupmy się na komponencie Cb w palecie barw YCrCb (czyli YCrCb[2]):
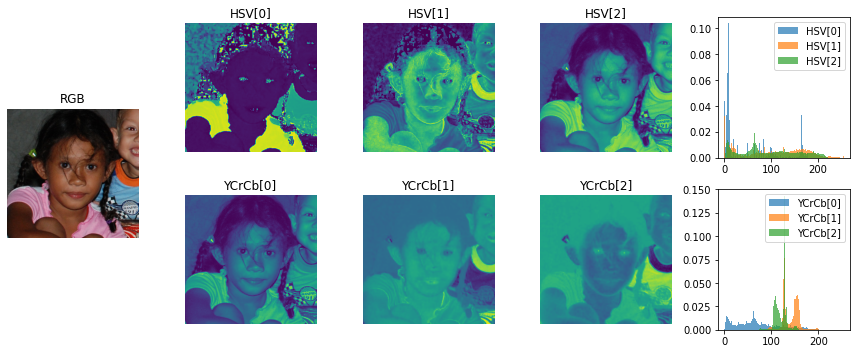
Widzimy, że składowa Cb ma takie 3 charakterystyczne regiony: pierwsza modalność, która jak już powyższej widzieliśmy odpowiada w dużej mierze za kolor skóry. Załóżmy, że średnia tej modalności będzie przyjmować wartość w przybliżeniu 108. Jest to wartość otrzymana z wyliczenia średniej wartości pikseli pokrytych przez maskę (widoczne powyższe kafelki).
landmarks_mask_with_extended_roi to maska oparta na landmarks_mask. Jest to maska, o dolnym ograniczeniu tak jak landmarks_mask. Dolne ograniczenie stanowi zatem linia wyznaczona przez punkty orientacyjne żuchwy. Górnym ograniczeniem będzie wartość oparta na długości twarzy (wartości w osi OY).
Utwórz maskę (skin_recognition_via_threshold), która będzie rozpoznawać skórę na obrazie. Niech próg będzie zakresem wartości kolorów dla wybranego komponentu koloru:
𝑡𝑟𝑒𝑠ℎ𝑜𝑙𝑑𝑟𝑎𝑛𝑔𝑒 = [𝑡𝑟𝑒𝑠ℎ𝑜𝑙𝑑_𝑚𝑒𝑎𝑛 – 𝑡𝑟𝑒𝑠ℎ𝑜𝑙𝑑_𝑠𝑑, 𝑡𝑟𝑒𝑠ℎ𝑜𝑙𝑑_𝑚𝑒𝑎𝑛 + 𝑡𝑟𝑒𝑠ℎ𝑜𝑙𝑑_𝑠𝑑],
gdzie 𝑡𝑟𝑒𝑠ℎ𝑜𝑙𝑑_𝑚𝑒𝑎𝑛 jest średnią wartością składowej ograniczonej przez maskę utworzoną na podstawie liczby punktów orientacyjnych (landmarks_mask). W tym wypadku będzie to wartość 108.34702648675662.
Maska skin_recognition_face_roi jest częścią wspólną zarówno landmarks_mask_with_extended_roi jak i skin_recognition_via_threshold.

Podsumowanie:
landmarks_mask – jest maską wyznaczoną przez punkty znaczące. To na jej podstawie liczymy podstawowe statystki do dalszej obróbki. Używamy do tego średniej wartości palety barw YCrCb. A dokładniej tylko komponentu Cb. Czy jest to wystarczające? Przekonamy się w krótce, że jednak nie. Jednak jest to bardzo proste! A daje niesamowite wyniki.
landmarks_mask_with_extended_roi – jest to dokładnie maska landmarks_mask poszerzona o większy region zainteresowania – tak by próbować uchwycić czoło.
skin_recognition_via_threshold – maska powstała z pomocą zwykłego progowania. Wartości brane pod uwagę znajdują się w zbiorze wartości 𝑡𝑟𝑒𝑠ℎ𝑜𝑙𝑑𝑟𝑎𝑛𝑔𝑒 = [𝑡𝑟𝑒𝑠ℎ𝑜𝑙𝑑_𝑚𝑒𝑎𝑛 – 𝑡𝑟𝑒𝑠ℎ𝑜𝑙𝑑_𝑠𝑑, 𝑡𝑟𝑒𝑠ℎ𝑜𝑙𝑑_𝑚𝑒𝑎𝑛 + 𝑡𝑟𝑒𝑠ℎ𝑜𝑙𝑑_𝑠𝑑]. Gdzie 𝑡𝑟𝑒𝑠ℎ𝑜𝑙𝑑_𝑚𝑒𝑎𝑛 jest średnią wartością komponentu Cb w landmarks_mask . 𝑡𝑟𝑒𝑠ℎ𝑜𝑙𝑑_𝑠𝑑 jest wartością odpowiadającą za odchylenie standardowe od 𝑡𝑟𝑒𝑠ℎ𝑜𝑙𝑑_𝑚𝑒𝑎𝑛 (zakładając naiwnie, że rozkład byłby normlany). Przyjmiemy na razie, że 𝑡𝑟𝑒𝑠ℎ𝑜𝑙𝑑_𝑠𝑑 =10.
Jak widzimy na obrazu dzięki skin_recognition_via_threshold udało nam się wyznaczyć całą skórę (być może delikatnie nie dokładnie na rękach dziewczynki). Obszar obejmujący maskę obejmuje także drugą postać — chłopca, który w tym zadaniu nie powinien być uwzględniany.
skin_recognition_face_roi – jest to maska wyznaczona jako część wspólna skin_recognition_via_threshold i landmarks_mask_with_extended_roi. Oznacza to, że skin_recognition_via_threshold została w tym ptzypadku ograniczona przez landmarks_mask_with_extended_roi. Zostały pominięte obszary szyi, kończyn czy drugiej postaci; a także ust i nos.
Wracając do naszego histogramu dla wybranego komponentu (YCrCb[2]). Kolorem czerwonym zaznaczono wartość treshold_range dla obszaru, który został sklasyfikowany jako skóra. Niebieska linia pokazuje średnią wartość obliczoną z komponentu przy użyciu maski landmarks_mask:

Możemy zauważyć, że tworzenie nowej maski (skin_recognition_face_roi) różni się nieco od maski landmarks_mask. Maska utworzona z landmarkami (landmarks_mask) jest naszą maską bazową, w której zakładamy, że poprawnie zaznacza ona linię brzegową, zawsze powinniśmy brać ją pod uwagę. Dlatego uzupełnijmy maskę skin_recognition_face_roi o brakujące piksele, które zostały uwzględnione w landmarks_mask. Takie postępowanie pozwala nam na to, że maska bazowa jest zawsze uwzględniona. Dodatkowo, krawędzie są bardziej gładkie. Oczywiście procedura ta nie jest wymagana, ale jest przydatna w naszej analizie.

Poprzednio przyjęliśmy, że 𝑡𝑟𝑒𝑠ℎ𝑜𝑙𝑑_𝑠𝑑 jest równe 10. Sprawdźmy, szybko jeszcze ten hiperparametr:

Bardzo łatwo zauważyć, że zbyt mała 𝑡𝑟𝑒𝑠ℎ𝑜𝑙𝑑𝑠𝑑 nie jest w stanie wyznaczyć odpowiedniej maski, jak w przypadku (st = 0 lub st = 3). Używając zbyt dużej wartości (std=20), wynik (skin_recognition_via_threshold) zawiera prawie cały obraz, czyli w ograniczeniu skin_recognition_face_roi będzie równy maksymalnemu roi twarzy (landmarks_mask_with_extended_roi).
Przypaczmy się teraz konkretnemu przypadku '10004446093_3′:

Po pierwsze należy zauważyć, że ta maska ma wiele prześwitów. Jednym z najbardziej znanych sposobów, aby poprawić wynik jest użycie operacji morfologicznych. Dokładnie: operacja zamknięcia.
Ale jest jeszcze jeden problem. Czy widzisz małą część szyi nad włosami kobiety? Być może powinniśmy zignorować „odstającą część”? Łatwo przecież można sobie wyobrazić przypadek osoby bez włosów, która nosiłaby opaskę. Naturalnie powstaną dwie osobne obszary wykrycia skóry.
By sprawdzić ile osobnych obszarów zawiera maska użyjemy funkcji z opencv:
# skin_recognition_face_roi_unit8 przedstawia maskę w kodowaniu unit8
output =cv2.connectedComponentsWithStats(skin_recognition_face_roi_unit8)
(numLabels, labels, stats, centroids) = outputOkazuje się, że maska posiada aż 12 osobnych komponentów!
numLabels
output: 12
Jak widać na powyższym obrazku, zdecydowanie widoczny jest jeden obszar zaznaczony na pomarańczowo. Pozostałe połączone komponenty są bardzo malutkie. Możemy dokładnie sprawdzić ile pikseli zawiera dany segment:
# Utwórz słownik z etykietami segmentów jako kluczami i liczbą pikseli odpowiadających etykietom jako wartościami
segments = dict(collections.Counter(labels.flatten()))
# dla lepszej wizualizacji możemy posortować wartości i sprawdzić, który segment jest największy
segments_sorted = dict(sorted(segments.items(), key=lambda x:x[1], reverse = True))
segments_sortedoutput:
{0: 159294,
6: 21394,
2: 342,
4: 174,
8: 46,
1: 27,
10: 20,
5: 10,
3: 8,
9: 8,
11: 7,
7: 2}Zauważ, że mamy dwa największe segmenty. Jeden z nich to najprawdopodobniej tło:

Teraz poprawmy wynik za pomocą operacji morfologicznej. Możemy sprawdzić operację zamykania i dylatacji. Mogę napisać o tym wiele, ale szczerze mówiąc najlepszy tutorial można znaleźć pod linkiem https://docs.opencv.org/4.x/d9/d61/tutorial_py_morphological_ops.html, który jest właściwie dokumentacją OpenCV.
Ostrzeżenie! Oczywiście w zbiorze znajdują się obrazy o różnych rozmiarach, więc branie kernela o jednym rozmiarze jest nawine, ale … nieważne, życie jest zbyt krótkie, aby rozważyć wszystkie opcje. Jeśli masz czas, gorąco zachęcam do tego!
# wybierzmy kernel o rozmiarze 5 na 5:
kernel = np.ones((5,5),np.uint8)# stwórzmy obraz (closing_img) po zastosowaniu operacji morfologicznej
# zamknięcia (cv2.MORPH_CLOSE) o takich samych rozmiarach jak obraz
# wejściowy (input_img)
input_img = skin_recognition_face_roi_unit8
closing_img = cv2.morphologyEx(input_img , cv2.MORPH_CLOSE, kernel)# stwórzmy obraz (closing_img) po zastosowaniu operacji
# dylatacji (cv2.dilate) o takich samych rozmiarach jak obraz
# wejściowy (input_img)
dilation = cv2.dilate(input_img, kernel, iterations = 1)
Jeśli przeczytałeś na czym polegają operacje zastosowane wyżej w tutorialu pod linkiem udostępnionym Ci chwilę wcześniej nie powinneś/aś być zaskoczony uzyskanym rezultatem.
Z użyciem dylatacji powiększyliśmy obszar maski. Dokładniej brzegi zostały powiększone o kernel. A DOKŁADNIEJ: jeśli kernel (tu: 5na5) objął jakikolwiek piksel oznaczony jako maska (na powyższym zestawieniu „original result”) oznaczył otoczenie tego piksela jako maska — tym samym zwiększając obszar maski.
Zamknięcie polega na zmniejszeniu dylatacji. Oznacza to, że najpierw rozważamy „original result” następnie wykonywana jest transformacja z użyciem dylatacji. A następnie wykonywana jest „erozja”. Czyli po uzyskanym obrazie z kroku z dylatacji ponownie „przechodzimy” kernelem po obrazie sprawdzając czy tym razem CAŁY kerenel zawiera piksele oznaczone jako maska. Tym sposobem zmniejszany jest obszar.
Tymi bardzo prostymi sposobami byliśmy w stanie usunąć w dużej mierze szum. A liczba oddzielnych segmentów po użyciu operacji zamknięcia zmniejszyła się do 6!

Co teraz? Oczywiście możemy robić co chcemy i jest wiele możliwości. Głównie ten tutorial powstał z myślą by się nauczyć jak najwięcej różnych operacji i metod. Dlatego następnym krokiem będzie znalezienie największego obszaru, a następnie „predykcja” jego konturów. Słowo „predykcja” nie bez powodu znajduje się w cudzysłowie. W pewnym sensie znajdujemy bowiem linię brzegową z pewną dokładnością epsilon. Całość bardzo fajnie ująć w funkcję, którą nazwiemy approximate_contour.
Aby znaleźć kontury oraz hierarchie używamy funkcji cv2.findContours(img, 1, 2).
contours, hierarchy = cv2.findContours(img, 1, 2)Następnie musimy znaleźć największy obszar, który zostanie objęty konturem. Na samym początku wybierzmy sobie obszar otoczony pierwszym konturem contours[0]. A następnie porównajmy za pomocą zwykłej funkcji for następne obszary. Jeśli pojawi się jakiś większy obszar niż dotychczas znaleziony max_area, następuje podmianka. Poniższy kod można obudować w osobą funkcję.
# select first contour anc set is as maxium area
cnt = contours[0]
max_area = cv2.contourArea(cnt)
face_contour = np.zeros((*img.shape, len(color)), np.uint8)
# check if diffrent contour isn't contour of the biggest area
for contour in contours:
if cv2.contourArea(contour) > max_area:
cnt = contour
max_area = cv2.contourArea(contour)Jeśli mamy już obszar, który nas interesuje najbardziej – czyli największy obszar maski, który powstał po zastosowaniu operacji zamknięcia możemy spróbować zaproksymować jego „kształt wypukły” z pewną dokładnością epsilon
# stwórz aproksymację
eps = epsilon * cv2.arcLength(cnt, True)
approx = cv2.approxPolyDP(cnt, eps, True)Ostatecznie możemy jeszcze zdecydować czy chcemy uzupełniać/wypełniać (parametr fill) wyestymowany obszar pewnym kolorem (color). Funkcja approximate_contour może wygląda następująco:
def approximate_contour(img: np.array,
epsilon: float = 0.005,
color: tuple([int]) = (255, 255, 255),
fill:bool = False) -> np.array:
"""
approximates a curve or a polygon with another curve/polygon
with less vertices so that the distance between them
is less or equal to the specified precision.
Parameters
----------
img: np.array
input image, where object's countour is detected
epsilon: float
Parameter specifying the approximation accuracy.
This is the maximum distance between the original curve and
its approximation.
color: tuple([int])
output mask/countour color
fill: bool
option that created countour can be filled by color paramter.
Default fill = False, output is just countour.
Returns
-------
face_contour: np.array
image of the same size and type as source image, represents
contour of object, using epislion aproximation
"""
# find all contours in image
contours, hierarchy = cv2.findContours(img, 1, 2)
# select first contour anc set is as maxium area
cnt = contours[0]
max_area = cv2.contourArea(cnt)
face_contour = np.zeros((*img.shape, len(color)), np.uint8)
# check if diffrent contour isn't contour of the biggest area
for contour in contours:
if cv2.contourArea(contour) > max_area:
cnt = contour
max_area = cv2.contourArea(contour)
# create area(contours) aproximation
eps = epsilon*cv2.arcLength(cnt,True)
approx = cv2.approxPolyDP(cnt,eps,True)
# fill the contour depending on the parameter 'fill'.
if fill:
_ = cv2.fillPoly(face_contour, pts = [approx], color=color )
else:
_ = cv2.drawContours(face_contour, [approx], -1, color, 3)
return face_contourJak widzimy na poniższym obrazku zmiana parametru epsilon zmienia dokładność aproksymacji największego obszaru. Zwiększenie epsilonu powoduje mniejszy szum w linii — co oznacza, że obiekt może być nie dopasowany. Zbyt mały epsilon powoduje jednak wiele zagięć, oraz może powodować zbytnie dopasowanie się linii.

Ktoś teraz by mógł zapytać — „skoro.. tak czy siak szukamy aproksymacji największego obszaru, to po co robiliśmy operację morfologiczne? Przecież dopasowując odpowiedni epsilon możemy spróbować zniwelować dziury w masce?” To byłoby bardzo cenne pytanie. Dlatego dla porównania efekt aproksymacji na masce bez operacji morfologicznych:

Co widzimy? Operacje morfologiczne pomagają wygładzić efekt. Oznacza to, że warto było je użyć w kontekście tego zadania by spróbować wyeliminować szumy itp. Zwłaszcza widać do dla mniejszych epsilonów gdy krawędź stała się bardzo kanciasta.
Jeszcze jedna mała uwaga. Aktualnie stworzyliśmy w jakiś tam sposób maskę opartą na kolorze i może się okazać, że niektóre elementy, które były w masce bazowej landmarks_mask nie występują w powstałej masce. Sztucznie uzupełnijmy tak by program ZAWSZE uwzględniał landmarks_mask jako maska.

Mimo to użycia operacji morfologii, nie za bardzo podoba mi się nierówna linia włosów. Jasne, pani na zdjęciu ma grzywkę. ale pomyślmy, czy da się to jeszcze jakoś naprawić używając prostych zabiegów takich jak ConvexHull (https://docs.opencv.org/3.4/d7/d1d/tutorial_hull.html).
Efekt znalezienia wypukłego kształtu na zbioru punktów (pikseli tworzących maskę) widoczny jest na poniższym obrazku:

Powstały obszar powinien wskazywać twarz osoby na zdjęciu. Załóżmy, że jest to prawda (nie jest 😀 ale o tym powiem więcej później). Ponownie mamy jednak problem ze znalezieniem granicy włosów (czyli skóry). Może zatem ruch z zlezieniem „obszaru wypukłego” nie był najlepszym co mogliśmy zrobić.. Ale brnijmy w to dalej. Znamy już jeden sposób, który opiera się na wyborze progów i ograniczeniu jednej składowej (Cb w YCrCb) oraz zastosowanie zwykłego, najzwyklejszego progowania. Być może warto jest teraz ograniczyć inne składowe? Przykładowo na powyższym obrazku Pani ma ciemnie włosy, które wyraźnie kontrastują z kolorem skóry.
Widzimy, że do głowy może przyjść wiele pomysłów opartych na odróżnieniu kolorów.
Dlatego teraz przedstawiam Wam jeden sprytny klasyczny algorytm – SLIC. Zachęcam do przeglądnięcia linku: https://docs.opencv.org/3.4/df/d6c/group__ximgproc__superpixel.html#ga0024d8bac96a9f0d49bd97665d76ae08
tym razem jednak użyjemy algorytmu z biblioteki skimage:
Używając SLIC możemy stworzyć tak zwane superpixele. W bardzo dużym ogóle i skrócie polega to na tym, że obraz zostaje podzielony na pewną liczbę segmentów podobnych do siebie. Liczba segmentów jest więc hiperparametrem, który powinien być dopasowany do wybranego obrazka.
Załóżmy, że potrzebujemy maksymalnie 10 znaczących/podobnych do siebie obszarów na obrazie z widocznym wyśrodkowanym człowiekiem, tak by móc wskazać twarz. Czemu 10? By przyśpieszyć proces. Jeśli mamy łut szczęścia tło będzie kontrastować z „wyśrodkowaną” twarzą. Twarz utworzy superpiksel na samym środku planszy 3 na 3 (9 superpikseli). Plansza 2 na 2 (4 superpiksele zdaje się już zbyt mała). 10 jest o jeden więcej niż 9, zatem algorytm „pozwala” na stworzenie odrębnego superpiksela (przykładowo, gdyby twarz była zacieniona).
# zaimportuj potrzebne funkcjie
from skimage.segmentation import mark_boundaries, slic# podziel obraz wejściowy (input_img) na maksimum 10 segmentów
# (n_segments) o wybranych parametrach sigma i compactness
segments = slic(input_img, n_segments = 10, compactness=15, sigma = 3,
start_label = 1)Do ładniejszego zobrazowania użyjemy funkcji mark_boundaries:
plotted_img = mark_boundaries(input_img, segments)Idealny przykład widoczny jest poniżej:

OK! Doskonale!!! zobacz, że superpiksel idealnie otoczył twarz poszukiwanej postaci. Ktoś może zapytać, czy nie moglibyśmy tego zrobić od razu. Moglibyśmy, ale to, że na powyższy przykład działa idealnie, nie oznacza, że algorytm zawsze działa perfekcyjnie. Musimy też być świadomi tego, co robimy, dlatego zaczęliśmy od prostego progowania.
Wróćmy jeszcze do hiperparametru n_segments. Czy 10 to jedyna prawidłowa odpowiedź? NIEE, zdecydowanie NIE. Niedługo przekonamy się dlaczego.
Z użyciem algorytmu SLIC możemy próbować polepszyć maskę (dla przypomnienia: mianem maski określam obszar, który przewidziany jest jako twarz). Jak polepszyć? Skoro wiemy, że jakieś piksele tworzą superpiksel — to powinniśmy się spodziewać, że wszystkie piksele w obrębie superpiksela będą oznaczone jako maska (lub nie będą).
Napiszmy funkcję (segments_covered_by_mask), która będzie sprawdzać, czy dany segment (niech segments zawiera wszystkie segmenty) jest procentowo „pokryty” wystraczająco (percent_covered_area_by_mask) przez maskę, którą chcemy ulepszyć (mask)
def segments_covered_by_mask(segments: np.array, mask: np.array,
percent_covered_area_by_mask: float = 0.5)
-> np.array:
"""
find the segments that are covered by the mask as a
percent_covered_area_by_mas percentage.
Parameters
----------
segments: np.array
obraz wejściowy podzielony na segmenty
mask: float
Maska, którą będziemy chcieli udoskonalić
percent_covered_area_by_mask : float
procentowo, ile maska powinna być pokryta by dany segment
został zaklasyfikowany jako przynależny do maski.
Jeśli jest on pokryty więcej niż
percent_covered_area_by_mask, pokryj cały segment jako
maska.
Returns
-------
improved_mask: np.array
"""
# wartości inicjalizujące
the_biggest_area_segment = {}
improved_mask = np.zeros_like(mask)[:,:,0]
# każdy segment
for i in set(segments.flatten()):
# wyznacz jaki obszar jaki został pokryty przez segment
segments_area = (segments == i).sum()
# oblicz ile wyznaczony obszar jest pokryty przez maskę
covered_by_mask_count_pixels = ((mask[:,:,0] == [255]) &
(segments == i)).sum()
the_biggest_area_segment[i] =
covered_by_mask_count_pixels/segments_area
# jeśli wartość pokrycia jest większa niż ustalona minimalna
# wartość pokrycia segmentu maską wtedy uznaj cały segement
# (superpiksel) jako maska
if the_biggest_area_segment[i] > percent_covered_area_by_mask:
improved_mask = np.where(improved_mask == 0,
(segments == i).astype(int),
improved_mask)
return improved_maskPoniżej żółtym kolorem pokazano część wspólną pokrycia maski wejściowej (tej, którą chcemy poprawić za pomocą algorytmu SLIC); kolorem zielonym zasznaczony jest obszar, który należał do maski, ale nie należy do superpiksela/li wyznaczonego przez SLIC; kolorem czerwonym — maska „poprawiona”. Czyli ostatecznie poprawioną maską jest obszar i czerwony i żółty. UWAGA, specjalnie poniżej jako wejściowy obrazek do algorytmu SLIC został tylko obszar, który powstał na wskutek zastosowania maski skin_convex_area_mask.

Warto sekundę zastanowić się czemu „polepszenie” maski wejściowej w przypadku landmarks_mask_with_extended_roi_mask daje gorszy wynik. Otóż, maska wejściowa (zielony i żółty kolor) zakrywa wystarczająco procentowo nie JEDEN superpiksel, a DWA! W tym przypadku segment by zostać „zaliczony” jako maska musiał pokrywać 50 % swojej powierzchni (czyli percent_covered_area_by_mask = 0.5).
Powyższy przykład był bardzo łatwy. Użyliśmy algorytmu SLIC na „wyciętej” twarzy, czyli na obszarze wskazanym przez convex_mask. Weźmy jednak trudniejszy przypadek: 10374318116_2 i zbadajmy hiperparametry:

Pierwszy rząd przedstawia maskę skin_recognition_face_roi powstałą na skutek polepszenia maski operacjami morfologicznego zamknięcia. Ponieważ skin_recognition_face_roi jest maska wyznaczona jako część wspólna skin_recognition_via_threshold i landmarks_mask_with_extended_roi oraz obligatoryjnie landmarks_mask (maskę wyznaczoną przez punkty znaczące). Do wyznaczenia maski skin_recognition_via_threshold zostałty zastosowane odpowiednie parametry średniej (mean) i odchylenia standardowego (std) koloru skóry. Ponownie, tak jak mogliśmy zaobserwować to już dużo wcześniej – im większe odchylenie standardowe tym większy obszar zostanie pokryty maską skin_recognition_face_roi.
Drugi rząd przedstawia maskę po zastosowaniu funkcji polepszającej, gdzie superpiksele (segmenty) były wyznaczane na „wyciętym” obrazie twarzy — czyli obszarze, który był odpowiadający masce skin_recognition_face_roi. Czyli:
1. wyznaczamy maskę skin_recognition_face_roi.
2. Bierzemy fragment obrazu 10374318116_2, który obejmuje maska skin_recognition_face_roi.
3. Wykonujemy algorytm SLIC na wyznaczonym w poprzednim fragmencie (cropped image) — w rezultacie otrzymujemy superpiksele.
4. Sprawdzamy, czy superpiksel przykrywa ponad 50 % maski skin_recognition_face_roi. Jeśli tak — oznacz jako maska.
Co widzimy? Zbyt przycięty/wycięty obszar twarzy — czyli zbyt mały fragment obrazu oryginalnego (cropped image) na którym wykonywany jest algorytm SLIC nie jest w stanie dać dobrych rezultatów. Jest to bardzo logiczne.
W tym wypadku obszar prawiej i lewej twarzy zdają się być klasyfikowane jako dwa osobne segmenty.
W ostatnim rzędzie pokazany jest rezultat zastosowania SLIC na nie wyciętym obrazie (czyli pominięcie 2 kroku), gdzie krok 3 jest wykonywany na oryginalnym obrazie. Ciekawe jest to, że obszar prawego policzka został „zaklasyfikowany” jako segment podobny z szyją. Okazuje się, że nie ważne jaką maskę bazową przyjęliśmy — rezulat zawsze był taki sam.
W tym konkretnie przypadku widzimy, że próba oddzielenia specjalnego regionu za pomocą cropped image może być dobrym (nie najlepszym) pomysłem. Tylko w przypadku gdy odchylenie standardowe było równe 0, wykryliśmy większy region używając SLIC na całym obrazie RGB niż na przyciętym obrazie.
W tym miejscu należy jednak dodać, że wynikowa maska końcowa powinna zawierać całą maskę bazową (landmarks_mask), oczywiście możemy wymusić dodanie tej maski.
Pomimo tego, że dodamy sztucznie landmarks_mask i cała dolna część twarzy ostatecznie znajdzie się w końcowej masce, nie powinno być tak, że połowa twarzy nie została zaznaczona uznana jako maska. Tylko przez to, że superpiksel nie był wystarczająco dokładny. Może powinniśmy rozważyć więcej segmentów dla algorytmu SLIC?
Zachęcam gorąco do pobawienia się hiperparametrami. Dla przypomnienia wszystkie kody i dokładne komentarze znajdują się w notebooku skinDetectionWithFaceLandmarks.ipynb:

Rozważając więcej segmentów, superpiksele stają się bardziej dopasowane/dokładne. Bardzo dobrze widać to zwłasza na koszulce czy włosach należących do postaci, z poza kadru. Zbyt duża ilość superpikseli nie ma sensu. Segmenty stają się wtedy „zbyt regularne” przypominjące prostokąty. W powyższym przypadku większa liczba superpikseli pozwoliła uchwycić detale oraz oddzielić twarz od szyi.
Stosując algorytm SLIC na całym obrazie RGB pozwalamy na niedokładności (np. związane z ujęciem szyi tak jak na 2 od prawej obrazku). Być może dobrym pomysłem było by ponowne ograniczenie obszaru poprzez landmarks_mask_with_extended_roi?
Zastanówmy się zatem, czy istnieje jeden najlepszy pipeline do wyznaczenia maski skóry twarzy (zwłaszcza przy użyciu super prostych, podstawowych, klasycznych metod)…..
Nie istnieje.
Możemy jednak sprawdzić jak średnio najlepiej stworzyć taką pipepline. Wyniki (metryki) na danych treningowych mogą podpowiedzieć, co dalej.
Przed chwilą widzieliśmy, że przy użyciu algorytmu slic (czyli funkcji segments_covered_by_mask ) wybrana maska daje bardzo dobre wyniki nawet na masce bazowej (landmarks_mask), czy więc morfologia jest nam potrzebna? Ile segmentów potrzebujemy w algorytmie SLIC?
Rozważmy dwa pomysły:
Pomysł 1
Pomysł nie uwzględnia wykrywania skóry za pomocą metod progowych.
- Wykryj twarz, wykryj maskę bazową (landmarks_mask).
- Użyj algorytmu SLIC do wykrycia kilku segmentów w obrazie RGB/ na masce landmarks_mask_with_extended_roi
- Jeśli segment pokrywa więcej niż 10% powierzchni landmarks_mask, oznacz segment jako maskę
- Ogranicz przy użyciu landmarks_mask_with_extended_roi
- Dodaj maskę bazową (landmarks_mask) jako maska, która musi być zawsze uwzględniona.
Hiperparametry, które chcemy sprawdzić: „kilku segmenty” (krok 2), „10%” (krok 3), „SLIC na obrazie RGB lub na fragmencie przykrytym przez landmarks_mask_with_extended_roi) (krok 2).
Pomysł 2
- Wykryj twarz, wykryj maskę bazową (landmarks_mask).
- Oblicz wartość średnią (treshold_mean) dla wybranego kanału (Cb) w YCrCb
- Wyznacz maskę skóry, która mieści się w zakresie [treshold_mean – treshold_sd, treshold_mean + treshold_sd].
- Ogranicz maskę wykrywania skóry z roi twarzy (landmarks_mask_with_extended_roi) .
- Zdecyduj, jak chcesz poprawić maskę:
5.a Użyj operacji zamknięcia morfologicznego. - Wykryj największy segment
- Użyj algorytmu SLIC do wykrycia segmentów (n_segments) w:
7.a ograniczonym obrazie przez wybraną maskę — Znajdź wypukły obszar maski (wykryty segment)
7.b na obrazie RGB - zdecyduj czy segment należy do maski (segment jest pokryty w ponad 50% przez maskę)
- Dodaj maskę bazową (landmarks_mask) jako podstawę.
- Ogranicz utworzoną maskę z roi twarzy (landmarks_mask_with_extended_roi)
Hiperparametry: „treshold_sd” (krok 3), „n_segments” (krok 7), „decyzja o znalezieniu wypukłego obszaru maski” (krok 7a), „SLIC na obrazie RGB lub na fragmencie przykrytym przez maske” (krok 7).
Ze względu na to, że etykieta „skóra twarzy” w zbiorze danych nie zawiera nosa/ust/brwi/oczu — usuń te elementy z wykrytej maski za pomocą punktów znaczących (landmarks).
Przypominam, że kod potrzebny do analizy znajdziecie w notebooku: SkinDetection/skinDetectionWithFaceLandmarks.ipynb. Analiza opierać się będzie na przebadaniu i wizualnym sprawdzeniu hiperparametrów. Tak by w zrozumieć działanie algorytmów w ogólnym znaczeniu. Trzy obrazki zostały wybrane: '10374318116_2′, '10004446093_3′, '10004446093_2′.
Zaprezentujmy „kombinację” dwóch masek: pierwszej stworzonej z landmarks_mask, a drugiej z poprawionej poprzez zastosowanie algorytmy opisane w pomyśle 1 lub 2.
Kolor czerwony na poniższych obrazkach oznacza miejsce, gdzie tylko landmarks_mask wskazało skórę. Delikatnie niebieskie — miejsce gdzie została wykryta poprawiona maska. Kolorem białym zaznaczono obszar zaetykietowany zarówno poprzez landmarks_mask jak i poprawioną maską.
Widzimy, że superpixele stworzone za pomocą SLIC lepiej dopasowują się do pewnych obszarów. Rozważając proste przykłady takie jak poniższe mniejsza liczba segmentów radzi sobie na tyle by móc wyraźnie odznaczyć interesujące nas obszary twarzy. Bazując na procentowym pokryciu pewnego segmentu poprzez ladmark_mask (patrz pomysł 1), ograniczamy możliwości w wyborze mniejszych superpixeli stworoznych w wyniku większej ich ilości. Mam na myśli, że jeśli ustawimy liczbę segmentów na dużą ilość (np. 200), obszar ladmark_mask nie ma możliwości pokryć niektórych superpixeli nawet w małym stopniu. Dla nas najlepiej jakby całe czoło zawierało się w jak najmniejszej ilości superpixeli.
Istnieją obszary, które przy małej ilości segmentów przynależą tylko do ladmark_mask (zaznaczone na czerwono).

Poniżej zastosowano identyczny algorytm, jednakże SLIC został wykonywany tylko na „przyciętym obrazku”. Od razu rzuca się w nam oczy obszar, na którym został wykonywany. Superpixele są bowiem nie dopasowane do obszaru kolorystycznego originalnego obrazka. Dokładniej — kontury superpixeli przypominają kształt prostokątów/wielokątów. W ogólnym rozrachunku efekt jest dużo, dużo gorszy.

Wiadomo, że hiperparametr mówiący o procentowym pokryciu superpiksela maską pierwotną będzie miał także duże znaczenie. Poniżej możemy przypatrzeć się sytuacji, gdy zastosujemy algorytm SLIC bezpośrednio na obrazek RGB. Nie powinno być zaskoczeniem, że zbyt niska procentowość pozwala „zaakceptować” zbyt duży obszar, gdzie zbyt wysoka, ogranicza maskę.
Widzimy, że w przypadku, gdy zbyt mały procent ma pokryć maskę, mamy sytuację, że cały obszar (ograniczony landmarks_mask_with_extended_roi) zostanie oznaczony jako maska. Zbyt wysoki % może spowodować, że niektóre superpiksele nie będą brane pod uwagę. W sytuacji kiedy zwiększyliśmy procent pokrycia do 30% lub 50%, widzimy, że dużą rolę odegrało sztuczne dodanie maski bazowej (kolor czerwony).
Algorytm z pierwszego pomysłu jest bardzo naiwny i jak widzimy działa bardzo dobrze tylko dla 1 posta. W przypadku drugiego i trzeciego linia włosów nie jest dokładnie wykrywana.
Wraz z doborem parametru odpowiadającego za procentowe pokrycie musimy rozważyć problem z doborem liczby segmentów.
Jeśli segmenty będą bardzo duże możemy wykrywać (większe) obszary/okolice obiektu, który chcemy wykryć. Wtedy mała procentowość na pewno się sprawdzi. Zbyt wysoka liczba segmentów – a co za tym idzie zbyt małe superpiksele nie sprawdzą się w zadaniu, w których będziemy chcieli wykrywać konkretne obszary.

W prezentowanych przykładach wyraźnie widać, że lepiej sprawdzi się podzielenie obrazków na 20 superpikseli i procentowym pokryciu 10 %. Jest to oczywiście przykład. Zachęcam do przestudiowania kilku innych obrazków i rozważaniu samemu – jakie zadanie chcemy realizować.

Poniżej zaprezentowane są rezultaty zaimplementowania pomysłu nr. 2. Kiedy obrazek został „przycięty”/ograniczony za pomocą maski skin_recognition_face_roi_convex okazuje się, że lepiej sprawdzą się mniejsza liczba segmentów. Wyraźnie widać, że we wszystkich algorytm SLIC działa poprawnie — na twarzy widać nie równe instancje superpikseli, gdzie tło stanową równomierne stworzone wielokąty. Bardzo ciekawie jest to zobrazowane przy liczbie segmentów równej 10. W ostatecznym rezultacie maska końcówkowa daje poprawne rezultaty tylko w przypadku liczby segmentów równej 5.

Powyższy przykład pokazywał, że superpiksele były zbyt często klasyfikowane jako maska. Oznacza to, że próg pozwalający klasyfikację był zbyt mały. W naszym przypadku parametrem wskazującym na próg jest procentowość pokrycia. Zwiększając tę wartość do 50 % możemy uzyskać bardziej stabilny rezultat! Poniżej wyraźnie widać, że tylko dla bardzo dużej liczbie segmentów (100, 200) algorytm działa znacząco inaczej. Znalezione maski (liczba segmentów = [5, 10, 20]) wydają się być dobrze dopasowane

Warto jednak graficznie porównać jeszcze powyższy rezultat z zastosowaniem tego samego algorytmu, tylko z możliwością tworzenia superpikseli na obrazie RGB. Oczywiście superpiksele dopasowują się w inne rejony obrazka. W przypadku środkowego obrazka idealnie wręcz potrafią wykryć podobne do siebie regiony. Dzieje się tak ponieważ jest zwiększony kontrast (białe koszule/czarne włosy). W ogólnym rozrachunku widzimy, że zwiększenie liczby superpikseli nie powoduje drastycznych zmian.

Z powyżej krótkiej (ale też przydługiej) analizy widzimy, że istnieją przykłady i taki dobór hiperparametrów, że dla jednego obrazka będzie lepiej się sprawdzał — a dla drugiego gorzej. Nie powinno być to zaskoczenie, w końcu rozważamy klasyczne metody analizy obrazów. Warto pomyśleć o preprocesingu, ujednolicić rozmiar obrazów itp.
Te dobre i te złe wyniki
Mam nadzieję, że powyżej zostały pokazane dobre i słabe strony każdego z pomysłów i implementacji. Czas zrobić eksperymenty na większą skalę, czyli przygotowanym wcześniej zbiorze. Dzięki temu jesteśmy w stanie określić ilościowo, która metoda będzie ogólnie lepsza. Czy to, że metoda działa średnio lepiej na wybranych 1000 obrazków oznacza, że będzie lepsza? Nie.
Sprawdźmy jak hiperparametry wpływają na wyniki. Będziemy pracować na zbiorze danych images_train. Używając metody przeszukiwania hiperparametrów grid search, sprawdźmy jak liczba segmentów wpływa na metryki. Więcej o metrykach można przeczytać w SkinDetection/skinDetection.ipynb.
Pełną implementację ponownie znajdziecie w SkinDetection/skinDetectionWithFaceLandmarks.ipynb. UWAGA, ponieważ nie została zastosowana żadna optymalizacja procesów, czas trwania przeszukiwania najlepszych hiperparametrów jest bardzo długi! Zachęcam do skorzystania z przygotowanych plików .csv, które zawierają obliczone metryki.
Rozważmy 1000 obrazków:
Przebadając:
liczbę segmentów = [5, 10, 20, 100, 200],
procentowe pokrycie obszaru ( razy 100) = [0.1, 0.3, 0.5, 0.7],
obraz, na którym wykonujemy algorytm SLIC = [„RGB”, „landmarks_mask_with_extended_roi”],
maska bazowa oznaczona jest przez = [„jaw and eyebrowns”])
# example results
results.tail(5)
Ponieważ używamy pakietu dlib, twarz czasami nie jest rozpoznawana (proszę przeczytać FaceLandmarks/faceLandmarks.ipynb i spojrzeć na 'Ops! Face has not been detected’ ValueError). W takim przypadku wykrywanie maski nie działa i metryka jest NaN.
Okazuje się, że na 91 zdjęciach twarz nie została wykryta – to bardzo dużo! Pokażmy kilka przykładów, w których proponowane rozwiązanie nie zadziała:

W większości algorytm nie był w stanie wykryć twarzy ponieważ nie jest ona w pozycji frontalnej (przypominam, że shape_predictor_68_face_landmarks.dat jest dedykowany głównie do twarzy skierowanej frontalnie) .
Gdybyśmy użyli biblioteki mediapipe, czyli opierającej się na DL, na niektórych fotografiach moglibyśmy wykryć twarz:

Widać jednak, że nie działa ona nadal perfekcyjnie! Czyli… działa lepiej niż metody klasyczne, jednakże jest jeszcze pole do popisu 🙂
Skupiając się tylko na poprawnie wykrytych twarzach z pomocą biblioteki dlib możemy kontynuować analizę sprawdzając metrykę IoU (Intersection over Union)
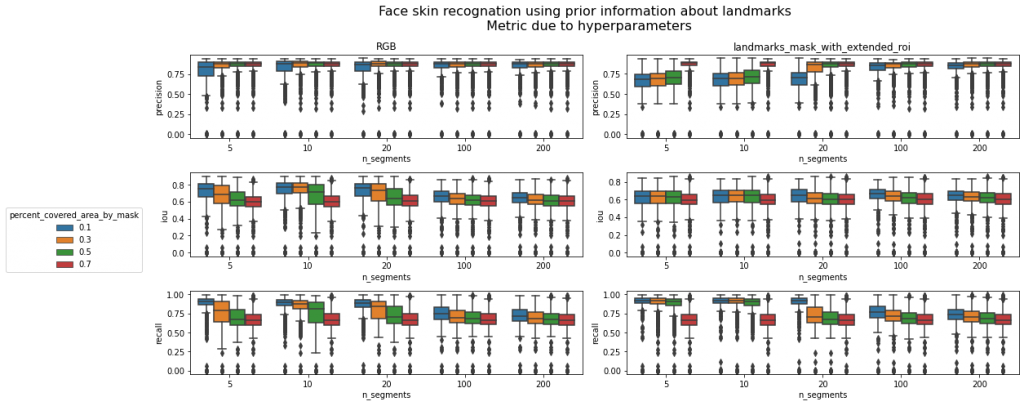
Jak pokazaliśmy wcześniej, metoda oparta na segmentacji SLIC wykadrowanego obrazu z landmarks_mask_with_extended_roi daje gorsze wyniki (niższe wartości precyzji i IoU). Pokrycie większego procentu obszaru segmentu zwiększa precyzję, co jest efektem naturalnym i bardzo łatwo zauważalnym. Jeśli jednak chcemy się skupić na metryce Iou, powinniśmy wybrać niższe wartości percent_covered_area_by_mask jak 10% Zwiększanie liczby segmentów zwiększa precyzję, ale generalnie znacznie obniża czułość, co z kolei ma tendencję do pogarszania wyniku. W zbiorze danych znajduje się wiele wartości odstających, więc wybór któregokolwiek z algorytmów jest nieco niewiarygodny dla całej przestrzeni obrazów.
Przypatrzmy się najgorszym wynikom ze względu na precyzje:

Jak widzicie… jest to przezabawny wynik 😀 na danym zdjęciu widniała więcej niż jedna postać. Pomimo, że adnotowana postać stanowi środek zdjęcia i skupia na sobie największą atencję człowieka — nie jest to oczywiste dla algorytmu, który wykrywa frontalną twarz.
Powiedzmy, że ten problem to temat rzeka, i może kiedyś powstanie kolejny tutorial jak sobie z nim poradzić, ale dziś po prostu go zignorujmy.
Przypatrzmy się twarzą, które zostały wykryte z najmniejszymi wartościami precyzji (pomijając te, gdzie precyzja równała się 0).

Zauważmy, że najgorsze przypadki są wykrywane przy użyciu hiperparametru landmarks_mask_with_extended_roi (landmark+extended), tylko jeden przypadek jest z ustawieniami slic_on = RGB, ale tam twarz nie została poprawnie wykryta. Od tej pory skupmy się więc tylko na zdjęciach, gdzie algorytm SLIC był wykonywany na całym obrazie, nie wykadrowanym/okrojonym.

Na 5 z powyższych zdjęć twarz nie została poprawnie wykryta. Niska precyzja obrazu 10013349094_0 wynika to głównie z bardzo dużej liczby segmentów. Przypominamy, że maska bazowa jest maską wykrywaną za pomocą punktów orientacyjnych dlatego czoło praktycznie nie mieści się w tym zakresie. Drugim aspektem wpływającym na niską precyzję dla jednych z trzech powyższych względnie poprawnie wykrytych twarzy są … okulary!
W tym miejscu warto zastanowić się czy można coś ulepszyć? Przykładowo maskę na zdjęciu 10015549094_1 można poprawić znanymi już operacjami jak znajdowanie krawędzi i wypukłego kształtu. Może warto dodać dodatkowy krok, jakim jest użycie funkcji convex_area?
Najlepsze wyniki (z punktu widzenia metryki precyzji) widoczne są na poniższym obrazku:

Wyniki są zadowalające!!! Jedyne, co można szybko poprawić lub zastanowić się, to czy ograniczenie landmarks_mask_with_extended_roi nie jest w tym przypadku zbyt małe. Ostra linia cięcia wyznaczona przez obszar jest wyraźnie widoczna w kilku przypadkach.
Rozważmy teraz metrykę „czułość”:
Najgorsze wyniki (pomijając te przypadki, gdzie precyzja równała się 0) prezentują się następująco:

Ponownie, głównym problemem jest nieprawidłowe wykrywanie twarzy!
Gdy przyglądniemy się za to przykładom, gdzie czułość osiąga najlepsze rezulaty:

gdy wykrywana twarz jest większa niż oryginalna, a my mamy mało segmentów i niskie pokrycie procentowe, większość segmentów zostanie włączona do ostatecznej maski. Dlatego obszar maski będzie ostatecznie znacznie większy niż rzeczywista etykieta.
Możemy to zobaczyć w poniższym przykładzie '11580694583_0′:

Śledząc wszystkie powyższe wyniki, możemy łatwo dojść do wniosku, że mniejsza liczba segmentów wydaje się być bardziej rozsądna, chyba że wraz ze wzrostem liczby segmentów rośnie procent pokrycia percent_covered_area_by_mask.
Oczywiście wszystkie metryki są bardzo ważne, ale gdybyśmy musieli wybrać najlepszy zestaw hiperparametrów do realizacji pierwszego pomysłu, powinniśmy skupić się na ten, który ma najwyższą średnią iou i najniższą wariancję. Jednak BARDZO ważne jest, aby mieć świadomość, że nie mamy rozkładu normalnego (długie ogony z powodu wielu wartości odstających).
Zobaczcie jak ładnie prezentują się maski dla przykładów, które osiągnęły najwyższe IoU:

Naprawdę… Trudno narzekać na takie wyniki przy tak prostym algorytmie! 🙂
Podobna jak poprzednio, wykonajmy eksperymenty dla zaimplementowanego drugiego pomysłu. Ponownie rozważmy 1000 różnych zdjęć i przebadajmy hiperparametry:
- liczba segmentów (segs) = [5, 10, 15, 20]
- próg koloru skóry – odchylenie (treshold_sds) = [0, 3, 10, 15, 20, 30]
- morfologia (morphologys) = [True, False]
- procentowe pokrycie maski (percent_covered_area_by_mask_grid_search) = [0.1, 0.3, 0.5, 0.7]
- obraz, na którym wykonujemy algorytm SLIC (slic_ons) = [„RGB”, „skin_recognition_face_roi_convex”]
- marked_bys = [„jaw and eyebrowns”]
- segments_covered_by_mask_types = [„skin_recognition_face_roi”]
Ponieważ mamy bardzooooo dużo kombinacji do rozważenia, popatrzmy na zestaw hiperparametrów, które używając wskazują jako najgorszą, i najlepsze wyniki. Gorąco polecam czytelnikowi głębszą analizę wyników w przygotowanym pliku .csv.
Popatrzmy na najlepsze kombinacje (ze względu na IoU):
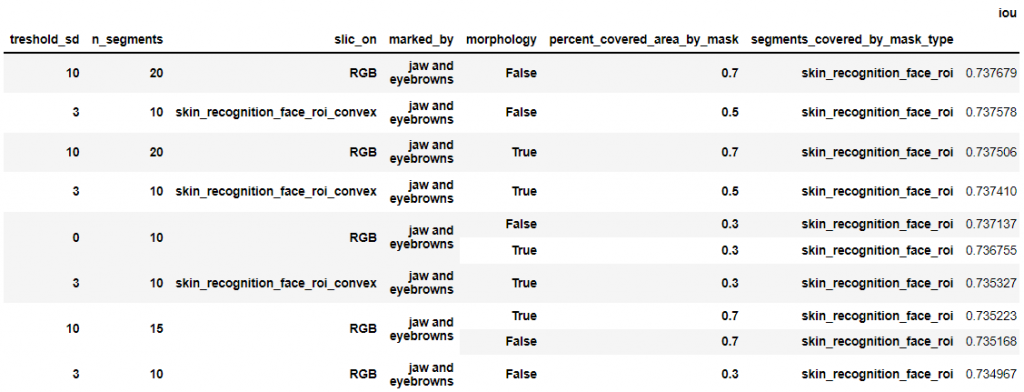
W zestawieniach top 10 należy zauważyć, że przede wszystkim występują modele o kombinacji {percent_covered_area_by_mask = 0.7 i treshold_sd = 10}. Ta kombinacja preferuje stosowanie algorytmu SLIC z większą liczbą segmentów {n_segmenty = 20 lub 15}. Wyraźnie wyróżnia się też kombinacja {n_segmentów = 10 i treshold_sd = 3}. Tutaj z kolei preferowana jest mniejsza {0.3, 0.5} wartość percent_covered_area_by_mask – co jest o tyle logiczne, że mamy też mniej segmentów. powyżej jest tylko 10 pozycji, ale gdyby ktoś był ciekawy, to w najlepszych 20 modelach {treshold_sd = 3} występuje… 13 razy!
Okkkeeeeeeejjjjj…. Tak naprawdę analizę można przeprowadzać w nieskończoność. Zachęcam do popatrzenia w notebook SkinDetection/skinDetectionWithFaceLandmarks.ipynb jest tam dużo więcej wizualizacji. A tak naprawdę to najbardziej zachęcam do własnej eksploracji danych i odpowiedzi na pytanie jakie są dobre i złe strony algorytmów/pomysłów? Jak można poprawić? Na jakie metryki tak naprawdę powinniśmy popatrzeć itd.
Porównując wyniki tworzonej maski po aplikacji kilu ulepszaczy i maski, gdy bierzemy pod uwagę tylko kolor skóry, możemy poczynić kilka obserwacji: Po pierwsze powiedzmy to głośno — użycie landmarków (punktów znaczących) bardzo poprawia wyniki….
Warto omówić jeszcze przykład 10374318116_2 gdzie precyzja jest bardzo wysoka, a IoU niskie:

Z powyższego przykładu widać, że czasami nie warto skracać sobie pracę próbując oddzielić skórę za pomocą cropped_img. Znacznie lepsze rezultaty uzyskamy z pomocą całego obrazu RGB. Jeszcze lepsze rezultaty uzyskamy, jeśli ostatecznie połączymy maskę landmarks_mask z poprawioną maską. Nie powinniśmy dopuścić do sytuacji, w której poprawiona maska jest mniejsza niż landmarks_mask. Zbyt mała liczba segmentów (tutaj 10) w algorytmie SLIC może spowodować, że część twarzy może zostać dołączona do innego segmentu. W tym przypadku segment zawierający usta jest połączony z szyją itd. Warto może też uwzględnić, że landmarks_mask to nie tylko maska konturów szczęki, ale także brwi i oczu?
Na początku zmieńmy funkcje odpowiedzialne za tworzenie masek z wykorzystaniem landmarków: face_mask_contours_with_eyebrowns rozpatruje kontury zawierające brwi.
Następnie zmieńmy funkcję, która odpowiada za poprawioną maskę. Poprawiona maska nie powinna być mniejsza od maski utworzonej z użyciem punktów znaczących twarzy. Możemy rozszerzyć/zmienić funkcję remove_selected_region tak, aby przyjmowała jeszcze jeden parametr mask_created_using_landmarks, lub możemy połączyć maski używając cv.bitwise_or().
Tym prostym (choć może zawile napisanym) sposobem możemy poprawić ostateczną maskę uzyskując następujący efekt:

Pomimo minimalnego zmniejszenia się precyzji — zwiększyliśmy wartość metryki IoU, pozyskując lepszy efekt.
OSTECZNIE zachęcam do podjęcia samodzielnie* decyzji, który algorytm wykrywania skóry twarzy daje najlepsze wyniki.
* albo skorzystania z podpowiedzi zawartych w notebooku i gotowej przykładowej implementacji.
Ostatni krok – wyznaczenie nowych punktów znaczących
Kod dotyczący tego rozdziału znajduje się w notebooku Triangulation/triangulationWithForehead.ipynb.
Za pomocą poznanych nam wcześniej algorytmom możemy wykryć maskę skóry (mask):

Z pomocą funkcji countour_mask potrafimy znaleźć największy (zewnętrzny) kontur maski — czyli obszaru, który będziemy chcieli „modyfikować” w procesie zamiany twarzy.
def countour_mask(mask):
contours, hierarchy = cv2.findContours(np.uint8(mask), 1, 2)
cnt = contours[0]
max_area = cv2.contourArea(cnt)
for contour in contours:
if cv2.contourArea(contour) > max_area:
cnt = contour[:,0]
max_area = cv2.contourArea(contour)
return cntNastępnie z pomocą funkcji find_n_points_in_countour jesteśmy w stanie wyznaczyć n punktów na odcinku. Odcinkiem w naszym przypadku będzie kontur (countour), zdefiniowany przez skórę twarzy.
BARDZO WAŻNE. countour zawiera zbiór punktów wyznaczających kontur — wcale nie oznacza to, że punkty są tak samo od siebie odległe; musimy pomyśleć, co jeśli kontur będzie łamaną (nie będzie gładki). Pozornie krótki odcinek może okazać się dla komputera nie równą linią. Warto zastanowić się więc jak chcemy wyznaczyć punkty: czy opierać miarę o równą odległość od siebie? A może po prostu podzielić zbiór punktów na n zbiorów? Może wyznaczyć jakiś kąt od pewnego punktu (np. nosa)? Ponownie znajduje się tu ogromne pole do popisu, a poniżej znajduje się zaproponowane dwa rozwiązania zależne od zmiennej perimeter.
def find_n_points_in_countour(countour, n: int = 10, perimeter = True):
n_points = []
if perimeter:
perimeter = ((np.diff(countour, axis = 0)**2).sum(axis = 1)**
(1/2)).sum()
diff_perimeter = ((np.diff(countour, axis = 0)**2).sum(
axis = 1)**(1/2)).cumsum()
for i in range(n):
n_points.append(max([-1, *np.where(
diff_perimeter < perimeter/n*i)[0]]) + 1)
else:
L = len(countour)
for i in range(n):
n_points.append(int(i*L/n))
return n_pointsEfekt znalezienia 5 punktów za pomocą funkcji find_n_points_in_countour, gdzie nie jest brana pod uwagę odległość między punktami (perimeter = False).

Efekt znalezienia 5 punktów za pomocą funkcji find_n_points_in_countour, gdzie jest brana pod uwagę odległość między punktami (perimeter = True).

Mogło by się wydawać, że nie ma aż takiej wielkiej różnicy ale to jest pozorny wniosek! Zwróć proszę uwagę co się stanie gdy zamiast całego konturu weźmiemy pod uwagę tylko fragment odpowiadający za czoło:

W sytuacji, gdy będziemy chcieli znaleźć 10 punktów w zależności od odległości (perimeter = True)…. zostanie zgubiony „czubek” czoła:

Gdzie przy braniu pod uwagę tylko n punktów (perimeter = False) efekt prezentuje się zdecydowanie lepiej:

Wracając do przykładu:

Możemy wyznaczyć „lepiej” punkty znaczące twarzy dwóch postaci. Stosując powyższe metody dodatkowo wyznaczamy punkty na linii brzegowej włosów. Tak by móc wyznaczyć cały obszar:

oraz:

Ostatecznie rezultat zamiany twarzy pomiędzy dwiema postaciami prezentuje się następująco:

Wydaje mi się, że efekt wyszedł naprawdę dobry! Uwzględniając, że użyte algorytmy powstały z klasycznych metod przetwarzania obrazu, oraz zaproponowane schematy nie odnoszą się tylko do tego powyższego przykładu, a można stosować je do wielu innych obrazów.
Poniżej jeszcze dwa przykłady:


PS Oczywiście, że do prezentacji zostały wybrane mniej problematyczne przypadki (gdy postacie są do siebie w miarę podobne/ jakość zdjęcia jest podobna).
Podsumowanie
CZAS NA PODSUMOWANIE!
Ten tutorial mógł się wydawać nieco dłuższy niż najczęściej spotykane w sieci. Ukazane zostały plusy i minusy klasycznych metod przetwarzania obrazu w zadaniu „zamiana twarzami dwóch postaci na zdjęciu”.
Plusem stosowania metod klasycznych jest przede wszystkim duże zrozumienie i kontrola nad tym co robimy. Często wiemy, dlaczego algorytm zadziałał tak a nie inaczej. Możemy w dowolny sposób manipulować obrazem dodając różne transformacje. Nawet proste metody (reguły) potrafią dać nam bardzo dobre wyniki!
Minusem – dużo dłuższy czas analizy (zwłaszcza z porównaniem gotowych już produktów, opartych na sieciach głębokich). Drugim bardzo ważnym minusem jest trudność w uśrednianiu wyników i tak naprawdę przebadanie głównie próbek treningowych, z brakiem możliwość generalizacji na większą skalę.
Dużym utrudnieniem jest też ewaluacja. Często do oceny ostatecznego wyniku nie używa się metryk „matematycznych”, a po ocenę wizualną obserwatora (anotatora).
Zachęcam do zadawania pytań, a przede wszystkim do samodzielnej pracy i próbie zrozumienia zaprezentowanych w tutorialu praktyk.
Link do GitHuba:
https://github.com/deepdrivepl/Face-Morph
Źródła
[1] Liu, Yinglu & Shi, Hailin & Shen, Hao & Si, Yue & Wang, Xiaobo & Mei, Tao. (2020). A New Dataset and Boundary-Attention Semantic Segmentation for Face Parsing. Proceedings of the AAAI Conference on Artificial Intelligence. 34. 11637-11644. 10.1609/aaai.v34i07.6832.
[2] https://learnopencv.com/warp-one-triangle-to-another-using-opencv-c-python
[3] Technology vector created by rawpixel.com – www.freepik.com
SLIC:
- https://docs.opencv.org/3.4/df/d6c/group__ximgproc__superpixel.html#ga0024d8bac96a9f0d49bd97665d76ae08
- https://scikit-image.org/docs/dev/api/skimage.segmentation.html#skimage.segmentation.slic
Zamiana palet kolorów:
https://docs.opencv.org/3.4/de/d25/imgproc_color_conversions.html
Przekształcenia morfologiczne:
https://docs.opencv.org/4.x/d9/d61/tutorial_py_morphological_ops.html
Dlib:
http://dlib.net/files/, http://dlib.net/python/index.html
https://github.com/davisking/dlib-models
MediaPipe:
https://google.github.io/mediapipe/solutions/face_mesh
Hog:



