Koronawirus, a co za tym idzie, maseczki, towarzyszą nam już od ponad roku. Dlatego chcę omówić sposoby budowania modeli, które pomogą nam wykryć, czy dana osoba ma założoną maseczkę i jeśli tak, czy prawidłowo. Jednak jeśli nie zamierzamy dokonywać detekcji w jednym kroku, musimy najpierw wykryć twarze osób znajdujących się na zdjęciu. To stawia nas przed kolejnym zagadnieniem: jaki detektor wybrać, żeby znalazł także twarze przesłonięte maseczką?
Dostępne zbiory danych
Jako że temat wykrywania maseczek cieszy się dość dużą popularnością, nietrudno znaleźć zbiory danych, na których będziemy móc trenować nasz model, a w tym poście – sprawdzać skuteczność detektorów. Mamy na przykład możliwość wyboru, czy chcemy rozróżniać między maseczką nałożoną prawidłowo a taką, która nie chroni tak, jak powinna. W tabelce poniżej możesz zobaczyć kilka różnych zbiorów i ich krótką charakterystykę.
| Zbiór | Ilość klas | Licencja | Charakterystyka |
| chandrikadeb7 | 2 | MIT | Zdjęcia wyciętych twarzy z maskami lub bez w dwóch folderach; maski są w różnych wzorach. |
| Face Mask Detection | 3 | CC0: Public Domain | Zdjęcia z wieloma twarzami oraz pliki z adnotacjami. |
| Face mask detector | 3 | CC0: Public Domain | Zdjęcia osób bez masek, na które są komputerowo nałożone maski dla drugiej klasy, a także zdjęcia niepoprawnie nałożonych masek. Część zdjęć jest ze znakiem wodnym bądź odwrócona. |
| Face Mask Lite Dataset | 2 | CC BY-SA 4.0 | Zdjęcia osób bez masek, na które są komputerowo nałożone maski dla drugiej klasy. |
| MaskedFace-Net | 2 | CC BY-NC 2.0 | Zdjęcia osób w wygenerowanych maskach prawidłowo lub nieprawidłowo nałożonych. |
Powyższe opisy zbiorów mogą budzić wątpliwości: co to za różnica, czy maski w klasie „z maską” są wygenerowane komputerowo, czy są oryginalną częścią zdjęcia? Takie rozwiązanie na pewno pomaga w zwiększeniu ilości danych, na których możemy wytrenować nasz model, jednakże użycie tylko wygenerowanych masek i niedodanie innych zdjęć bez maski do drugiej grupy może doprowadzić do przeuczenia. O tym problemie możesz przeczytać więcej tutaj.
Wybór detektora twarzy
Zanim przystąpimy do budowania modelu, musimy przygotować twarze, na których będziemy go trenować. Co prawda w przypadku zbioru Face Mask Detection położenie i klasa wszystkich twarzy są nam znane dzięki plikom z adnotacjami, jednak jeśli chcielibyśmy użyć Face mask detector, musielibyśmy najpierw je znaleźć. Ponadto, na zdjęciach dodanych przez użytkownika nie będziemy mieli oznaczonych twarzy – od naszego wyboru zależy, czy model zdoła je wykryć.
Co musimy w takim razie uwzględnić przy wyborze detektora i w jaki sposób sprawdzimy jego skuteczność? Zacznijmy najpierw od ustalenia, z jakimi problemami nasz model będzie musiał się prawdopodobnie zmierzyć.
- Najważniejsze: częściowe zakrycie twarzy. To w sumie oczywiste – jeśli nasz model nie wykryje twarzy w maseczkach bądź maseczek ubranych niepoprawnie, to na etapie trenowania utracimy pokaźną część danych. Dotyczy to także ludzi znajdujących się w tłumie – jedna osoba może przysłaniać drugą. Co równie ważne, jak nasz finalny model sprawdzi, czy dana osoba ma ubraną maseczkę, jeśli detektor nawet nie wykryje tej osoby na zdjęciu?
- Jak już częściowo wspominam w poprzednim podpunkcie: duża ilość osób na zdjęciu. Nie wiemy, co użytkownik będzie chciał sprawdzić – jedną osobę, a może grupę ludzi, którzy w swoim otoczeniu powinni zadbać o środki ostrożności?
- Duża ilość osób na zdjęciu prowadzi do kolejnego problemu: wielkość twarzy. Czy nasz detektor zdoła wykryć małe twarze, a może kalibracja na niewielkie obiekty sprawi, że polegnie przez to na dużych?
- Wykrywanie twarzy na przykład z profilu – niektóre detektory są przystosowane tylko do zdjęć en face i w przypadku pochylenia głowy czy częściowego odwrócenia się wykrywanej osoby zawodzą.
Ustalenie ground truth
Aby sprawdzić, jak wybrany detektor radzi sobie na różnych zdjęciach, użyję urozmaiconego zbioru z już gotowymi adnotacjami – tak, Face Mask Detection! Nie oznacza to, że od razu wybieram go do trenowania klasyfikatora – najpierw sprawdzę, który z dwóch wybranych zbiorów o trzech klasach jest lepszy. To jednak później, ponieważ i tak muszę najpierw znaleźć twarze w nieopisanym, do czego potrzebuję detektora.
Parsuję w tym celu przykładowe pliki z adnotacjami i sprawdzam, jakie twarze mogę w nich znaleźć.

Wybrałam dwa zdjęcia: jedno z aż 26 różnymi twarzami, a drugie – z jedną. Pierwsze z nich zawiera tłum, co daje nam wiele małych twarzy, a także możliwość testowania na przysłoniętych częściach, nie tylko przez maseczki. Co więcej, spora część z nich jest odwrócona bądź pochylona. W przypadku drugiego zdjęcia mamy dużą (w porównaniu z poprzednimi) twarz, która jednak jest odwrócona i przysłonięta maseczką. Tak różnorodny zbiór powinien nam dać dobry wgląd w skuteczność poszczególnych detektorów.
Bardzo małe twarze
Jak możemy zobaczyć, zdjęcia zdecydowanie różnią się między sobą ilością twarzy, a także ich rozmiarem. Dlatego sprawdzam, jak wygląda to w przypadku pozostałych zdjęć – rozmiar poszczególnych obrazków, ilość twarzy na każdym z nich, a także rozmiar tych twarzy – ich powierzchnię oraz zajmowaną część zdjęcia. Jednakże, podczas tej analizy zauważam, że niektóre z oznaczonych twarzy są naprawdę maleńkie – mają nawet poniżej 16 pikseli, zaś najmniejsza – jedynie dwa. Gdyby nie ogólny kontekst zdjęcia, nawet nie wiedzielibyśmy, że się tam znajdują. Dlatego też nie wliczam ich w ostateczną ilość twarzy do wykrycia, a tym bardziej do danych do potencjalnego trenowania. Sprawdzam jednak, na których zdjęciach się znajdują, żeby zobaczyć, w jakich przypadkach występuje problem. Czy to kwestia tłumu, gdzie wszystkie osoby są małe, czy może zdjęcia kilku osób z zaznaczonymi ludźmi w daleko w tle?

Jak widać, we wspomnianych przypadkach zaznaczenia bardzo małych twarzy nie jest to zwykle nagromadzenie wielu takich twarzy na zdjęciu z tłumem. Są to raczej osoby znajdujące się w tle, z ludźmi typowych rozmiarów na pierwszym planie.
Analiza zbioru
Jaka jest zatem liczba twarzy w zbiorze z wykluczeniem tych przypadków?
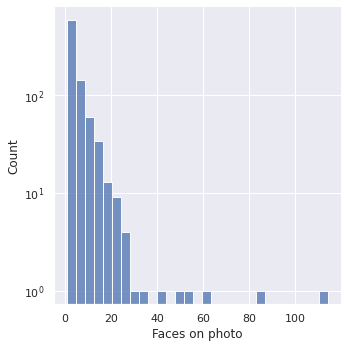
Na większości zdjęć możemy się zatem spodziewać paru osób, raczej do pięciu. Jednakże, co warto zauważyć, zdarzają się także przypadki pokaźnych tłumów – na jednym ze zdjęć możemy zobaczyć nawet 114 osób. Jest to także jedno ze zdjęć, na których znajduje się bardzo mała twarz.
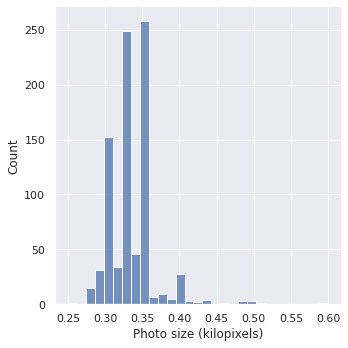
Jeśli chodzi o same zdjęcia, wszystkie są spore (o wymiarach większych niż 96×96 pikseli). Jednakże, żadno z nich nie wydaje się na tyle duże, by należało je specjalnie przeskalować przed użytkiem przez każdy model.
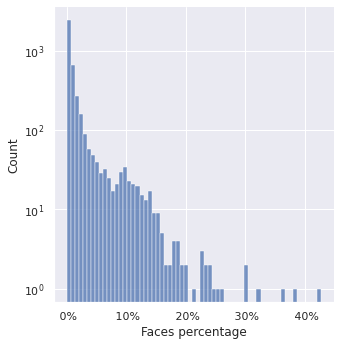
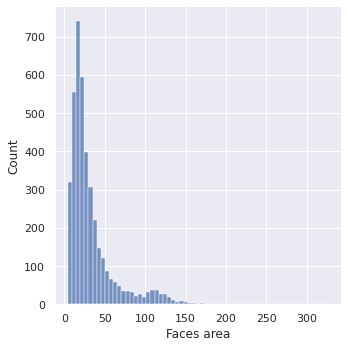
Te pokaźne rozmiary kończą się jedynie na samych zdjęciach. Jeśli zaś chodzi o twarze, niestety większość z nich jest dość mała. Niektóre, jak udało się już przekonać, niezwykle małe.
Sprawdzane detektory twarzy
Dla porównania wybrałam 12 różnych modeli, które sprawdzę na poszczególnych zdjęciach.
- Haar Cascades z OpenCV
- Moduł DNN OpenCV
- MTCNN
- Facenet pytorch
- Dlib Frontal face detector
- Dlib MMOD
- 3DDFA
- CrowdHuman
- RetinaFace
- CenterFace
- TinaFace
- PyramidBox
Dla każdego z nich przygotowuję prostą funkcję, którą będę wywoływać w pętli parsującej pliki z adnotacjami. W ten sposób porównam bounding boxes z pliku .xml z tymi wykrytymi przez poszczególne detektory. Zbiorę wyniki z uwzględnieniem wykrycia tylu, ile należy, niewykrycia wszystkich bądź możliwych false positives. Podzielę je na kategorie dla trzech różnych rozmiarów twarzy zgodnie z klasyfikacją COCO. Najpierw jednak zobaczę ich działanie na trzech przykładowych zdjęciach. To pozwoli mi ocenić możliwe problemy typowe dla danych modeli.

Jak możemy się po raz kolejny przekonać, dostępne adnotacje nie są idealne – na zdjęciu po prawej nie wszystkie twarze są zaznaczone. To znaczy, że potencjalne detektory o dużej skuteczności będą zwracały wysoką ilość false positives. Możemy więc uznać, że niewykrycie twarzy jest gorszym błędem. W świetle ostatecznego celu projektu i tak lepiej, żeby detektor zwracał false positives niż nie wykrywał twarzy.
Żeby porównać wyniki detekcji bezpośrednio na zdjęciach przykładowych, przygotowuję prostą funkcję, która będzie wykrywać twarze za pomocą wskazanej funkcji i odpowiedniego detektora, a potem je zaznaczać na podanym zdjęciu. Dzięki temu zobaczymy, których twarzy na przykładowych zdjęciach detektor nie wykrywa. Dowiemy się również, czy potencjalne false positives mogą być wynikiem niedoskonałych ground truths.
def detect_and_annotate(filename, model, foo, width_frame=1):
img = cv.imread(filename)
faces = foo(filename, model)
for (a, b, c, d) in faces:
cv.rectangle(img, (a, b), (c, d), (0, 0, 255), width_frame)
img = cv.cvtColor(img, cv.COLOR_BGR2RGB)
return img
Jako argument „foo” będę podawać funkcje, które z pomocą odpowiedniego modelu zwracają współrzędne rogów obrazu w formie: xmin, ymin, xmax, ymax w przypadku, gdy confidence score detektora przekracza 0.5.
Haar Cascades z OpenCV
Haar Cascades co prawda nie należy do najskuteczniejszych modeli, jednak jest szybki i zajmuje mało pamięci. Zanim użyjemy tego modelu, musimy najpierw ściągnąć odpowiedni plik, który pozwoli nam go wczytać.
haar_detector = cv.CascadeClassifier('models/haarcascade_frontalface_default.xml')
def normalize_haar_results(filename, detector):
img = cv.imread(filename)
img_gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
faces = detector.detectMultiScale(img_gray, scaleFactor = 1.2,
minNeighbors = 5)
faces = list(faces)
for face in faces:
face[2] += face[0]
face[3] += face[1]
return faces
Po samej nazwie modelu możemy się spodziewać, że będzie miał on problem z innymi ustawieniami twarzy niż en face. Sprawdzam, jak radzi sobie z wybranymi przeze mnie zdjęciami.

Rzeczywiście, model nie wykrywa większości twarzy. Widzimy też, że nie udało mu się uchwycić żadnej osoby w maseczce. Prawopodobnie używając go to detekcji stracilibyśmy dużo danych zwłaszcza z tej kategorii. Niestety, bardzo dużo ludzi bez maseczki również nie zostało wykrytych, co dodatkowo zmniejsza ilość danych. Twarze, które znalazł, zwykle są skierowane w stronę kamery.
Moduł DNN z OpenCv
Tym razem użyję detektora z modułu dnn OpenCV. Jest on bardziej dokładny niż jego poprzednik, ale dalej bardzo szybki. W tym przypadku używam pretrenowanego caffemodelu oraz pliku .protoxt określającego architekturę modelu.
Piszę także funkcję, która zwróci mi współrzędne wszystkich twarzy, których confidence score jest wystarczająco wysoki.
dnn_detector = cv.dnn.readNetFromCaffe("models/deploy.prototxt.txt",
"models/res10_300x300_ssd_iter_140000.caffemodel")
def normalize_dnn_results(filename, model):
img = cv.imread(filename)
faces = []
h, w = img.shape[:2]
blob = cv.dnn.blobFromImage(cv.resize(img, (300, 300)),
1.0, (300, 300),
(104.0, 117.0, 123.0))
model.setInput(blob)
detected = model.forward()
for j in range(detected.shape[2]):
confidence = detected[0, 0, j, 2]
if confidence > 0.5:
box = detected[0, 0, j, 3:7] * np.array([w, h, w, h])
coords = box.astype("int")
faces.append(coords)
return faces
detekcja twarzy
DNN znajduje zdecydowanie więcej niż poprzedni model. Co ciekawe, mimo że nie zdołał wykryć twarzy w maseczkach na zdjęciu drugim, daje sobie z takimi radę na ostatnim testowanym zdjęciu. Rozpoznaje także twarze obrócone w bok, z czym Haar sobie nie poradził.
MTCNN
Multi Task Cascaded Neural Network nie tylko znajduje twarz, ale wykrywa także punkty charakterystyczne. Być może dlatego będzie skuteczny do detekcji maseczek za pomocą wykrywania nosa czy ust.
from mtcnn.mtcnn import MTCNN
mtcnn_detector = MTCNN()
def normalize_mtcnn_results(filename, model):
img = cv.imread(filename)
faces = []
boxes = model.detect_faces(img)
for box in boxes:
bdbox = box.get('box')
normalized_box = [bdbox[0], bdbox[1], bdbox[0]+bdbox[2], bdbox[1]+bdbox[3]]
faces.append(normalized_box)
return faces

Po raz kolejny możemy zaobserwować znaczną poprawę w liczbie wykrytych twarzy na dwóch ostatnich zdjęciach. Co ciekawe, detektor dalej nie wykrywa jednej z osób na zdjęciu drugim, a znajduje niektóre małe, przysłonięte twarze na trzecim.
Facenet pytorch
Kolejny model MTCNN jest także zaimplementowany przy pomocy pytorcha. Instalacja jest prosta, pretranowany model można zainstalować za pomocą pipa. Dodatkowo autorzy notują znacznie lepszą szybkość niż w przypadku paczki MTCNN.
from facenet_pytorch import MTCNN
import torch
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
def normalize_facenet_results(filename, model):
img = cv.imread(filename)
faces = []
boxes, probs = model.detect(img)
i = 0
if boxes is not None:
for box in boxes:
if probs[i] > 0.5:
faces.append([int(coord) for coord in box])
i += 1
return faces

Model wykrył dokładnie tyle samo twarzy, co jego uprzednia implementacja. Dlatego też wyniki możemy porównać dopiero na całym zbiorze.
Dlib frontal face detector
W porównaniu uwzględniam także model przeznaczony – tak jak Haar Cascades z OpenCV – głównie do twarzy zwróconych en face. Jednak dlib dodatkowo umożliwia wykrywanie punktów charakterystycznych twarzy, co może być jednym ze sposobów na wykrywanie samej pozycji maseczki. W następnym wpisie planuję porównać skuteczność dliba i mtcnna w tym zakresie.
Co jest istotne przy używaniu tego detektora:
- musimy sami najpierw przerzucić obraz do skali szarości – w przeciwieństwie do poprzednich modeli, ten nie robi tego sam. Mimo tego, że detektor działa i bez niej, raczej lepiej to zrobić ze względu na kolejną rzecz:
- ustalamy, jak bardzo detektor powinien przeskalować obrazek wejściowy. Ponieważ model był trenowany na twarzach o wymiarach 80×80, może mieć problem z wykryciem mniejszych.
Z dwóch powyższych powodów powinniśmy zastanowić się, jak chcemy go używać. Jeśli chcielibyśmy przeprowadzić detekcję przy użyciu wszystkich trzech kanałów kolorów, wtedy musimy spodziewać się obniżonej wydajności. Przed użyciem modelu nie będziemy wiedzieć, ile będzie twarzy, więc nie ustawimy kalibracji. Musimy zatem zadowolić się ustalonymi parametrami. Dlatego też zobaczę, jak dobór skalowania wpływa na wyniki. W pierwszym przypadku (i pierwszym rzędzie) zostawię oryginalne rozmiary, w drugim powiększę dwukrotnie, a ostatnim – czterokrotnie. Ponieważ jako funkcję do detekcji będę używać modelu z ustalonym hiperparametrem, piszę osobną funkcję dla tego modelu z modyfikowalną skalą, oprócz funkcji normalizującej wyniki.
def hog_annotate(img_path, model, scale=2):
image = cv.imread(img_path)
faces = model(image, scale)
for face in faces:
cv.rectangle(image, (face.left(), face.top()), (face.right(), face.bottom()), (0, 0, 255), 1)
image = cv.cvtColor(image, cv.COLOR_BGR2RGB)
return image

Skalibrowane modele przynoszą w przypadku dwóch pierwszych zdjęć takie same rezultaty, jeśli chodzi o ilość, jak i położenie. Jednak na zdjęciu z mniejszymi twarzami można zaobserwować wpływ doboru skalowania. Mimo tego, że w żadnym przypadku wyniki nie są wyjątkowo dobre, dla przeskalowania o 2 wykrytych twarzy jest najwięcej. Dodatkowo, czterokrotne powiększenie zwraca wynik fałszywy (zaznaczone ucho jednej z osób po lewej stronie zdjęcia, lecz twarz nie). Dlatego też użyję detektora z parametrem 2 podczas porównywania do innych modeli.
import dlib
hog_detector = dlib.get_frontal_face_detector()
def normalize_hog_results(filename, model):
img = cv.imread(filename)
faces = []
boxes = model(img, 2)
for box in boxes:
faces.append([box.left(), box.top(), box.right(), box.bottom()])
return faces
Dlib MMOD
Dlib oferuje także model wykorzystujący sieci konwolucyjne. Sprawdzę, czy jego użycie da nam lepsze rezultaty.
import dlib
mmod_detector = dlib.cnn_face_detection_model_v1("models/mmod_human_face_detector.dat")
def normalize_mmod_results(filename, model):
img = cv.imread(filename)
faces = []
boxes = model(img)
for box in boxes:
face = box.rect
faces.append([face.left(), face.top(), face.right(), face.bottom()])
return faces
Ponieważ w przeciwieństwie do poprzedniego detektora model może służyć do wykrywania twarzy widocznych nie tylko od frontu, powinniśmy oczekiwać lepszych wyników. Zobaczmy, czy tak jest istotnie.

Rzeczywiście, model wykrywa znacznie więcej twarzy. Niestety, jest za to znacznie wolniejszy. Co ciekawe, w przypadku zdjęcia trzeciego znajduje większość tych niewielkich twarzy, znajdujących się na drugim planie, nawet jeśli są one częściowo przysłonięte, natomiast w przypadku tych większych, nie znajduje części z nich. Detektor poradził sobie z problemem odrobinę lepiej niż MTCNN.
3DDFA
Aby użyć tego detektora, klonuję repozytorium projektu. Wszystkie kroki konfiguracji są opisane w pliku demo, przez co obsługa jest zdecydowanie prostsza. Trzeba jednak pamiętać, że w przypadku uruchamiania modelu poza folderem projektu, musimy zmienić w kilku przypadkach formy importu – część importów jest absolutna, co nie zadziała. Ponadto, musimy użyć paczki importlib – submoduł nazywa się 3DDFA, co uniemożliwia najprostszą formę importu.

Żaden z poprzednich detektorów nie poradził sobie tak dobrze. Ten model nie tylko wykrył wszystkie twarze na środkowym zdjęciu, lecz także znalazł więcej na ostatnim.
Po skonfigurowaniu modelu użytkowanie jest naprawdę proste:
def normalize_3ddfa_results(filename, model):
img = cv.imread(filename)
boxes = model(img)
faces = []
for box in boxes:
if box[4] > 0.5:
faces.append((int(box[0]), int(box[1]), int(box[2]), int(box[3])))
return faces
Ten model jest dodatkowo interesujący, ponieważ jego głównym zadaniem jest tak naprawdę rekonstrukcja twarzy i estymacja pozycji głowy. Zobaczmy, jak wyglądają wyniki pierwszych kroków:



Widzimy, że model odtworzył punkty charakterystyczne także osób z nałożoną maseczką czy zasłoniętych w tłumie. W przypadku osoby w dole zdjęcia nawet rekonstruował twarz, która ma widoczną tylko część oka.
CrowdHuman
Jest to implementacja YOLOv4 służąca do wykrywania ludzi i ich głów. W tym przypadku skorzystam tylko z części z głowami. W tym celu będę używać kodu z tego repozytorium. Ponieważ YOLOv4 zbudowane jest na darknecie, po więcej wskazówek, jak go zbudować, możesz zerknąć do naszego posta na ten temat.
Po wytrenowaniu modelu sprawdzam, jak radzi sobie na wybranych zdjęciach:
%%bash
cd yolov4_crowdhuman/darknet
./darknet detector test data/crowdhuman-608x608.data \
cfg/yolov4-crowdhuman-608x608.cfg \
backup/yolov4-crowdhuman-608x608_best.weights \
-dont_show -ext_output < ../../dataset/trial/ground_truths.txt > ../../dataset/trial/ground_result.txt \
-out ../../dataset/trial/ground_result.json \
-gpus 0
Nazwy moich zdjęć testowych zapisałam w pliku filenames.txt dla łatwiejszego użytku. Wyniki zapisuję do jsona, żeby potem je wczytać i zaznaczyć na zdjęciach. Podczas porównywania z innymi modelami zrobię to samo, tylko na całym zbiorze i z wczytaniem jedynie liczby i położenia twarzy na poszczególnych zdjęciach.

Wyniki tego modelu są konkurencyjne dla poprzedniego. Co prawda nie wykrył kilku małych twarzy, które znalazł 3DDFA, ale inne, nieznalezione przez 3DDFA – tak. W przypadku odrobinę większej, zamaskowanej twarzy nie miał żadnego problemu. Jednak obszary zaznaczane przez niego są zdecydowanie większe niż w przypadku innych modeli. Może to skutkować niewystarczająco dużym IoU dla mniejszych twarzy, a co za tym idzie – zwiększoną ilością false positives.
Retina Face
W literaturze dotyczącej problemu detekcji twarzy jako jedno z najlepszych dotychczasowych rozwiązań podawana jest RetinaFace. Co więcej, jako przykład jej użycia bardzo często pokazywane jest World’s Largest Selfie. Co to oznacza dla nas? Model powinien dawać dobre wyniki nawet przy małych, zasłoniętych twarzach, czego potrzebujemy. Co więcej, model jest dostępny w paczce insightface, dzięki czemu użycie go nie powinno sprawiać kłopotów.
import mxnet as mx
import insightface
retina_detector = insightface.model_zoo.get_model('retinaface_r50_v1')
retina_detector.prepare(ctx_id = -1, nms=0.4)
def normalize_retina_results(filename, model):
img = cv.imread(filename)
bbox, landmark = model.detect(img, threshold=0.5, scale=1.0)
return bbox
Model ma wbudowane sprawdzanie confidence score, więc nie musimy się martwić filtrowaniem wyników.

Na pierwszy rzut oka wydaje się, że RetinaFace daje nam najlepsze wyniki. Jednakże, po zerknięciu na wizualizację ground truth widzimy, że część rezultatów musi zostać uznana za false positives, chociaż te twarze faktycznie się tam znajdują. Będziemy musieli o tym pamiętać podczas analizy wyników porównania modeli.
CenterFace
Podawany jako przynoszący nieco gorsze efekty, jednak dalej będący w czołówce najlepszych modeli, jest CenterFace. On również jest prezentowany na World’s Largest Selfie, więc warto zobaczyć jego wyniki. Zarówno kod źródłowy, jak i modele znajdują się w tym repozytorium. W celu użycia go na całym zbiorze modyfikuję odrobinę funkcję podaną w demo.py. Podobnie jak w przypadku CrowdHuman podaję plik z nazwami zdjęć jako argument. Wyniki z prawdopodobieństwem większym niż 0.5 zapisuję do jsona, z którego potem je wczytam do adnotacji, jak i walidacji wyników.

Faktycznie, model wykrył mniej twarzy niż Retina, jednak ta ilość nadal jest całkiem spora. Jest lepszy niż pozostałe wcześniejsze detektory.
TinaFace
Ten model uznawany jest za state of the art w dziedzinie detekcji twarzy na chwilę obecną. Podobnie jak w przypadku CenterFace, kod i opis metody znajduje się na Githubie. Autorzy repozytorium także udostępniają link do pretrenowanych wag oraz prezentują przykładowy kod do inferencji. Odrobinę zmieniam funkcje, żeby znowu móc przeprowadzić detekcję na całym zbiorze.

Ten model rzeczywiście wykrył wszystkie twarze, nawet te bardzo małe i zakryte przez inne osoby. Tak jak w przypadku Retina Face, część z nich zostanie uznana za false positives ze względu na to, że ground truth nie obejmują wszystkich. W celu sprawdzenia, który jest lepszy – Tina czy Retina – musimy porównać wyniki na całym zbiorze.
PyramidBox
Co prawda wygląda na to, że znaleźliśmy już model idealny dla naszych potrzeb, jednak sprawdzam jeszcze model z PaddlePaddle – PyramidBox (też czołówka rankingów). On również dostępny jest w formie paczki instalowalnej za pomocą pipa.
import paddlehub as hub
pyramidbox_detector = hub.Module(name="pyramidbox_lite_server")
def normalize_pyramidbox_results(filename, model):
img = cv.imread(filename)
faces = []
result = model.face_detection(images=[img])
for face in result[0]["data"]:
if face["confidence"] > 0.5:
xmin = face["left"]
xmax = face["right"]
ymin = face["top"]
ymax = face["bottom"]
faces.append((xmin, ymin, xmax, ymax))
return faces
Model zwraca takie wyniki:

Jak widać, PyramidBox nie znajduje aż tylu twarzy, jednak dalej radzi sobie bardzo dobrze. Model wykrył kilka twarzy, które nie znajdują się w plikach z adnotacjami, a pominął tylko jedną.
Wyniki
Sprawdzam, jak się ma liczba faktycznych twarzy na zdjęciu do liczb sugerowanych przez detektory. Dzielę wyniki w zależności od wielkości twarzy – dzięki temu dowiem się, jak rozmiar wpływa na rezultaty detekcji.
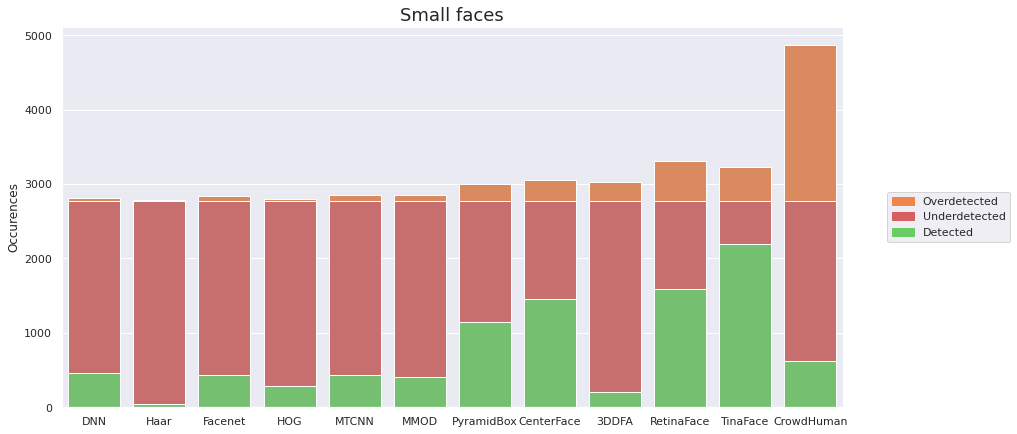
Większość detektorów zawodzi w przypadku małych twarzy i wykrywa mniej niż połowę z nich. Trzy z nich dały radę wykryć więcej: CenterFace, RetinaFace i TinaFace, z wyraźną przewagą tego ostatniego.
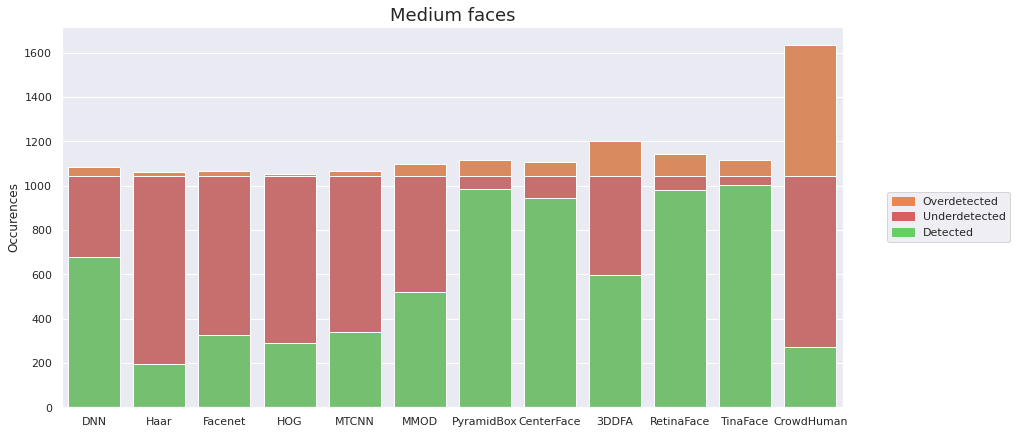
Wraz z rozmiarem twarzy wzrasta znacznie liczba detekcji. CenterFace zostaje wyprzedzony przez PyramidBox, jednak dwa najlepsze detektory pozostają niezmienne.
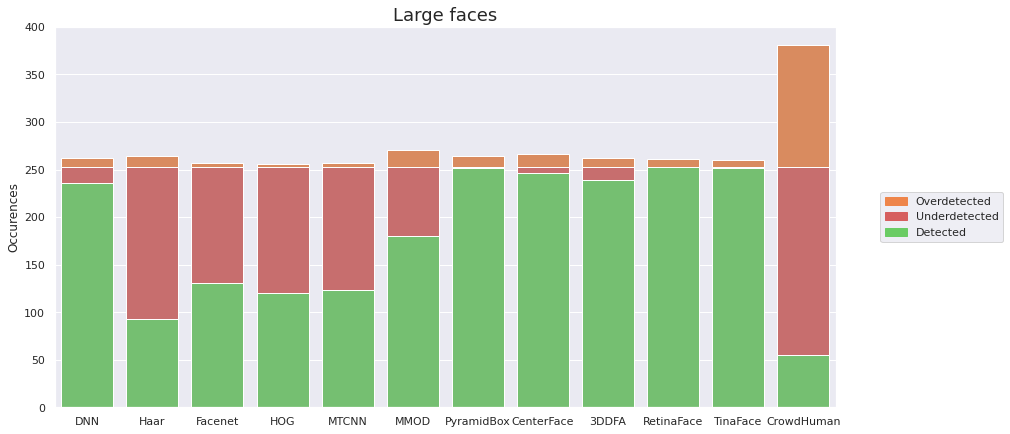
Wygląda na to, że TinaFace istotnie jest bezkonkurencyjny. Produkuje stosunkowo mało false positives (w przeciwieństwie do CrowdHuman). Możemy więc założyć, że spora część z nich to twarze niezaznaczone w zbiorze, które faktycznie znajdują się na zdjęciu. Ponadto, w przypadku każdego rozmiaru twarzy to ten detektor wykrył najwięcej twarzy prawidłowo, a dla małych twarzy różnica między nim a pozostałymi modelami jest rzędu kilkuset twarzy.
Chcę także zobaczyć, dla jakich zdjęć precyzja i czułość na przestrzeni wszystkich modeli były najwyższe i najniższe. W ten sposób dowiemy się, z jakim zdjęciem dekektory poradziły sobie najlepiej, a z jakim najgorzej.
Najłatwiejsze zdjęcie

W przypadku jednej twarzy, skierowanej w stronę aparatu, w pełni niezasłoniętej, wszystkie modele, jak można było oczekiwać, wykryły ją.
Najtrudniejsze zdjęcie

Zdjęcie, na którym modele miały największe kłopoty z detekcją, również zawiera tylko jedną twarz. Jednak dużym utrudnieniem jest fakt, że osoba widoczna na zdjęciu jest odwrócona z profilu i ma nałożoną maseczkę. To sprawiło, że 5 z 12 detektorów nie zdołało wykryć twarzy.
Zdjęcia o średniej ilości twarzy
Głównie przeanalizowane zdjęcia do tej pory zawierały jedną twarz bądź tłum. Przyjrzyjmy się dwóm zdjęciom zawierającym sześć i osiem twarzy.

Połowa detektorów zdołała wykryć wszystkie twarze znajdujące się na zdjęciu. Co warto zauważyć, CrowdHuman znalazł dodatkowo tył głowy jednego dziecka. Do wykrywania maseczek jednak sam tył głowy się nie przyda, więc nie jest to coś, co możemy wykorzystać.

W przypadku drugiego zdjęcia mamy do czynienia z jedną, główną twarzą i kilkoma mniejszymi w tle. Taka konfiguracja sprawiła, że detektory uprzednio radzące sobie całkiem nieźle z małymi twarzami zawiodły. Ich wyniki są porównywalne z modelami, które już wcześniej miały kłopoty z małymi twarzami. Wyjątkiem są TinaFace i CrowdHuman. Jeśli zaś chodzi o porównanie modeli MTCNN i Faceneta, tym razem Facenet wykrył o jedną twarz więcej niż model dostępny w drugiej paczce.
Podsumowanie
Po sprawdzeniu działania dwunastu detektorów na zbiorze do wykrywania maseczek okazuje się, że do problemu najlepiej nadaje się TinaFace. W kolejnym wpisie w tym temacie planuję go wykorzystać do wykrywania twarzy, które następnie zostaną poddane klasyfikacji, czy jest na nich maseczka, a jeśli tak – czy dobrze nałożona. W serii chcę jeszcze zawrzeć następujące elementy:
Całość kodu dostępna jest na GitHubie.