Pierwszą część, dotyczącą segmentacji instancji, możesz przeczytać tutaj:
Ten post dotyczyć będzie wykorzystania modelu DETR do wykrywania obiektów i jest on kontynuacją wpisu dotyczącego segmentacji instancji. Gorąco zachęcam Cię do przeczytania części pierwszej. Jeśli natomiast interesuje Cię tylko wykrywanie, postaram się wyjaśnić tutaj wszystkie najpotrzebniejsze rzeczy tak, aby były dla Ciebie zrozumiałe. Jeśli jesteś już po lekturze części pierwszej, możesz od razu przeskoczyć do kodu.
Model DETR
DETR (czyli DEtection TRansformer) to model opublikowany przez zespół facebook-research, którego głównym przeznaczeniem jest zadanie wykrywania obiektów, czyli ich lokalizacja i klasyfikacja. Przez lokalizację, mam na myśli podanie położenia z wykorzystaniem bounding-boxów. Pierwszy post z serii mówił o segmentacji instancji, które powstało niejako jako skutek uboczny wykrywania obiektów. Teraz chciałabym przybliżyć Ci właśnie wykrywanie. Co takiego wyjątkowego jest w tym modelu? Wykorzystuje on specjalną funkcję kosztu, dzięki której jest zniechęcany do tworzenia duplikatów. Wymaga także podania wprost liczby obiektów, które chcemy wykryć na zdjęciu. Przykładowo, jeśli podamy 100 obiektów, a na obrazie mamy ich jedynie 50, to pozostałe 50 zostanie zaklasyfikowane jako no object.
Na czym polega nasze zadanie?
W tym poście chciałabym Ci pokazać, do czego ja wykorzystałam DETR i na przykładzie swojego kodu przedstawić krok po kroku jak wykonać inferencję z jego wykorzystaniem. Efekt końcowy możesz zobaczyć na poniższym filmie. Do tego dążymy!
Wejściem naszego modelu jest film, który możesz znaleźć tutaj. Wykonujemy na nim inferencję klatka po klatce, rysujemy bounding-boxy i etykiety klas wraz z dodatkowymi informacjami takimi jak: nazwa modelu, threshold, rozmiar wejścia, karta graficzna oraz czas inferencji. Każdy wynik zapisujemy do katalogu – dzięki temu i wykorzystaniu ffmpeg możemy otrzymać wyjście pod postacią filmu.
Kod do powyższego zadania powstał w oparciu o notebook opublikowany przez autorów modelu. Tutaj udostępniam plik w colabie, w którym możesz pracować na bieżąco. Tym razem zajmiemy się samymi obiektami, ale jeśli ciekawi cię, w jaki sposób zwizualizować mapy aktywacji modelu, a ominął Cię pierwszy post z serii, zachęcam do zajrzenia i tam.
Importy
Tym razem jest ich zdecydowanie mniej niż w przypadku segmentacji instancji, w której wykorzystywalismy dużo dodatkowych paczek takich jak detectron2, czy pycocotools. Wystarczy nam zaledwie kilka pakietów.
import time
import os
import os.path
import torch
import torchvision.transforms as T
import cv2
import matplotlib.pyplot as plt
import PIL.ImageColor as ImageColor
from tqdm import tqdm
Model
Zanim wczytamy model z wykorzystaniem torch.hub, sprawdźmy wszystkie dostępne w facebookresearch/detr modele.
torch.hub.list('facebookresearch/detr')
Powyższa linia sprawi, że wyświetli nam się taka oto lista:
['Backbone',
'DETR',
'DETRsegm',
'Joiner',
'PositionEmbeddingSine',
'PostProcess',
'PostProcessPanoptic',
'Transformer',
'detr_resnet101',
'detr_resnet101_dc5',
'detr_resnet101_panoptic',
'detr_resnet50',
'detr_resnet50_dc5',
'detr_resnet50_dc5_panoptic',
'detr_resnet50_panoptic']
W przypadku wykrywania obiektów mamy zatem do wyboru 4 modele – każdy z nich ma inny backbone. Ja wybrałam 'detr_resnet101_dc5′, ale z powodzeniem możesz wybrać któryś z trzech pozostałych: 'detr_resnet101′, 'detr_resnet50′, 'detr_resnet50_dc5′.
Jeśli zdecydowaliśmy się na którąś z opcji, możemy nasz model wczytać, przenieść w tryb ewaluacji i przenieść na kartę graficzną.
detr_model_name = 'detr_resnet101_dc5'
model = torch.hub.load('facebookresearch/detr', detr_model_name, pretrained=True)
model.eval()
model = model.cuda()
Funkcje pomocnicze
Definiuję standardowe przekształcenie w PyTorchu, które wykona normalizację oraz przekonwertuje nasze zdjęcie z np.array na torch.Tensor.
# standard PyTorch mean-std input image normalization
transform = T.Compose([
T.ToTensor(),
T.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
Następnie definiuję listę klas oraz paletę barw, która pozwoli nam na wizualizację każdej z klas w innym kolorze.
# coco classes
CLASSES = [
'N/A', 'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus',
'train', 'truck', 'boat', 'traffic light', 'fire hydrant', 'N/A',
'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse',
'sheep', 'cow', 'elephant', 'bear', 'zebra', 'giraffe', 'N/A', 'backpack',
'umbrella', 'N/A', 'N/A', 'handbag', 'tie', 'suitcase', 'frisbee', 'skis',
'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove',
'skateboard', 'surfboard', 'tennis racket', 'bottle', 'N/A', 'wine glass',
'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple', 'sandwich',
'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake',
'chair', 'couch', 'potted plant', 'bed', 'N/A', 'dining table', 'N/A',
'N/A', 'toilet', 'N/A', 'tv', 'laptop', 'mouse', 'remote', 'keyboard',
'cell phone', 'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'N/A',
'book', 'clock', 'vase', 'scissors', 'teddy bear', 'hair drier',
'tootorchbrush'
]
# colors for visualization
STANDARD_COLORS = [
'AliceBlue', 'Chartreuse', 'Aqua', 'Aquamarine', 'Azure', 'Beige', 'Bisque',
'BlanchedAlmond', 'BlueViolet', 'BurlyWood', 'CadetBlue', 'AntiqueWhite',
'Chocolate', 'Coral', 'CornflowerBlue', 'Cornsilk', 'Crimson', 'Cyan',
'DarkCyan', 'DarkGoldenRod', 'DarkGrey', 'DarkKhaki', 'DarkOrange',
'DarkOrchid', 'DarkSalmon', 'DarkSeaGreen', 'DarkTurquoise', 'DarkViolet',
'DeepPink', 'DeepSkyBlue', 'DodgerBlue', 'FireBrick', 'FloralWhite',
'ForestGreen', 'Fuchsia', 'Gainsboro', 'GhostWhite', 'Gold', 'GoldenRod',
'Salmon', 'Tan', 'HoneyDew', 'HotPink', 'IndianRed', 'Ivory', 'Khaki',
'Lavender', 'LavenderBlush', 'LawnGreen', 'LemonChiffon', 'LightBlue',
'LightCoral', 'LightCyan', 'LightGoldenRodYellow', 'LightGray', 'LightGrey',
'LightGreen', 'LightPink', 'LightSalmon', 'LightSeaGreen', 'LightSkyBlue',
'LightSlateGray', 'LightSlateGrey', 'LightSteelBlue', 'LightYellow', 'Lime',
'LimeGreen', 'Linen', 'Magenta', 'MediumAquaMarine', 'MediumOrchid',
'MediumPurple', 'MediumSeaGreen', 'MediumSlateBlue', 'MediumSpringGreen',
'MediumTurquoise', 'MediumVioletRed', 'MintCream', 'MistyRose', 'Moccasin',
'NavajoWhite', 'OldLace', 'Olive', 'OliveDrab', 'Orange', 'OrangeRed',
'Orchid', 'PaleGoldenRod', 'PaleGreen', 'PaleTurquoise', 'PaleVioletRed',
'PapayaWhip', 'PeachPuff', 'Peru', 'Pink', 'Plum', 'PowderBlue', 'Purple',
'Red', 'RosyBrown', 'RoyalBlue', 'SaddleBrown', 'Green', 'SandyBrown',
'SeaGreen', 'SeaShell', 'Sienna', 'Silver', 'SkyBlue', 'SlateBlue',
'SlateGray', 'SlateGrey', 'Snow', 'SpringGreen', 'SteelBlue', 'GreenYellow',
'Teal', 'Thistle', 'Tomato', 'Turquoise', 'Violet', 'Wheat', 'White',
'WhiteSmoke', 'Yellow', 'YellowGreen'
]
palette = [ImageColor.getrgb(_) for _ in STANDARD_COLORS]
Oprócz tego, przydadzą nam się dodatkowo 3 funkcję, które umożliwią konwersję współrzędnych bounding-boxów z postaci (xc, yc, w, h) do postaci (xmin, ymin, xmax, ymax) oraz ich przekształcenie do wartości bezwzględnych. Ostatnia z funkcji wykona wizualizację – narysuje na obrazie prostokąty i opisy obiektów wraz z dodatkowymi statystykami.
def box_cxcywh_to_xyxy(x):
x_c, y_c, w, h = x.unbind(1)
b = [(x_c - 0.5 * w), (y_c - 0.5 * h),
(x_c + 0.5 * w), (y_c + 0.5 * h)]
return torch.stack(b, dim=1)
def rescale_bboxes(out_bbox, size):
img_w, img_h = size
b = box_cxcywh_to_xyxy(out_bbox)
b = b.cuda() * torch.tensor([img_w, img_h, img_w, img_h], dtype=torch.float32).cuda()
return b
def plot_results(img, prob, boxes, palette, stat_text):
for p, (x0, y0, x1, y1) in zip(prob, boxes.tolist()):
cl = p.argmax()
color = palette[cl]
start_p, end_p = (int(x0), int(y0)), (int(x1), int(y1))
cv2.rectangle(img, start_p, end_p, color, 2)
text = "%s %.1f%%" % (CLASSES[cl], p[cl]*100)
cv2.putText(img,text, start_p, cv2.FONT_HERSHEY_SIMPLEX, 1, (0,0,0),10)
cv2.putText(img,text, start_p, cv2.FONT_HERSHEY_SIMPLEX, 1, color,2)
cv2.putText(img,stat_text, (100,100), cv2.FONT_HERSHEY_SIMPLEX, 1.6, (0,0,0),16)
cv2.putText(img,stat_text, (100,100), cv2.FONT_HERSHEY_SIMPLEX, 1.6, (255,255,255),6)
return img
Dane
Następnie pobieramy film, na którym będziemy pracować.
!wget https://archive.org/download/0002201705192/0002-20170519-2.mp4
Główna pętla
Z uwagi na fakt, że dane wejściowe mają postać filmu, wszystkie obliczenia wykonywane są w pętli while() od pierwszej do ostatniej klatki.
Przed jej rozpoczęciem tworzę katalog, w którym będę zapisywać wyniki oraz obiekt cv2.VideoCapture, który jako argument przyjmuje nazwę pliku.
Poza tym, chcemy indeksować wyniki i śledzić postęp obliczeń.
if not os.path.exists(detr_model_name):
os.makedirs(detr_model_name)
cap = cv2.VideoCapture('0002-20170519-2.mp4')
counter = 0
pbar = tqdm(total=45913+1)
Poniżej umieściłam cały kod głównej pętli.
while(cap.isOpened()):
ret, img = cap.read()
if img is None:
break
# scale + BGR to RGB
inference_size=(1920, 1080)
scaled_img = cv2.resize(img[:,:,::-1],inference_size)
# To PyTorch tensor on GPU
img_tens = transform(scaled_img).unsqueeze(0).cuda()
# Inference
t0=time.time()
with torch.no_grad():
output = model(img_tens)
t1=time.time()
prob_threshold = 0.7
probas = output['pred_logits'].softmax(-1)[0, :, :-1]
keep = probas.max(-1).values > prob_threshold
bboxes_scaled = rescale_bboxes(output['pred_boxes'][0, keep], (img.shape[1], img.shape[0]))
txt="Facebook DETR %s Threshold=%.2f Inference %dx%d GPU: %s Inference time %.3fs"%(detr_model_name, prob_threshold,inference_size[0],inference_size[1],torch.cuda.get_device_name(0),t1-t0)
result = plot_results(img, probas[keep], bboxes_scaled, palette, txt)
cv2.imwrite(os.path.join(detr_model_name, 'img%08d.jpg' % counter), result)
counter+=1
pbar.update(1)
del img; del img_tens; del result
cap.release()
Główna pętla – tym razem szczegółowo
Omówmy wszystkie elementy krok po kroku. Warunkiem zakończenia pętli jest przejście przez wszystkie klatki filmu.
while(cap.isOpened())
Najpierw wczytujemy obraz i sprawdzamy, czy zostało to wykonane poprawnie.
ret, img = cap.read()
if img is None:
break
Zmniejszamy rozmiar zdjęcia oraz konwertujemy go z przestrzeni BGR do RGB. Jest to konieczne, ponieważ do wczytania wykorzystaliśmy OpenCV, którgo domyślną reprezentacją jest następująca kolejność kanałów: Blue, Green, Red.
# scale + BGR to RGB
inference_size=(1920, 1080)
scaled_img = cv2.resize(img[:,:,::-1],inference_size)
Następnie konwertujemy obraz do postaci tensora z wykorzystaniem zdefiniowanych wcześniej przekształceń oraz przenosimy go na GPU.
# To PyTorch tensor on GPU
img_tens = transform(scaled_img).unsqueeze(0).cuda()
Teraz możemy w końcu wykonać inferencję – mierzę jej czas, żeby później uwzględnić tę informację na ostatecznym wyniku.
# Inference
t0=time.time()
with torch.no_grad():
output = model(img_tens)
t1=time.time()
Zmieniając wartość zmiennej prob_threshold, zmieniać nam się będzie liczba obiektów wykrytych na zdjęciach. Im mniejszy będzie próg, tym więcej obiektów uzyskamy – nie chcemy jednak ustawić go zbyt nisko, ponieważ uzyskamy wtedy też obiekty, których model nie jest do końca pewien – może się to więc bezpośrednio przełożyć na spadek jakości predykcji.
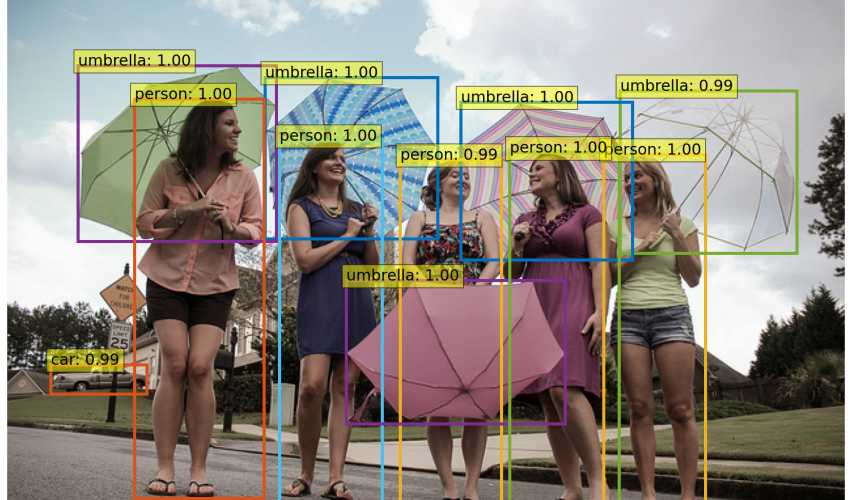
Poniżej możesz zobaczyć, co się dzieje, gdy wybierzemy zbyt niską wartość progu.

Korzystając z funkcji softmax, przekształcamy nasze wyniki do postaci powdopodobieństw z zakresu od 0 do 1, w której prawdopodobieństwa wszystkich klas dla danego obiektu sumują się do wartości 1. Nie chcemy wyświetlać ostatniej klasy (no object), dlatego pomijamy ostatni element wyniku.
prob_threshold = 0.7
probas = output['pred_logits'].softmax(-1)[0, :, :-1]
Chcemy jakoś przefiltrować nasze wyniki, czyli zostawić jedynie te obiekty, dla których prawdopodobieństwo jest większe niż prob_threshold. Możemy to zrobić poniższą linią kodu – zmienna keep zwiera współrzędne obiektów, które w dalszej kolejności wyświetlimy.
keep = probas.max(-1).values > prob_threshold
Teraz możemy przekształcić współrzędne naszych bounding-boxów do postaci, która później będzie łatwa do wykorzystania przy rysowaniu prostokątów – potrzebujemy współrzędnych lewego górnego i prawego dolnego narożnika.
Funkcja rescale_bboxes przyjmuje 2 argumenty: współrzędne prostokątów (w postaci współrzędnych środka oraz wysokości i szerokości obiektu) oraz rozmiar zdjęcia, na którym te prostokąty chcemy narysować.
Pierwszy argument znajduje się w wyniku modelu pod kluczem 'pred_boxes’ – wykorzystamy jedynie współrzędne tylko tych obiektów, dla których prawdopodobieństwo, było większe niż prob_threshold. Wykryte obiekty będziemy rysować na oryginalnym zdjęciu (przed zmniejszeniem), dlatego podajemy na wejście szerokość i wysokość img.
bboxes_scaled = rescale_bboxes(output['pred_boxes'][0, keep], (img.shape[1], img.shape[0]))
Teraz możemy przystąpić do rysowania interesujących nas rzeczy. Pierwsza z nich to statystyki dotyczące inferencji: nazwa modelu, wartość progu, rozmiar zdjęcia, model GPU oraz czas inferencji. Wszystko to kryje się w zmiennej txt. Ostateczny wynik, uzyskujemy dzięki funkcji plot_results, na wejście której podajemy: zdjęcie, na którym chcemy rysować (wspomniane wcześniej img), prawdopodobieństwa obiektów, przeskalowane prostokąty oraz zmienną txt.
Następnie zapisujemy zdjęcie w utworzonym wcześniej katalogu.
txt="Facebook DETR %s Threshold=%.2f Inference %dx%d GPU: %s Inference time %.3fs"%(detr_model_name, prob_threshold,inference_size[0],inference_size[1],torch.cuda.get_device_name(0),t1-t0)
result = plot_results(img, probas[keep], bboxes_scaled, palette, txt)
cv2.imwrite(os.path.join(detr_model_name, 'img%08d.jpg' % counter), result)
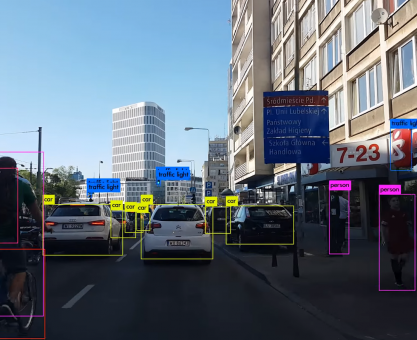
Jaką postać ma zapisane przez nas zdjęcie? Wynik dla pojedynczej klatki przedstawiłam poniżej.

Zanim przejdziemy do kolejnej klatki, musimy zwiększyć liczniki oraz po sobie posprzątać (usuwamy zdjęcia).
counter+=1
pbar.update(1)
del img; del img_tens; del result
Po wykonaniu się całej pętli, zwalniamy zasoby.
cap.release()
Jak uzyskać wynikowy film?
Jeśli udało Ci się przetworzyć wszystkie klatki, wystarczy, że z poziomu katalagu, w którym zapisywaliśmy wyniki, wywyołasz następujące polecenie.
ffmpeg -i img%08d.jpg movie.mp4
Linki
W ten sposób dotarliśmy do końca posta (i nanoserii). Poniżej podrzucam zebrane materiały, które pomogły mi napisać ten post. Możliwe, że któryś z nich zainteresuje i Ciebie!
- Pierwszy post z serii – DETR w segmentacji instancji
- Notebook, na którym pracowaliśmy
- Notebook od facebook-research dotyczący wykrywania obiektów
- Link do repozytorium DETR na GitHubie
- Link do publikacji DETR
- Link do filmu na YT, który pomógł mi przy pierwszej styczności z DETR
- Wpis o wykorzystaniu DETR do segmentacji instancji