W ramach pierwszego warsztatu lokalnej społeczności DataWorkshop Warszawa miałem okazję pokazać jak uruchomić wykrywanie obiektów w TensorFlow w Colabie i na własnym komputerze.
Wprowadzenie do przetwarzania obiektów
Witajcie na drugim spotkaniu lokalnej społeczności, na pierwszym warsztacie organizowanym przez społeczność.
Jest nas tutaj, z dwadzieścia kilka osób, najpierw na szybko wam wspomnę, kim jestem, natomiast to nie jest istotne tutaj dzisiaj. Zrobię krótkie wprowadzenie, jeśli chodzi o tą tematykę wykrywania obiektów. Będzie taki mini wykład, celujemy dzisiaj, żeby skupić się na tym praktycznym zastosowaniu, żeby uruchomić rzeczy i żeby po prostu być w stanie to uruchomić u siebie i ewentualnie wytrenować sobie własną sieć. Później uruchomimy to u siebie, będziemy mogli na zdjęciach, czy na filmie uruchomić wykrywanie obiektów. Planujemy przerwę. Potem będziemy oznaczać dane, przetestujemy, w jaki sposób można oznaczać dane samodzielnie, bo żeby wytrenować sieć neuronową do wykrywania obiektów, musimy te obiekty ręcznie oznaczyć. Więc wydaje mi się, że to jest coś o tyle fajnego, że warto poczuć to tak naprawdę, żeby zejść na ziemię, zobaczyć, jaka jest rzeczywistość, a potem możemy sobie tak naprawdę wymyślać, że potrzebujemy, nie wiem, sto tysięcy zdjęć, i kto te sto tysięcy zdjęć wyklika. A potem będziemy ćwiczyć, nie wiem, czy wszyscy sportowe stroje mają, ale będziemy ćwiczyć w chmurze, więc tutaj komputery nam się nie przemęczą.
Wszystkie ćwiczenia, uwaga, wszystko można zrobić dzisiaj albo w Colabie, w chmurze, albo na laptopie. Poza jedną rzeczą,
test na kamerze, nie? Czyli to, do czego potrzebujemy OpenCV. Czyli żeby uruchomić naszą kamerę i na widoku z naszej kamery wykrywać obiekty, więc to jest takie, powiedzmy, praktyczne zastosowanie, co możliwe będzie jedynie na lokalnym komputerze z kamerą. To tyle jeśli chodzi o plan.
Krótko o mnie
- prowadzę bloga https://deepdrive.pl, gdzie staram się zamieszczać rzeczy związane z samochodami autonomicznymi, deep learningiem i z robotyką mobilną
- W związku z tym blogiem mam też kanał na YouTube, gdzie tam jest parę filmów. Przez jakiś czas robiłem daily vloga, ale to na razie odłożyłem.
- Zajmuję się robotyką, brałem też udział w zawodach DARPY z robotem humanoidalnym, ale to są rzeczy mało związane z dzisiejszym tematem.
- Coś, co robię na co dzień, skanery laserowe, takie jak w samochodach autonomicznych obecnie. Tylko, że robot jest mniejszy, rozwija mniejsze prędkości.
- Na konferencji Data Workshop Conf 2018 mieliśmy pojazd, samochód w skali 1:10, to było już po zawodach, które wygraliśmy. Mamy samochód ze skanerem laserowym i chcieliśmy stosować sztuczną inteligencję, żeby samodzielnie jeździł. Natomiast ostatecznie stosujemy klasyczne rozwiązania.
- Miałem też doświadczenie w skali 1:1, gdzie mieliśmy już samochód wykorzystujący sieć neuronową. Wykorzystaliśmy sieć neuronową do segmentacji semantycznej, czyli mamy kamerę zamontowaną z przodu pod szybą. Uruchomiliśmy sieć, która dla każdego piksela przypisuje etykietę, czy jest to droga, czy coś innego, droga była dla nas kluczowa.

A dzisiaj będzie o wykrywaniu obiektów!

W zadaniu wykrywania obiektów chodzi o znalezienie prostokątów, które będą jak najdokładniej obrysowywać obiekt. Możemy sobie wyobrazić coś innego, możemy sobie wyobrazić segmentację instancji, gdzie chcemy otrzymać na przykład maskę, dokładny obrys obiektów. Inną rzeczą jest segmentacja semantyczna, mamy etykiety przypisane do pikseli. Wiemy, że to są samochody, ale nie wiemy, ile jest samochodów, bo to jest wszystko zlane. To jest po prostu jeden wielki obszar, który nam pokazuje, że tu są samochody. I teraz nowy trend, który właśnie jest połączeniem segmentacji instancji i segmentacji semantycznej,
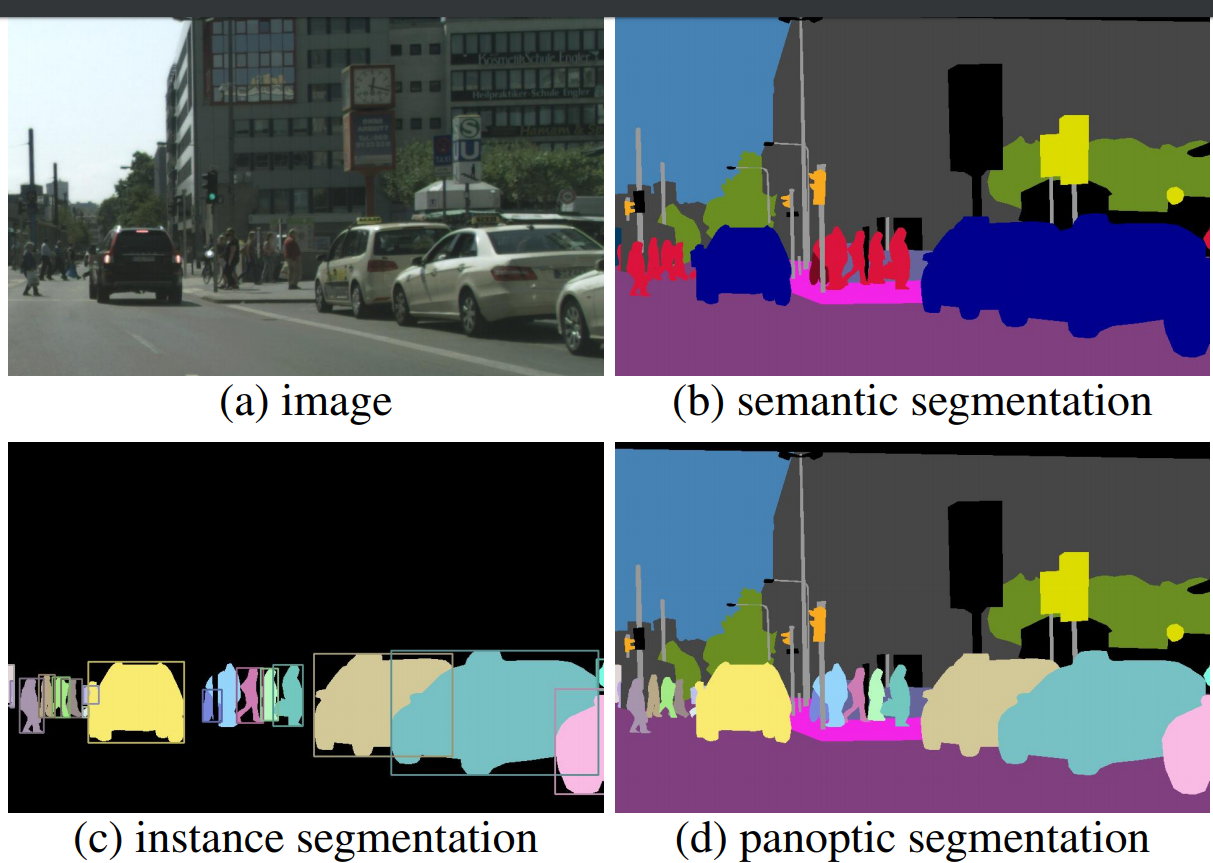
czyli panoptic segmentation, gdzie naszym wynikiem są maski wokół obiektów, obiekty są rozdzielone i jednocześnie mamy informacje o tle, niebo, drzewa, mamy rodzaje obiektów/rzeczy. Te, w których możemy wyszczególnić instancje oraz te w których nie jest to możliwe.

Czy jest wam znany zbiór danych ImageNet, ma już parę lat i służy do wytrenowania sieci neuronowej, żeby rozpoznawała obraz, żeby przypisywała nam etykietę do całego obrazu, czyli na przykład, miasto, kot, pies. No i jeżeli chodzi o historię głębokich sieci neuronowych to w 2012 tak naprawdę pojawił się przełom, gdzie mieliśmy pierwsze rozwiązanie właśnie w konkursie związanym z rozpoznawaniem obrazów ImageNet, na tym zbiorze. Pierwsze rozwiązanie, które wykorzystywało deep learning. To 2012, więc to już było parę lat temu. Od tego czasu systematycznie jest coraz lepiej. Biorąc pod uwagę błąd top-5, wykorzystując taką metrykę, percepcja ludzka jest poniżej 5% błędu. No i teraz mamy już lepsze wyniki za pomocą sieci neuronowych.

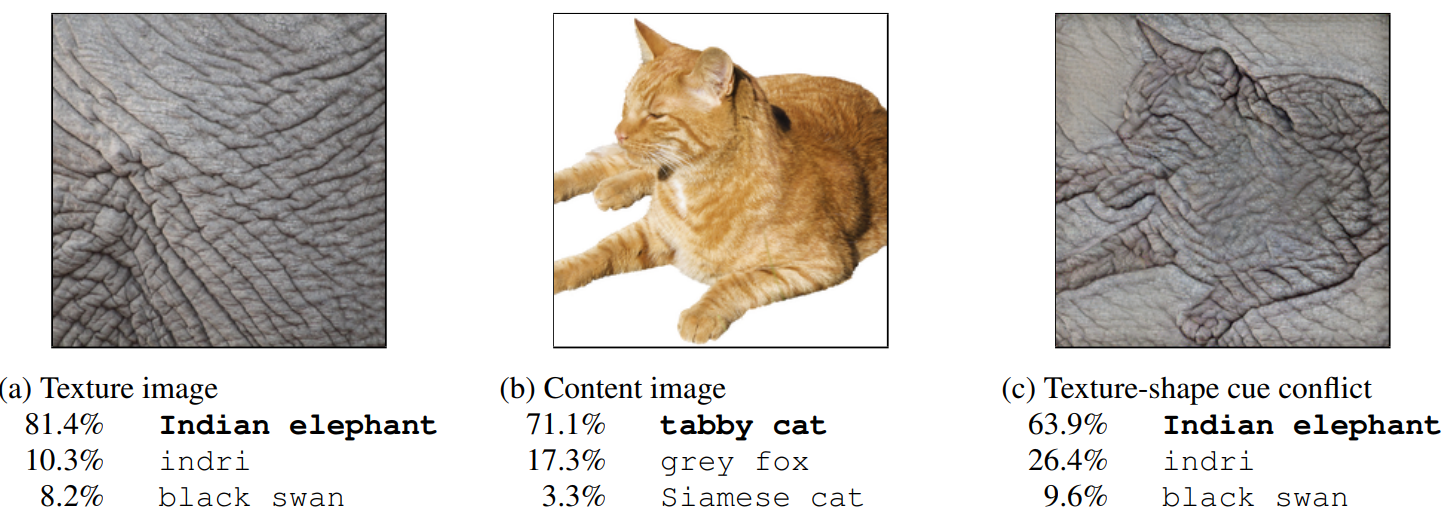
Okazuje się, że niekoniecznie konwolucyjne sieci neuronowe są dobre właśnie w tym zastosowaniu, bo reagują one najbardziej na teksturę. Więc jeżeli weźmiemy sobie teksturę słonia i weźmiemy sobie zdjęcie kota i zrobimy style transfer (czy znana jest ta technika?) gdzie przenosimy styl z jednego zdjęcia, na zdjęcie drugie, uzyskamy coś takiego, my jeszcze stwierdzimy, że tam jest kot, nie? To nas jeszcze jako ludzi nie oszukuje. Natomiast sieć neuronowa ma 64% pewności, że to jest słoń. Więc widzimy, że niby wyniki są dobre, natomiast okazuje się, że łatwo oszukać. Możemy do zbioru trenującego dodać dane, które są już zmienionym stylem.

ImageNet-trained CNNs are biased towards texture; increasing shape bias improves accuracy and robustness https://arxiv.org/abs/1811.12231
Żeby na podstawie takiego zdjęcia sieć neuronowa nauczyła się rozpoznawać, że to jest cały czas to samo. Tak to nazwę. Okay, no więc tu mówiliśmy właśnie o klasyfikacji. Inna rzecz, można do problemu klasyfikacji dodać problem klasyfikacji i lokalizacji.

Czyli zakładamy, że na zdjęciu jest jeden obiekt, tak jak tutaj na przykład kot, no i wtedy możemy sobie wyobrazić, że będziemy rozpoznawać, co jest na zdjęciu, plus będziemy rozpoznawać, gdzie to coś jest. Natomiast ten nurt, powiedziałbym, został wyparty przez rozpoznawanie wielu obiektów, bo jest to jednak takie bardziej praktyczne zagadnienie. Bo rzadko kiedy mamy, prawda, jeden obiekt, albo mamy pewność, że mamy jeden obiekt. No więc to, co będzie dzisiaj tematem, czyli rozpoznawanie obiektów, tak naprawdę możemy sobie, nikt nam nie zabroni, uruchomić też to wykrywanie masek i w zasadzie, kto będzie chętny to tam wystarczy zmienić jeden napis, nie? Na inny. Wybrać po prostu inny model z dostępnych modeli. I ten inny model będzie oprócz bounding boxów, oprócz tych ramek, dostarczał maski. Czyli będzie jedno i drugie. Bo na podstawie takiej maski jesteśmy w prosty sposób w stanie wyznaczyć bounding boxa, tam szukając po prostu najbardziej wystających elementów.

Konwolucyjne sieci neuronowe, tu mam fajną prezentację.
Wyobraźmy sobie filtr trzy na trzy, który będzie miał wartości, bo tutaj możemy sobie wybrać kernel. W sieci neuronowej, to te kernele nie są projektowane przez nas, one są wynikiem optymalizacji. Czyli tak naprawdę w procesie uczenia sieci neuronowej, czyli tej optymalizacji, te wagi, tak jak tutaj mamy 0, -1, 0 czy -5, -1,5, -1 i tak dalej, te dziewięć wag jest dobierane automatycznie, no i tak jak widzimy tutaj, mamy to jądro (kernel) tej konwolucji, takie, które powoduje wyostrzenie obrazu.
To jest jedna z rzeczy, które możemy zrobić. Możemy zrobić także wygładzenie.
Więc jeżeli ktoś by się zastanawiał a propos wymazywania twarzy z nagrania z warsztatu to możemy to zrobić tak naprawdę, bo wiedza dzisiaj tak naprawdę pozwoli na to, bo jeżeli chcielibyśmy wymazać wszystkie twarze z filmu to co musimy mieć? Wykrywanie twarzy? A wykrywanie twarzy to jest szczególne zastosowanie wykrywania obiektów, więc jeżeli byśmy sobie przygotowali zbiór albo po prostu ściągnęli z Internetu zbiór, który będzie miał oznaczone prostokątami twarze, my jesteśmy w stanie nauczyć sieć neuronową rozpoznawania twarzy, później zastosować tę sieć, żeby nam znalazła twarze na zdjęciu, na każdej klatce filmu, a my już sobie później wykorzystując taki kernel choćby, albo… czy ktoś oglądał „Czarne lustro”? odcinek White Christmas. Tam można było kogoś zablokować, wtedy mamy wykrywanie masek i ta osoba jest zamaskowana takim białym szumem:
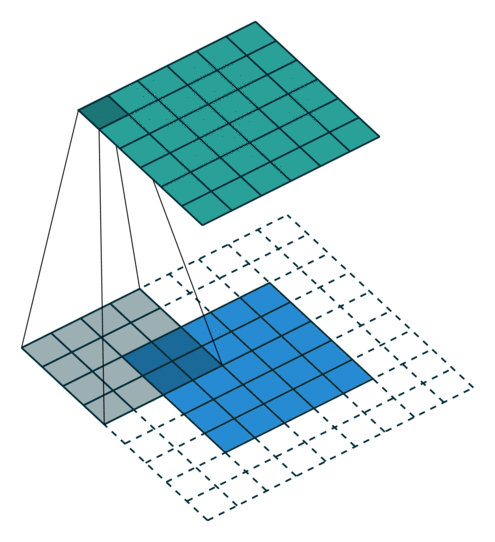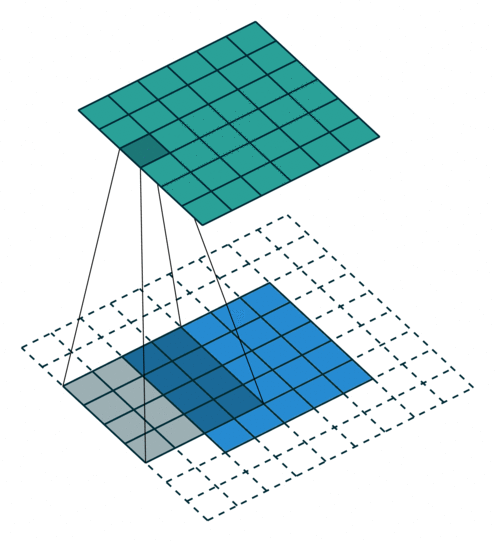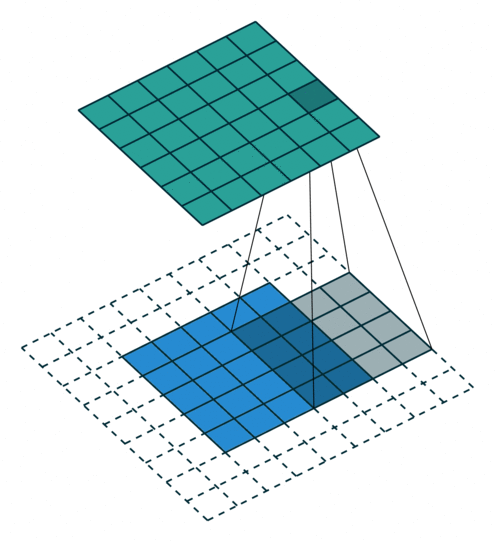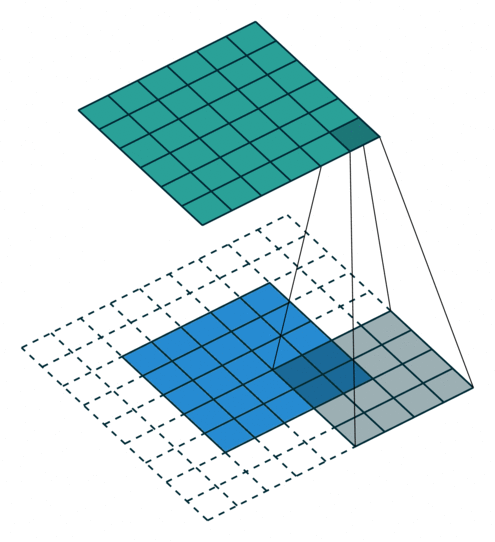
Konwolucja z kernelem 4×4, padding SAME
Jeżeli mamy filtr w konwolucji, tutaj przykład jest 4 na 4, raczej się spotyka nieparzyste, to idea jest taka, że jeżeli nasz obraz jest 5 pikseli na 5 pikseli, my robiąc konwolucję przechodzimy po tym obrazie skanując naszym filtrem i przemnażamy wartości filtra przez obraz i wynik sumujemy, wpisujemy sobie tam w odpowiednią kratkę. I tak naprawdę na tej podstawie możemy uzyskiwać różne rzeczy, np. krawędzie w jedną stronę, w drugą, blur, wyostrzanie i wiele innych.
Te wiele innych to jest to, co robi sieć neuronowa w tym procesie uczenia.
Jak robiliśmy to kiedyś? Kiedyś ludzie siedzieli i po prostu zastanawiali się, jakie dobrać cechy albo jakie dobrać właśnie takie wykrywanie krawędzi i tak dalej, co zrobić, żeby na podstawie obrazów być w stanie jak najlepiej wykryć obiekty.
W tym momencie uważam, że już trochę za dużo konwolucji, ale ostatni przykład.

Jeżeli zwiększymy sobie obraz do pokaźnych rozmiarów to co się okazuje? Okazuje się, że nic innego nie mieści się już na ekranie.

Jeśli chodzi o te konwolucyjne sieci neuronowe to już jest taki przykład już klasyczny na MNIST’ie, czyli zbiorze danych z cyframi od 0 do 9 i co? Możemy wstawić warstwy konwolucyjne, mamy cztery filtry, z których każdy jest 5 na 5. Bierzemy cztery konwolucje 5 na 5 i przetwarzamy nasz obraz, uzyskujemy cztery nowe obrazy, które tam są 28 na 28, z uwagi na krawędź, poza którą nie wystaje nasz filtr. Co możemy później zrobić? Zmniejszyć wielkośc obrazu. Mamy następną konwolucję i znowu podział na 4 (dwukrotnie w x i dwukrotnie w y). Możemy wykorzystać max pooling, gdzie na wejściu mamy 2 na 2 pixele, czyli bierzemy sobie każde 4 piksele i z nich bierzemy maksimum. W max poolingu to jest to właśnie maksimum. Możemy sobie też wyobrazić, że bierzemy średnią, albo minimalną wartość. Ta minimalna, maksymalna to zależy trochę od naszego case’u, bo jeżeli nasze obrazy są takie jak tutaj to biorąc maksimum będzie więcej białego niż czarnego. Trzeba czasem uważać na to. Jeżeli będziemy brać minimum to będzie więcej czarnego niż białego i tak dalej. Chodzi o to, że zamieniamy nasz obraz, który ma akurat w tym przypadku, jedną warstwę, bo jest to czarno-biały obraz. Może być oczywiście obraz RGB, wtedy mamy trzy warstwy, czerwony, zielony, niebieski.

Czyli zamiast naszych warstw RGB, czy w tym przypadku po prostu jednej warstwy mamy, dwanaście warstw dla tych tam 5 na 5 pikseli i to są nasze cechy, które uzyskaliśmy z obrazu. I na ich podstawie możemy robić klasyfikację.
A do klasyfikacji to możemy wykorzystać sieci neuronowe albo machine learning. Chodzi o to, że najniższe warstwy w praktyce to wykrywają krawędzie. Potem warstwa wyżej już rozpoznaje na przykład narożniki. I inne cechy. To wszystko na podstawie konwolucji. Konwolucja 5 na 5 nie jest wydajna i lepiej zastosować dwie konwolucje 3 na 3 pod rząd. Intuicja jest taka, że na początku wykrywamy małe cechy, potem większe, a na końcu stwierdzamy, co jest na obrazie. Jeśli chodzi o wykrywanie obiektów – jak porównać dwie ramki, oczekiwaną i predykcję sieci neuronowej? Możemy policzyć to biorąc przecięcie dwóch zbiorów, czyli część wspólną i dzielimy ją przez sumę zbiorów.

Na szczęście znalazłem w Internecie na stronie Apple’a przykładowe wartości. Gdy mamy pokrycie 95% to wygląda to mniej więcej tak jak na rysunku z prawej strony. Warto zwrócić uwagę ile to jest to 35%.
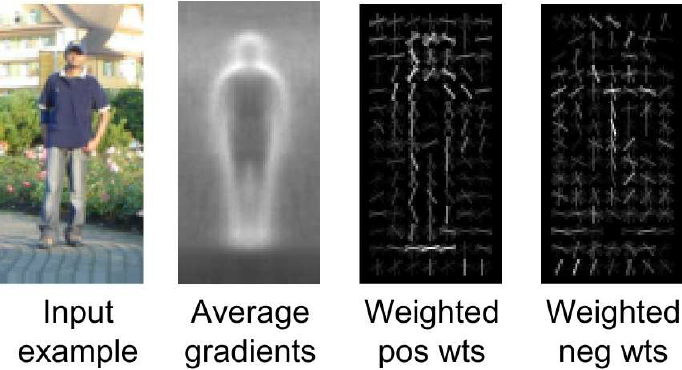
A więc jak to się robiło w 2005? Wykrywanie obiektów? No stwierdzono, że jeżeli podzielimy obraz na małe prostokąty i w ramach tych małych prostokątów sprawdzimy, jakie są gradienty, możemy sobie to wyświetlić w ten sposób jak wyżej, to okazuje się, że średni kształt człowieka na obrazie wygląda w charakterystyczny sposów. Na tej podstawie możemy wnioskować, tworzyć systemy rozpoznawania.

Jeśli chodzi o dalszą rozwój wykrywania obiektów to w 2012 pojawiła się technika polegająca na tym, że grupujemy piksele podobnego koloru i na tej podstawie wykrywamy obiekty. W zależności od skali grupowania uzyskujemy wykrycia różnych obiektów w zależności od wielkości. Okazuje się, że to jest dobry sposób uzyskania pierwszych prostokątów w miejscach, gdzie mogą być obiekty. Jest to lepsze niż zastosowanie brute force’a, techniki sliding window, w której skanujemy obraz określonej wielkości prostokątem i analizujemy co w nim się znajduje.

Co gdyby wziąć te propozycje, około 2000 propozycji? I każdą z nich trochę ścisnąć, zmiażdżyć, żeby uzyskać kwadrat i wyznaczyć cechy za pomocą sieci neuronowej, takiej na przykład wytrenowanej na ImageNecie albo wytrenowanej na naszym własnym zbiorze. Okazuje się, że faktycznie, można potem sklasyfikować, co to jest. To nawet działa, natomiast analiza jednego zdjęcia trwa długo, nawet 50 sekund. Tak to działało, wybieramy regiony, liczymy konwolucje, a potem klasyfikację i ewentualne poprawki pozycji bounding boxa.
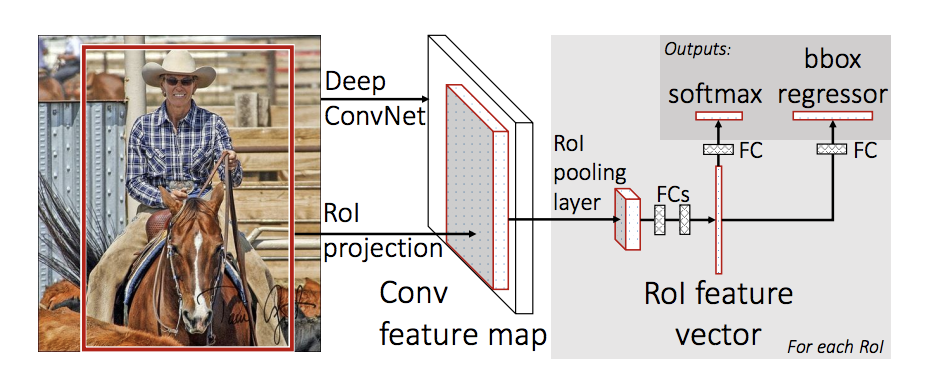
W 2015 stwierdzono, że jeżeli mamy liczyć 2000 razy konwolucję dla tego samego obrazu i czasem w pokrywających się miejscach, to czemu by nie zrobić tego najpierw, raz, przed wyznaczeniem bounding boxów? Tak powstało Fast RCNN. Przygotowujemy najpierw wszystkie cechy dla całego obrazu i bierzemy tę samą metodę do propozycji bounding boxów. Ta zmiana powoduje, że jest 25 razy szybciej.

Faster RCNN (2016)
Przydałoby się, żeby to jeszcze szybciej działało. Okazuje się, że to co jest najwolniejsze to właśnie metoda do wyznaczania propozycji bounding boxów. Została ona zamieniona na sieć neuronową, która proponuje bounding boxy. Czyli scenariusz wygląda następująco, najpierw wyznaczamy cechy dla całego obrazu, a później mamy sieć neuronową, która proponuje, gdzie mogą być obiekty. Na końcu jest klasyfikator, który decyduje co tam jest.

https://pjreddie.com/darknet/yolo/
Później w 2015 pojawiło się YOLO. Polecam autora, polecam ostatni jego artykuł a propos trzeciej wersji YOLO. Jest prześmiewczy. W wersji 3, to było w 2018, to już naprawdę szybko działa, natomiast tym się dzisiaj nie zajmiemy, bo nie jest to wspierane w TensorFlow. Widziałem pare osób, które próbowały to przenieść. Jest to przeniesione, ale nie do TensorFlow object detection API, z czego będziemy dzisiaj korzystać.

Tutaj była zupełnie inna strategia, bo wszystko od razu się działo, jako jedna sieć neuronowa, czy ja chcę się tutaj zagłębiać? Nie.
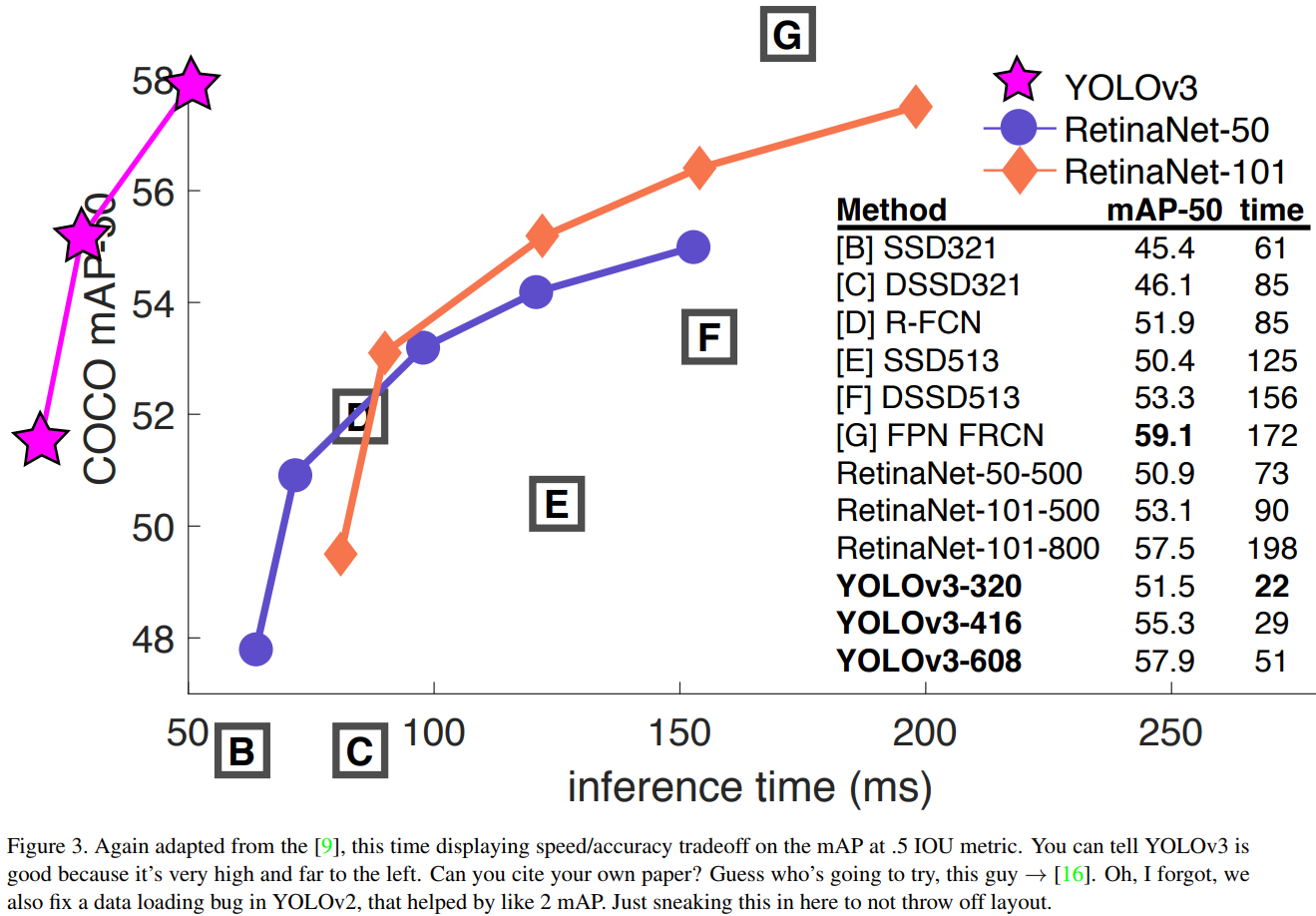
https://arxiv.org/pdf/1804.02767.pdf
Artykuł, który cytuje sam siebie, Wikipedię, także dobre żarty są, może hermetyczne, ale wciąż. To czym będziemy się dziś zajmować to jest sieć SSD z 2016r. Natomiast my jeszcze tak naprawdę będziemy używać nowszej wersji, 2018. Ale w skrócie, o co chodzi?
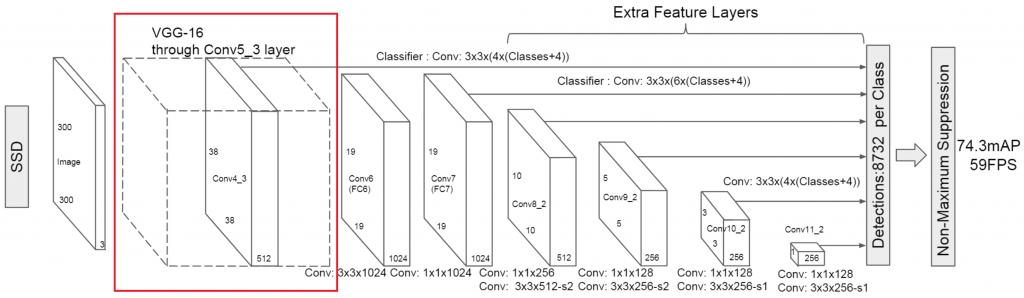
https://arxiv.org/pdf/1512.02325.pdf
Jako backbone mamy tutaj sieć VGG 16, to jest sieć, która służy do rozpoznawania obrazów, czyli to jest to poprzednie zagadnienie, gdzie mamy po prostu obraz na wejściu i klasyfikujemy. Bierzemy warstwy z takiej sieci i potem dobudowujemy różne konwolucyjne warstwy i z których idą informacje do klasyfikatora na końcu. Na końcu mamy 8700 propozycji bounding boxów dla każdej klasy. W 2018 została dodana pewna ciekawa rzecz. Zamienion zwykłe konwolucje, na separowalne konwolucje. Idea jest taka, że zamiast brać z obrazu wejściowego wszystkie warstwy, działamy tylko w jednej warstwie, więc mamy tutaj tyle samo warstw. I dlatego robimy konwolucję trzy na trzy, a potem sobie tu robimy konwolucję 1 na 1, ale już taką normalną.
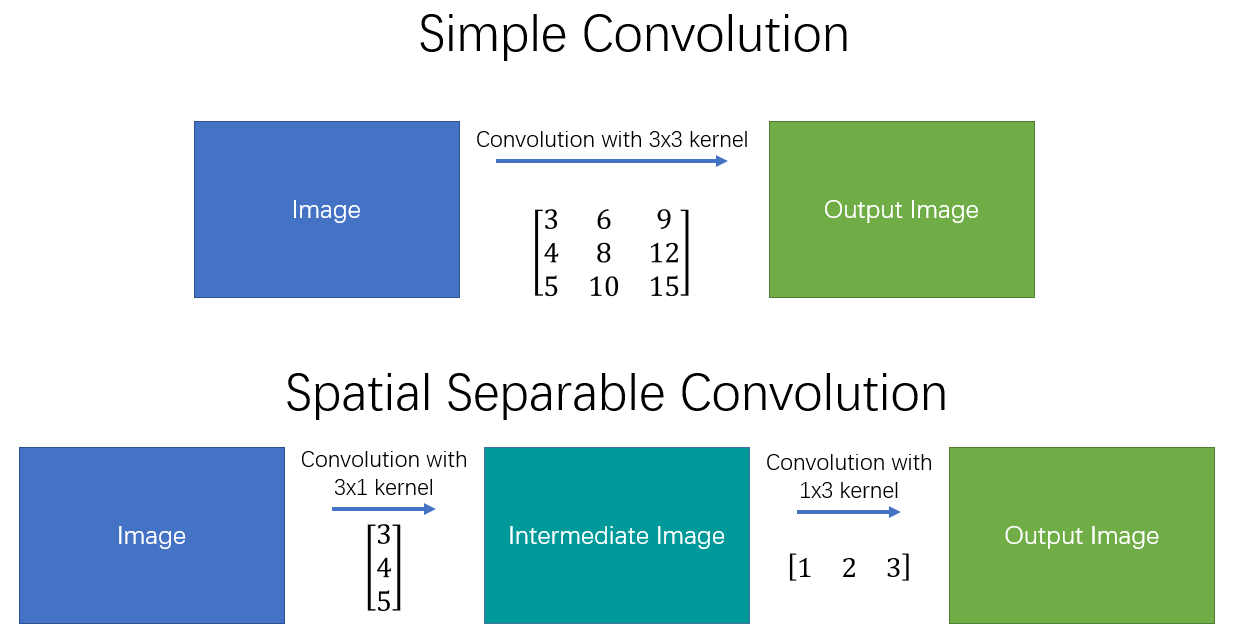
Metody wykrywania obiektów
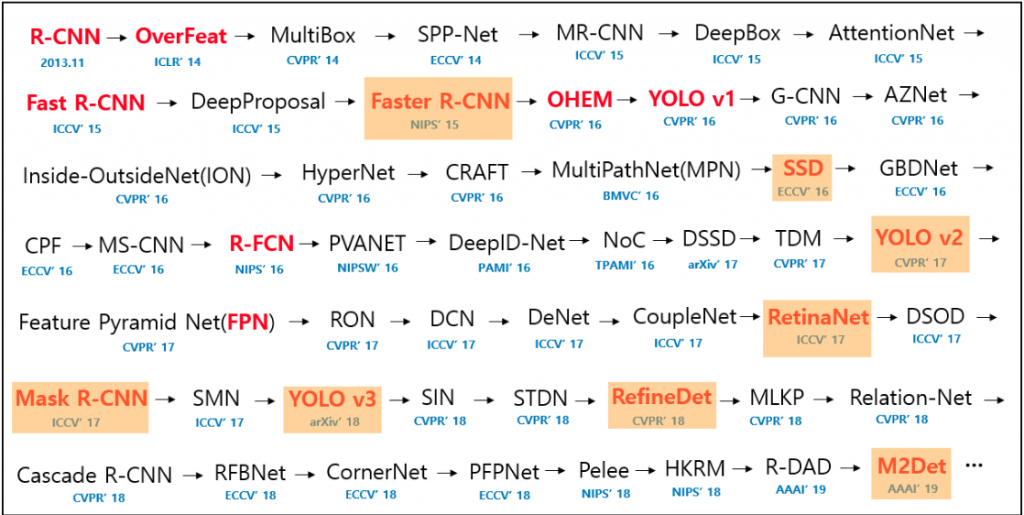
+ moja modyfikacja, a co
Dla tych pomarańczowych filmy znajdziesz tu: https://www.youtube.com/karolmajek
Polecam w ogóle taką mapę, tak bym to nazwał, gdzie mamy wszystkie rozwiązania, od 2013 do 2019 i na czerwono są zaznaczone te, które są bardziej rewolucyjne. Te na pomarańczowo można znaleźć wśród filmów, które udostępniam na YouTube. Tam po prostu widać, jakie wyniki daje dana sieć.
Tworzymy własny zbiór danych
LabelImg

Jest oprogramowanie, które pozwala nam etykietować, oznaczać, adnotować obrazy, gdzie możemy po prostu, mając nasz zbiór 100 000 obrazów, na każdym obrazie stwierdzić gdzie są obiekty. Tutaj Windows wygrywa, bo wystarczy po prostu ściągnąć plik .exe i potem klikamy dwa razy bez zająknięcia. Sprawdzałem na jednym komputerze, na próbce jeden, i stwierdzam, że jest dobrze, więc tak naprawdę wszelkie problemy mogą nastąpić.
OpenCV CVAT

Natomiast jest drugi program się przyda jeżeli mamy do czynienia z filmami, więc mamy filmy zamiast zdjęć. Nie będziemy przecież każdej klatki w tym samym miejscu zaznaczać, jeżeli obiekt porusza się powoli, skoro możemy mieć możliwość na przykład przeskoczenia o dziesięć klatek, sto i tak dalej i w międzyczasie możemy poprosić o interpolację. Tu następuje pokaz jak korzystać z oprogramowania.
To teraz przejdziemy do tej części praktycznej, ja po prostu usiądę i będziemy robić. Wszyscy gotowi?
Część praktyczna – Wykrywanie obiektów w TensorFlow
Proszę wyszukać TensorFlow Models. TensorFlow Models, to jest takie repozytorium, które polecam przeeksplorować we własnym zakresie, bo tam można znaleźć naprawdę wiele interesujących rozwiązań. Po wyszukaniu TensorFlow Models klikam pierwszy link, jak to zawsze. TensorFlow Models na Githubie jak sobie spojrzymy, mamy oficjalne modele, research, samples i tutoriale. Trzeba kliknąć w research i w tych modelach researchowych już mamy wiele rzeczy. Na przykład bardzo fajna rzecz, audio set, który jest kompletnie niezwiązany z tematyką dzisiejszą, natomiast możemy sobie analizować dźwięk. Jest tutaj wiele różnych rzeczy, naprawdę polecam, autoencodery, no dosłownie wszystko. Deeplab polecam, w deeplabie jest segmentacja semantyczna, o której tam dzisiaj wspominaliśmy, a my zajmiemy się object_detection. Przewijamy na dół, bo na dole mamy treść z pliku readme, czyli naszą instrukcję. Tu mamy przykładowe wykrycia obiektów, co już napawa nas optymizmem, że może jesteśmy w stanie też takie wyniki osiągnąć. Przewijamy do spisu treści.
Instalacja
Instalacja, jest bardzo ważna i to od niej należy zacząć
https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/installation.md
Przejdziemy do zakładki instalacja. Biblioteka TensorFlow jest oczywistym wymaganiem, musimy mieć ją zainstalowaną. Tu jest informacja jak można ją zainstalować https://www.tensorflow.org/install. Ja u siebie mam wersję z GPU, bo mam kartę graficzną Nvidia’i na pokładzie. Jeżeli masz specjalne środowisko do TensorFlow (poprzez Anaconda’ę, albo VirtualEnv) uruchamiasz je w konsoli, a w środowisku wywołujesz polecenie, które zainstaluje niezbędne pakiety:
pip install Cython contextlib2 pillow lxml jupyter matplotlib
Krok 2 to instalacja COCO API – możesz to pominąć jeśli nie planujesz uczyć sieci. Uruchom poniższe polecenia z katalogu models/research:
git clone https://github.com/cocodataset/cocoapi.git cd cocoapi/PythonAPI make cp -r pycocotools ../../
Krok 3 to kompilacja z wykorzystaniem protobuf. Pobierz protoc w wersji na swój system (dla Windows to wersja nie nowsza niż 3.4.0) ze strony https://github.com/protocolbuffers/protobuf/releases/tag/v3.4.0. Dla linuxa pobierz plik o nazwie protoc-3.4.0-linux-x86_64.zip, dla Windowsa protoc-3.4.0-win32.zip. Rozpakuj w wygodnym miesjcu (pulpit?). Teraz uruchom poniższe polecenie po zmodywikowaniu ścieżki: (Na Windowsie może być trzeba odwrócić ukośniki)
/home/karol/Desktop/protobuf340/bin/protoc object_detection/protos/*.proto --python_out=.
Polecenie niczego nie wypisuje jeśli się powiedzie!
Aby móc korzystać z API do wykrywania obiektów z dowolnego miejsca dodajemy ścieżki do pakietów do zmiennej PYTHONPATH.
Na Linuxie z katalogu models/research:
echo export PYTHONPATH=\$PYTHONPATH:`pwd`:`pwd`/slim >> ~/.bashrc
Na Windowsie należy zmienną środowiskową dodać we Właściwościach systemu.
Otwieramy nowy terminal (włączamy środowisko jeśli mamy) i uruchamiamy poniższe polecenie z katalogu models/research, aby przetestować czy wszystko działa:
python object_detection/builders/model_builder_test.py
Tak wygląda przykładowy wynik:
WARNING: The TensorFlow contrib module will not be included in TensorFlow 2.0. For more information, please see: https://github.com/tensorflow/community/blob/master/rfcs/20180907-contrib-sunset.md https://github.com/tensorflow/addons If you depend on functionality not listed there, please file an issue. …………s… Ran 16 tests in 0.046s OK (skipped=1)
Jesteśmy gotowi by przejść dalej i wreszcie wykrywać obiekty na zdjęciach i filmie!
Uruchamiamy wykrywanie
Mamy quickstart, pokazuje jak wykorzystać sieci neuronowe już gotowe. Na tym będziemy się wzorować. Przejdźmy od razu do extrasów gdzie pierwszą rzeczą jest TensorFlow detection model zoo. Mamy tu gotowe modele, które możemy wykorzystać do naszych aplikacji. Jeśli przewiniemy odpowiednio w dół znajdziemy wytrenowane modele na zbiorze COCO (http://cocodataset.org), które jest wciąż bardzo popularny. Jest tam osiemdziesiąt klas ponumerowanych od 1 do 90. Polecam zajrzeć na stronę http://cocodataset.org/#explore jest tam przeglądarka gdzie możemy wybrać np. znak stopu i ławkę. I proszę bardzo, są jakieś przykłady. Zdarza się że znak stopu jest np. na autobusie. Przy okazji widzimy, jaka jest dokładność tych adnotacji z maskami. To oznaczali ludzie i wynikają z tego pewne ograniczenia.
Sieci wytrenowanych na zbiorze COCO mamy w ZOO całe mnóstwo. Większość z nich służy do wykrywania obiektów. W ostatniej kolumnie tabeli mamy informację jakie jest wyjście z sieci, czy są to bounding boxy czy maski. W tym tutorialu interesują nas bounding boxy, maski pozostają dla odważnych, zadziałają one przy wykonaniu tych samych kroków. W drugiej kolumnie tabeli mamy informację o czasie predykcji na jednej karcie graficznej (GeForce Titan X). Będziemy korzystać z modelu SSD Lite który wykonuje predykcje w 27 milisekund i ma średnią precyzję dla wszystkich klas 22%. Nie jest to 50%, pamiętamy rysunek u góry? To jest niski wynik, natomiast dotyczy średniej z wszystkich klas. I jest to wynik najlepszy w najkrótszym czasie, bo jeżeli weźmiemy sobie inną sieć neuronową np. Faster R-CNN NASNet, która potrzebuje aż dwie sekundy na jedno zdjęcie, i otrzymujemy 43%.
Ściągamy SSD Lite MobileNet V2 do naszego ulubionego katalogu
Dygresja a propos wersji TensorFlow
W pewnym momencie podjęto decyzję, że trzeba przerobić TensorFlow Object Detection API na nową wersję, wykorzystującą estymatory w TensorFlow. Stało się to w wersji 1.11, może wcześniej. Pojawiła się kompletnie nowa wersja frameworku, która już nie pozwala trenować sieci neuronowych na wielu kartach graficznych i nie pozwala trenować na wielu komputerach. Co jest oczywistą wadą. Jeżeli trenujemy wykrywanie obiektów to mając nawet cztery karty graficzne to dobrze, jak to się trenuje kilka dni. Także są obecnie dwie wersje, TensorFlow Object Detection API. Jedną wersją jest wersja legacy i z niej będziemy tutaj korzystać, właśnie z uwagi na to, że ona ma te dodatkowe funkcjonalności pozwalające potem wytrenować nam model na wielu komputerach, czy wielu kartach graficznych na jednym komputerze, po prostu wpisując prosty parametr do uruchomienia, co jest w ogóle wspaniałe. Jeśli chodzi o przejście na nowe API, to specjalnie problemu nie ma, jest po prostu nieco inna składnia do wywołania polecenia. Poza tym nic się nie zmienia, datasety zostają, wszystko zostaje tylko inaczej uruchamiamy polecenie python train.py i są inne nazwy parametrów, nie jest to duży kłopot. W TensorFlow 2.0, nie będzie można uruchomić tego legacy API.
Wykrywanie obiektów na filmie
Quickstart: Jupiter notebook for off-the-shelf inference
Spojrzymy na Quickstart: Jupiter notebook for off-the-shelf inference. Na podstawie tego kodu stworzymy kod, który na naszym komputerze będzie działał z kamerą. Czy masz niezaklejoną kamerę w laptopie? Spójrzmy na tego notebooka tutaj na GitHubie:
Spojrzymy szybko na ten kod widzimy, że wymaga TensorFlow 1.12. Kod importuje biblioteki, ściąga model i uruchamia go dla kilku przykładowych zdjęć. Możemy ten kod uruchomić na naszym komputerze (mamy go, bo przecież pobraliśmy całe repozytorium). Otwórz konsolę i przejdź do katalogu models/research/object_detection/ po czym uruchom jupyter-notebook object_detection_tutorial.ipynb
Do pierwszej komórki dodajemy:
import cv2
Na końcu notebooka podłączymy się do kamery lub pliku z filmem np. mp4:
cap = cv2.VideoCapture(0) # 0 - 1st camera, 1 - 2nd camera, ...
# cap = cv2.VideoCapture('video.mp4') # or path to filename
Mamy przygotowane źródło danych, teraz uruchomimy predykcję w pętli. Nie skorzystamy z funkcji pokazanej w notebooku, bo funkcja wykonuje za każdym razem kilka czynności które możemy wykonać raz i dzięki temu przyspieszyć wykrywanie obiektów. Na podstawie notebooka możemy stworzyć osobny skrypt, który jest w linku poniżej.
Kompletny kod jest tutaj:
http://bit.ly/tfodapicv2
Myślałem, że tutaj coś jeszcze napiszę, ale nie dam rady, a bardzo chcę ten wpis udostępnić. Zachęcam do obejrzenia filmów, widać na nich ile jest problemów po drodze, są też anegdoty i dodatkowa wiedza. Dużo wyciąłem. Wpis powstał na bazie transkrypcji wykonanej przez Natalię Zaborniak, której chciałbym gorąco podziękować!
Przeżyliśmy, mimo problemów.