W pierwszej części tej serii udało nam się poznać sposoby ekstrakcji cech wizualnych z dźwięku i dowiedzieć się na co uważać w problemach audio jeśli do tej pory mieliśmy do czynienia tylko z wizją. Pozostaje jednak jeszcze jedna kwestia do porównania – próg wejścia.
W mojej opinii, wizja komputerowa jest niekwestionowanym faworytem pod względem dostępności materiałów, modeli, danych, problemów i wszystkich innych rzeczy, które są potrzebne, aby dziedzina uczenia głębokiego dynamicznie się rozwijała. Często problemy wizyjne są wybierane w pierwszej kolejności przez początkujących, a przygotowanie pierwszej wersji modelu w popularnych problemach wizyjnych to już często kwestia godzin, a nie miesięcy.
W tym artykule sprawdźmy więc:
- jak łatwo zbudować jest klasyfikator zdarzeń dźwiękowych korzystając z reprezentacji wizualnych?
- jak szybko można przygotować aplikację webową do klasyfikacji i wizualizacji cech audio?
Problem: klasyfikacja zdarzeń dźwiękowych
Klasyfikacja zdarzeń dźwiękowych jest jednym z najbardziej podstawowych zadań w audio. W angielskiej nomenklaturze, zadanie to dzieli się tak naprawdę na 2 różne zadania i czasem obu tych zwrotów używa zamiennie:
- audio tagging – w tym zadaniu dostajemy na wejściu plik audio i mamy za zadanie przewidzieć globalne klasy (lub klasę), których dźwięk słyszymy na nagraniu,
- sound event detection – w tym zadaniu musimy przewidzieć jakie klasy są w nagraniu i gdzie dokładnie.
W takim ujęciu zadania te można porównać odpowiednio do wizyjnej klasyfikacji i detekcji obrazu.
Dane: ESC-50
ESC-50 (skrót od Environmental Sound Classification) jest zbiorem danych odpowiadającym problemowi klasyfikacji (audio tagging). Jest to jeden z najpopularniejszych zbiorów do klasyfikacji dźwięku typu multi-class single label. Ma on też polski akcent – jego twórcą jest Polak, dr Karol Piczak, aktualnie wykładający na Uniwersytecie Jagiellońskim.
Zbiór ten zawiera 50 klas, w każdej klasie jest dokładnie po 40 5-sekundowych przykładów i podzielony jest na 5 foldów do walidacji krzyżowej, więc tak naprawdę przygotowywać będziemy 5 modeli, po jednym per fold.
Dane ze względu na mały rozmiar znajdują się na GitHubie i można je pobrać klonując repozytorium pod tym linkiem.
Model: Transfer Learning z OpenL3
W związku z tym, że celem tego artykułu jest sprawdzić jak szybko jesteśmy w stanie przygotować i wdrożyć pierwszą wersję klasyfikatora, najprościej oprzeć się na gotowym modelu i zastosować transfer learning.
I tu pojawia się haczyk – modeli do reprezentacji audio jest jeszcze relatywnie niewiele i na pewno nie jest to paleta, którą można porównać do tej z wizji komputerowej czy NLP. Najbardziej popularnym modelem jest jednak tzw. OpenL3 i to z niego będziemy korzystać.
Reprezentacja cech
Nazwa L3 pochodzi od tytułów kilku publikacji, w których rozwijany był model, tj. “Look, Listen and Learn”. Dokładna wersja, z której będziemy korzystać trenowana była na zbiorze audio-video AudioSet udostępnionym przez Google.
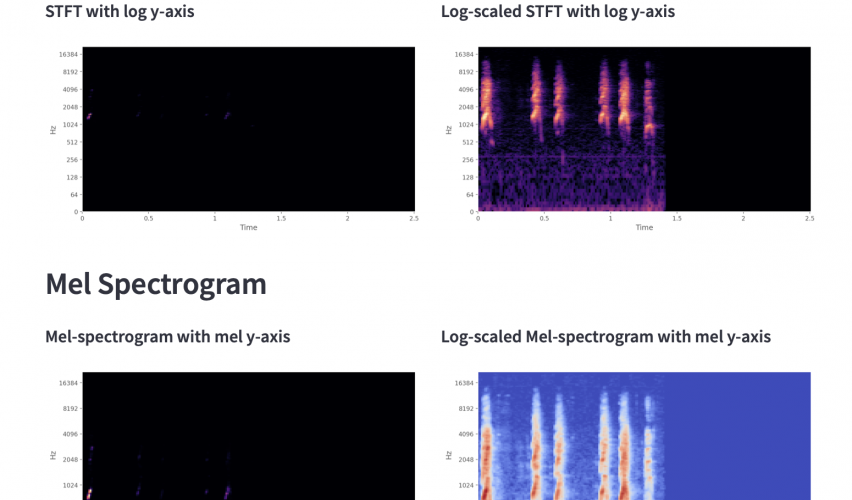
Model trenowany był w ramach self-supervised learning i używał jako zadania problemu korespondencji – z plików wideo wybierany był fragment audio i sekwencja obrazów, a zadaniem modelu było przewidzieć czy fragmenty te pochodzą z tego samego miejsca w wideo. Jako reprezentacja audio używany był log-scaled mel-spectrogram, a zatem zarówno oś Y jak i sama magnituda (czyli wartości spectrogramu) były transformowane względem logarytmu. Po wytrenowaniu modelu, część zajmująca się procesowaniem audio do przestrzeni embeddingów była odcinana, tak aby reprezentacje te można wykorzystać w innych zadaniach związanych już tylko z dźwiękiem.
W projekcie korzystałam z implementacji OpenL3 w PyTorch, tj. torchopenl3.
Transfer Learning
Po wyliczeniu reprezentacji każdą z nich standaryzujemy ich średnią i odchyleniem standardowym, a następnie wyliczamy model dla każdego z foldów.
Zdecydowałam się na bardzo prosty i mały model (ze względu na mały rozmiar danych):
| Warstwa | Parametry |
|---|---|
| Linear | 256 |
| Batch Norm | 256 |
| Leaky ReLU | 0.1 |
| Dropout | 0.5 |
| Linear + Softmax | 50 |
i torch summary:
===
Layer (type:depth-idx) Param #
=================================================================
├─Sequential: 1-1 --
| └─Linear: 2-1 131,328
| └─BatchNorm1d: 2-2 512
| └─LeakyReLU: 2-3 --
| └─Dropout: 2-4 --
| └─Linear: 2-5 12,850
├─MetricCollection: 1-2 --
| └─Accuracy: 2-6 --
├─MetricCollection: 1-3 --
| └─Accuracy: 2-7 --
=================================================================
Total params: 144,690
Trainable params: 144,690
Non-trainable params: 0
=================================================================
Model był trenowany z wykorzystaniem Adama (lr=0.001) i trenowany był przez 150 epok. Wynik?
| Fold | Accuracy |
|---|---|
| 1 | 0.7675 |
| 2 | 0.75 |
| 3 | 0.7775 |
| 4 | 0.79 |
| 5 | 0.7825 |
| Średnia | 0.7735 |
Oraz podstawowe wykresy z tensorboard:

Jak widać pierwszy strzał jest całkiem niezły i wynik nie odbiega od wyliczonego na zbiorze wyniku dla człowieka, czyli 81.3%.
W związku z tym, że artykuł skupia się na przygotowaniu tzw. wersji 1, poniżej zachęcam do sprawdzenia poniższych sugestii, żeby zobaczyć czy jesteśmy w stanie podnieść jakość modelu (lekko parafrazując to co mówiono mi na studiach – zadanie pozostawiam czytelnikowi :)):
- zmiana rozmiaru embeddingu – aktualnie używany jest mniejszy embedding (512), ale jest też dostępny większy (6144),
- zmiana pochodzenia danych – aktualnie używany jest OpenL3 trenowany na środowiskowych dźwiękach z AudioSet, ale można też sprawdzić wersję trenowaną ma muzycznych dźwiękach (wynik może Was zaskoczyć),
- zmiana architektury sieci – model nie osiąga pełni swoich możliwości na zbiorze treningowym, co mogłoby świadczyć, że jest lepsza architektura odpowiednia do tego zadania,
- a co za tym idzie – hyperparameter tuning pewnie by tutaj nie zaszkodził, żeby zoptymalizować swoje wyniki,
- i w końcu najważniejsze – augmentacja danych. Nie ma co się oszukiwać, że 2000 przykładów, z czego tak naprawdę tylko 1600 jest użwanych jednorazowo do treningu jest bardzo małą próbką, więc wszelkie augmentacje mogłyby być tutaj wskazane.
Budowa i wdrożenie aplikacji webowej ze Streamlit
Streamlit to biblioteka Pythona, która, powołując się na słowa autorów, ma za zadanie “przetworzyć skrypty w aplikacje webowe w minuty, wszystko w Pythonie, za darmo i bez doświadczenia z front-endem”.
Dla mnie początkowo brzmiało to jak słodka obietnica, która nie jest pewnie prawdziwa – i tu się pomyliłam, co za chwilę zobaczycie sami.
Zacznijmy od planu aplikacji. Przede wszystkim chcemy umożliwić użytkownikowi:
- upload jego własnego pliku audio w formacie .wav,
- wyświetlenie mu wykresów fali, STFT (+ log wartości) oraz mel-spectrogram (+ log wartości),
- a co za tym idzie – wybór parametrów tej transformaty,
- pokazanie mu wyniku klasyfikacji.
Streamlit pozwala nam na podstawową manipulację layoutem aplikacji, tj. możemy umieszczać komponenty zarówno na pasku bocznym, na głównym ekranie, a także dzielić główny ekran na kolumny. Ponadto, z perspektywy komponentów tekstowych, mamy do wyboru szerokie spektrum począwszy od zwykłego tekstu po predefniowane nagłówki, możemy też umieścić składnię Markdown czy Latex.
Dodawanie komponentów odbywa się trywialnie prosto poprzez wywoływanie streamlit.<komponent>, np. streamlit.file_uploader, streamlit.header czy streamlit.selectbox. Np. całość odczytu pliku audio do tablicy NumPy, wraz z informacją taką jak częstość próbkowania, zajmie nam nie więcej niż 3 linie:
uploaded_file = st.file_uploader("", type="wav")
if uploaded_file is not None:
audio, sample_rate = sf.read(uploaded_file)
Dodatkowo, Streamlit w bardzo prosty sposób łączy się z bibliotekami Pythona do wizualizacji danych, co pozwala na rysowanie wykresów w aplikacji bez konieczności uczenia się nowego API. Przykładem może być prostota w rysowaniu wykresu razem z Matplotlib:
fig = plt.figure(figsize=(10, 5)) display.waveplot(audio, sr=sample_rate) st.pyplot(fig=fig)
(display pochodzi z biblioteki do audio o nazwie Librosa i pozwala na rysowanie wykresów na canvas Matplotlib)
Pełny kod aplikacji można zobaczyć tutaj.
Ale chyba najciekawszą częścią całej zabawy ze Streamlit był proces deploymentu aplikacji. Streamlit pozwala na założenie bezpłatnego konta z nielimitowaną liczbą publicznych aplikacji, co jest bardzo przydatne jeśli chcemy się podzielić naszymi projektami do portfolio lub innymi projektami, z których korzystamy publicznie.
Po założeniu konta, przy założeniu, że nasze repozytorium z kodem jest na GitHub, cały deployment odbędzie się w dosłownie kilku krokach.
Repozytorium
Na repozytorium muszą znaleźć się co najmniej 3 pliki:
- requirements.txt – plik zawierający listę zależności Pythona, których potrzebujemy,
- packages.txt – plik zawierający listę zależności systemowych, których potrzebujemy,
- plik z aplikacją Streamlit.
Panel Streamlit
Po zalogowaniu się do naszego panelu zarządzania aplikacjami od razu natrafimy na przycisk dodania nowej aplikacji. Wybieramy opcję “z istniejącego repozytorium”.

Następnie zostaniemy poproszeni o uzupełnienie gdzie dokładnie znajduje się aplikacja – w tym celu dodamy link do repozytorium, nazwę gałęzi, z której chcemy korzystać oraz nazwę pliku.

W tym samym panelu możemy też wybrać ustawienia zaawansowane, gdzie wybrać można wersję Pythona czy dodać różne zmienne środowiskowe, które mają pozostać ukryte (np. klucze do API).
Po kliknięciu deploy czeka na nas przemiła wizualizacja, w której dowiemy się, że nasza aplikacja właśnie się piecze – będziemy mieli też dostęp do logów, żeby zweryfikować czy cała instalacja odbywa się poprawnie i czy czegoś nam nie brakuje.

Efekt końcowy?
Aplikacja
Na starcie aplikacji czeka na nas prośba o załadowanie pliku.

Ponadto możemy na pasku bocznym ustawić parametry, które potrzebujemy do przeliczenia wykresów.

Po załadowaniu pliku pojawi nam się kilka elementów:
- odtwarzacz pliku

- wykres samej fali

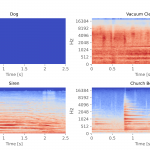
- 4 wykresy cech, których nauczyliśmy się w części 1 artykułu

- oraz samo pole z wynikiem klasyfikacji, który możemy modyfikować pod kątem liczby klas do wyświetlenia.

A wszystko w mniej niż 150 liniach kodu.
Podsumowanie
Choć audio pod kątem różnorodności pretrenowanych modeli czy łatwości ich obsługi jeszcze bardzo odbiega od wizji komputerowej, jak widać dosyć łatwo wytrenować model do postawionego problemu i stworzyć aplikację od A do Z. Podobne narzędzia są już również oferowane do bardziej złożonych, multimodalnych problemów związanych z audio np. ASR (automatic speech recognition), jak chociażby biblioteki Hugging Face.
To co nie pozostawia wątpliwości to fakt, że audio, choć często traktowane bardziej po macoszemu niż inne dziedziny, coraz dynamiczniej się rozwija i będzie grało coraz istotniejszą rolę w wykorzystaniu metod uczenia głębokiego – chociażby ze względu na potencjalne nasycenie innych dziedzin.
Jeśli więc interesujesz się wizją i szukasz sposobu na odróżnienie się od innych – może audio jest Twoim rozwiązaniem jako coś bliskiego wizji? 🙂
Źródła:
- Streamlit docs
- Pytorch Lightning docs
- Gyanendra Das, Humair Raj Khan, Joseph Turian (2021). torchopenl3 (version 1.0.0). DOI 10.5281/zenodo.5168808, https://github.com/torchopenl3/torchopenl3