Szybko, bo do końca maja 2020 można korzystać z AWS DeepRacer za darmo***, w symulacji, w chmurze! Jeśli masz konto w AWS to całość uruchomisz w 15 minut, a pierwsze wyniki zobaczysz w pół godziny.
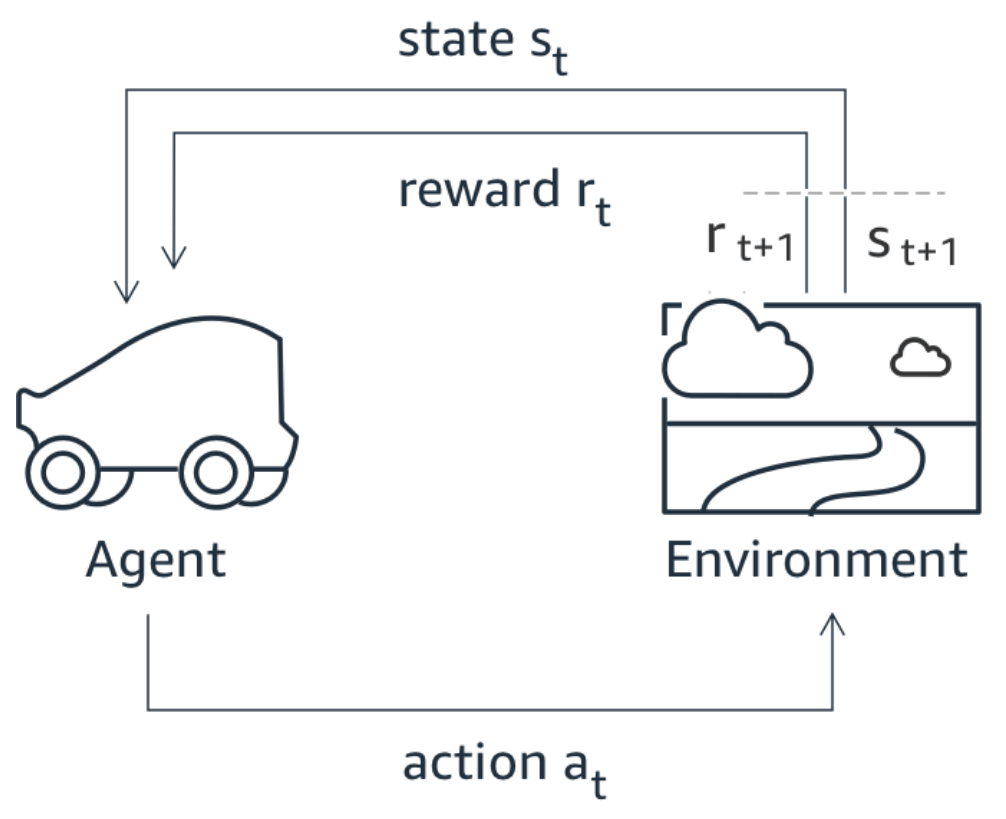
Samochód jest sterowany przez sieć neuronową, do nauki której wykorzystywane jest uczenie nienadzorowane (Reinforcement Learning). Oznacza to, że nie istnieje zbiór danych z poprawnymi etykietami, a sieć uczona jest w kolejnych eksperymentach w symulatorze. Odbywa się to poprzez interakcję agenta czyli naszego pojazdu z otoczeniem czyli trasą. Za wykonywanie poprawnych ruchów, sterowanie w poprawny sposób, sieć podczas uczenia otrzymuję nagrodę. Ta nagroda może być zależna od różnych czynników takich jak:
- odległość od środka jezdni
- znajdowanie się na konkretnym pasie, bądź środku drogi
- kąt względem kierunku drogi
- czy koła są na torze?
- prędkość
- wartość kąta skrętu kierownicy
- itd.
Tu zaczyna się prawdziwa zabawa, bo to my definiujemy funkcję nagrody w tym procesie. Musimy przygotować funkcję, która na podstawie aktualnego stanu samochodu i środowiska, zwróci jedną wartość – nagrodę. Ta nagroda zdecydowanie wpłynie na zachowanie się pojazdu. Jeżeli będziemy premiować niskie wartości kąta skrętu może się okazać, że nasz pojazd nie pokona zakrętów, natomiast gdy zbytnio nagrodzimy za prędkość, pojazd może nie zwolnić na zakręcie.
Oprócz definicji funkcji nagrody naszym zadaniem jest dobór hiperparametrów – parametrów procesu uczenia sieci takich jak:
- Gradient descent batch size – 64 [32, 64, 128, 256, 512]
- Entropy – 0.01 [0, …, 1]
- Discount factor – 0.999 [0, …, 1]
- Loss type – Huber [MSE, Huber]
- Learning rate – 0.0003 [1e-8, …, 1e-3]
- Number of experience episodes between each policy-updating iteration – 20 [5, …, 100]
- Number of epochs – 10 [3, …, 10],
- Maximum time 60 [5, …, 1440 minutes (24h)]
Dobór funkcji nagrody oraz odpowiedniej kombinacji hiperparametrów jest nie lada sztuką, dlatego też AWS podaje wartości domyślne, które pozwolą Ci uzyskać pierwsze wyniki.
Wymagania sprzętowe
Brak! Całość dzieje się w chmurze, więc o ile masz dostęp do Internetu i aktualną przeglądarkę wszystko powinno Ci się udać!
Jak zacząć?
Wystarczy, że wejdziesz na stronę AWS DeepRacer i tam wykonasz 4 kroki:
- Ustawienie ról w AWS – wystarczy nacisnąć guzik i samo się skonfiguruje [5 minut]
- Opcjonalnie możesz obejrzeć materiał o uczeniu nienadzorowanym [10 minut]
- Wprowadzenie do RL
- O symulatorze i dostępnych parametrach
- Przykłady funkcji nagrody
Pierwszy model
Tak wygląda domyślny kod funkcji nagrody który otrzymasz:
def reward_function(params):
'''
Example of rewarding the agent to follow center line
'''
# Read input parameters
track_width = params['track_width']
distance_from_center = params['distance_from_center']
# Calculate 3 markers that are at varying distances away from the center line
marker_1 = 0.1 * track_width
marker_2 = 0.25 * track_width
marker_3 = 0.5 * track_width
# Give higher reward if the car is closer to center line and vice versa
if distance_from_center <= marker_1:
reward = 1.0
elif distance_from_center <= marker_2:
reward = 0.5
elif distance_from_center <= marker_3:
reward = 0.1
else:
reward = 1e-3 # likely crashed/ close to off track
return float(reward)
Dostępne parametry
Wszystkie dostępne parametry możesz znaleźć na stronie:
https://docs.aws.amazon.com/deepracer/latest/developerguide/deepracer-reward-function-input.html
{
"all_wheels_on_track": Boolean, # flag to indicate if the agent is on the track
"x": float, # agent's x-coordinate in meters
"y": float, # agent's y-coordinate in meters
"closest_objects": [int, int], # zero-based indices of the two closest objects to the agent's current position of (x, y).
"closest_waypoints": [int, int], # indices of the two nearest waypoints.
"distance_from_center": float, # distance in meters from the track center
"is_crashed": Boolean, # Boolean flag to indicate whether the agent has crashed.
"is_left_of_center": Boolean, # Flag to indicate if the agent is on the left side to the track center or not.
"is_offtrack": Boolean, # Boolean flag to indicate whether the agent has gone off track.
"is_reversed": Boolean, # flag to indicate if the agent is driving clockwise (True) or counter clockwise (False).
"heading": float, # agent's yaw in degrees
"objects_distance": [float, ], # list of the objects' distances in meters between 0 and track_length in relation to the starting line.
"objects_heading": [float, ], # list of the objects' headings in degrees between -180 and 180.
"objects_left_of_center": [Boolean, ], # list of Boolean flags indicating whether elements' objects are left of the center (True) or not (False).
"objects_location": [(float, float),], # list of object locations [(x,y), ...].
"objects_speed": [float, ], # list of the objects' speeds in meters per second.
"progress": float, # percentage of track completed
"speed": float, # agent's speed in meters per second (m/s)
"steering_angle": float, # agent's steering angle in degrees
"steps": int, # number steps completed
"track_length": float, # track length in meters.
"track_width": float, # width of the track
"waypoints": [(float, float), ] # list of (x,y) as milestones along the track center
}
Znajdziesz tam również przykłady funkcji nagrody np. uwzględniające następne waypointy.
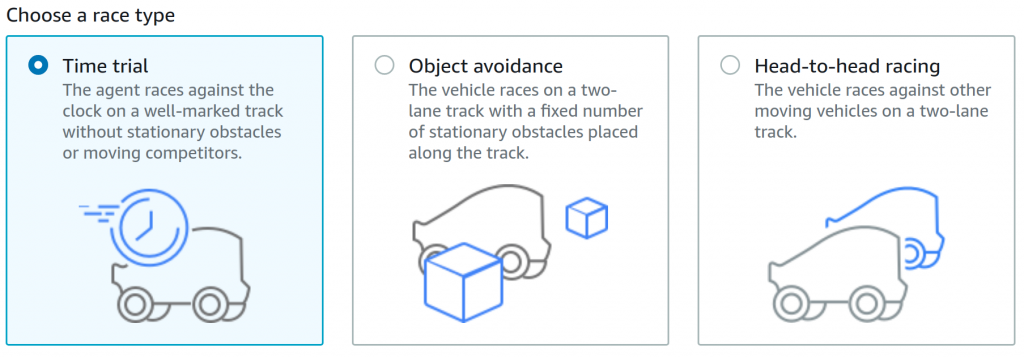
Dostępne rodzaje wyścigów
W symulacji możesz wybrać jeden z trzech rodzajów wyścigów i polecam zacząć od pierwszego z nich. Dostępny jest przejazd na czas, gdzie celem jest osiągnięcie najkrótszego czasu przejazdu oraz dwa trudniejsze scenariusze czyli omijanie przeszkód statycznych na torze oraz omijanie przeszkód dynamicznych – czyli innych jeżdżących pojazdów.
Funkcje nagrody w Time Trial
Utrzymanie się na trasie
Poniżej AWSowa funkcja która pozowli pojazdowi utrzymać się na trasie. Jest jeszcze prostsza niż domyślna. Nagroda równa jeden jest zwracana gdy wszystkie koła są na drodze i pojazd jest blisko środka drogi +/-5cm.
def reward_function(params):
'''
Example of rewarding the agent to stay inside the two borders of the track
'''
# Read input parameters
all_wheels_on_track = params['all_wheels_on_track']
distance_from_center = params['distance_from_center']
track_width = params['track_width']
# Give a very low reward by default
reward = 1e-3
# Give a high reward if no wheels go off the track and
# the agent is somewhere in between the track borders
if all_wheels_on_track and (0.5*track_width - distance_from_center) >= 0.05:
reward = 1.0
# Always return a float value
return float(reward)
Podążanie za środkiem drogi
To jest domyślna funkcja którą zobaczysz po utworzeniu nowego modelu. Tutaj sytuacja jest nieco bardziej skomplikowana – mamy trzy znaczniki ustawione na 10%, 25% i 50% szerokości całej drogi i sprawdzamy jak daleko od środka drogi pojazd się znajduje i nagradzamy odpowiednio.
def reward_function(params):
'''
Example of rewarding the agent to follow center line
'''
# Read input parameters
track_width = params['track_width']
distance_from_center = params['distance_from_center']
# Calculate 3 markers that are at varying distances away from the center line
marker_1 = 0.1 * track_width
marker_2 = 0.25 * track_width
marker_3 = 0.5 * track_width
# Give higher reward if the car is closer to center line and vice versa
if distance_from_center <= marker_1:
reward = 1.0
elif distance_from_center <= marker_2:
reward = 0.5
elif distance_from_center <= marker_3:
reward = 0.1
else:
reward = 1e-3 # likely crashed/ close to off track
return float(reward)
Po prostu się nie rozbij
To moja ulubiona nagroda od AWS, kompletnie nie zagwarantuje Ci wygranej natomiast jest prosta w implementacji 🙂 Pojazd otrzymuje nagrodę 1 jeśli się wciąż nie rozbił. Wyjechanie z trasy na określony czas (zdaje się 5s) powoduje restart z trasy.
def reward_function(params):
'''
Example of no incentive
'''
# Always return 1 if the car does not crash
return 1.0
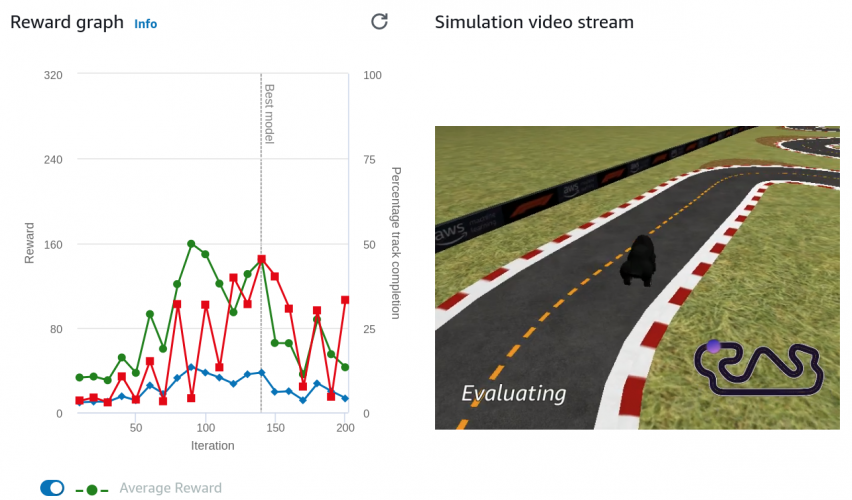
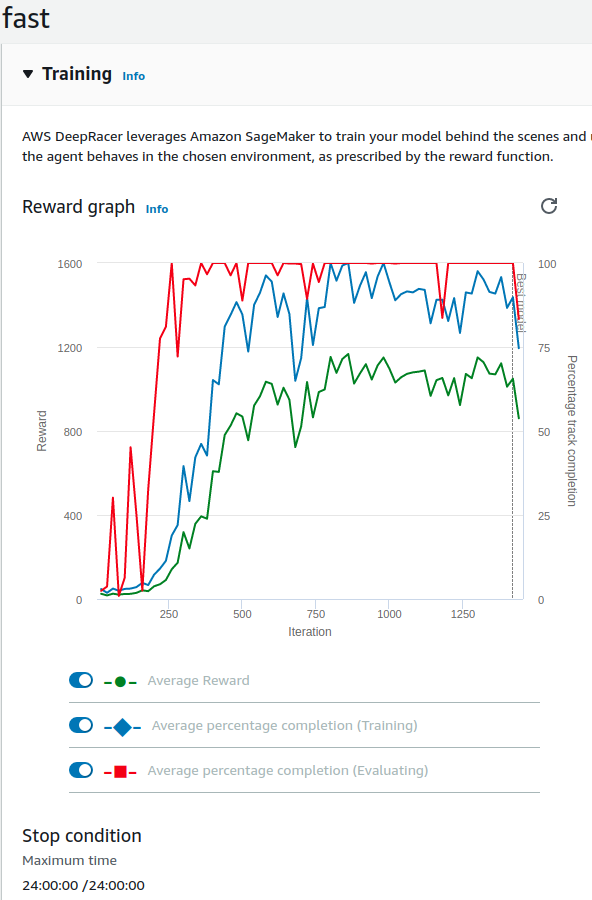
Mój obecnie najlepszy model
Zajmuje 80 miejsce z 433, więc nie zaskakuje za bardzo. Osiąga czas 03:06.939 podczas gdy obecnie najlepszy to 01:30.097. Model nagradza bardzo za prędkość (e^speed * speed^3), zmniejsza nagrodę gdy pojazd próbuje skręcać, oraz zmniejsza nagrodę gdy pojazd nie jedzie do następnego waypointu, gdy kierunek się nie zgadza. Jest tu błąd w kodzie – abs(dir_from_here_to_next) powinien być przed normalizacją zakresu, no ale poszło i się wytrenowało. Poniżej film i kod.
def reward_function(params):
'''
Karol: modelname - fast
'''
import math
# Read input parameters
track_width = params['track_width']
distance_from_center = params['distance_from_center']
track_width = params['track_width']
steering = params['steering_angle'] # Only need the absolute steering angle
all_wheels_on_track = params['all_wheels_on_track']
progress=params['progress']/100.0
is_reversed=params['is_reversed']
is_offtrack = params['is_offtrack']
speed=params['speed']
x=params['x']
y=params['y']
waypoints = params['waypoints']
closest_waypoints = params['closest_waypoints']
heading = params['heading']
# Calculate the direction of the center line based on the closest waypoints
next_point = waypoints[closest_waypoints[1]]
prev_point = waypoints[closest_waypoints[0]]
dir_from_here_to_next = math.atan2(next_point[1] - y, next_point[0] - x)
dir_from_here_to_next = math.degrees(dir_from_here_to_next)
if dir_from_here_to_next > 180:
dir_from_here_to_next = 360 - dir_from_here_to_next
dir_from_here_to_next=abs(dir_from_here_to_next)
if is_reversed or is_offtrack or not all_wheels_on_track:
return 1e-3
# Steering penality threshold, change the number based on your action space setting
ABS_STEERING_THRESHOLD_1 = 1
ABS_STEERING_THRESHOLD_2 = 5
# Give a very low reward by default
reward = 1e-3 + math.exp(speed) * speed * speed * speed
if abs(steering) < ABS_STEERING_THRESHOLD_2 and abs(steering)>ABS_STEERING_THRESHOLD_1:
reward *= 0.9
if abs(steering)>ABS_STEERING_THRESHOLD_2:
reward *= 0.7
if dir_from_here_to_next>1 and dir_from_here_to_next<5:
reward *= 0.7
if dir_from_here_to_next>5:
reward *= 0.3
return float(reward)
Oraz wykorzystane wartości hiperparametrów:
- Gradient descent batch size 512
- Entropy 0.01
- Discount factor 0.999
- Loss type Huber
- Learning rate 0.0003
- Number of experience episodes between each policy-updating iteration 20
- Number of epochs 10
- Time 1440 minutes
Podsumowanie
Koniecznie daj znać czy bierzesz udział, na którym jesteś miejscu, jaki jest Twój nick! Jeśli chcesz się podzielić swoją przygodą to koniecznie zapraszam!
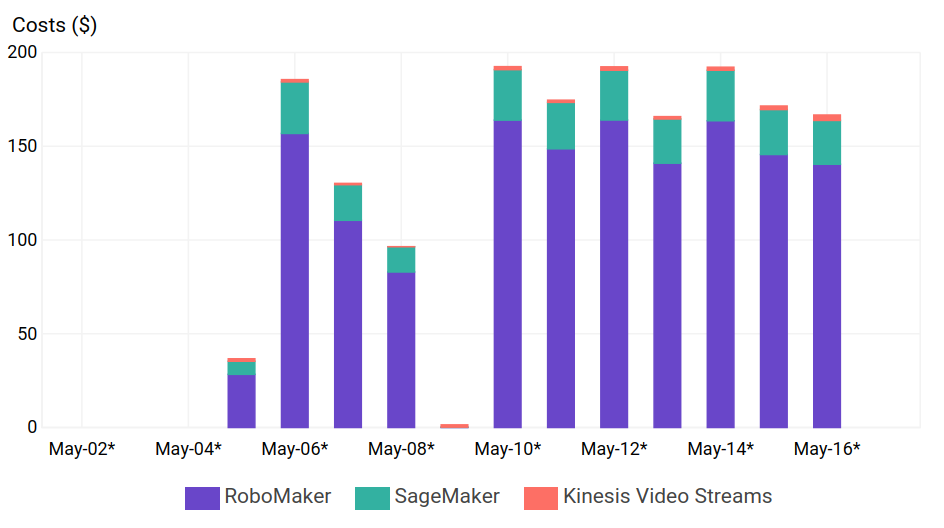
darmo ***
we provide credits to cover the first seven hours of usage. This is enough to train your first model, evaluate it, tune it, and then enter it into the AWS DeepRacer League. At the end of the first month that you use AWS DeepRacer, your account will receive the following service credits: 65 Simulation Unit hours ($26) for AWS RoboMaker, 10 hours of training ($5.57) on an ML.C4.2XL Amazon SageMaker instance, and $1.50 to cover Amazon S3, Amazon Kinesis Video Streams, and Amazon CloudWatch costs. The service credits will be loaded at the end of the month, will be valid for a month, and will be visible on your billing statement.